 视觉新范式Transformer之ViT的成功
视觉新范式Transformer之ViT的成功
这是一篇来自谷歌大脑的paper。这篇paper的主要成果是用Transformer[1]取代CNN,并证明了CNN不是必需的,甚至在大规模数据集预训练的基础上在一些benchmarks做到了SOTA,并且训练时使用的资源更少。
图像分块
要将图片分块是因为Transformer是用于NLP领域的,在NLP里面,Transformer的输入是一个序列,每个元素是一个word embedding。因此将Transformer用于图像时也要找出word的概念,于是就有了这篇paper的title:AN IMAGE IS WORTH 16X16 WORDS,将一张图片看成是16*16个“单词”。
inductive biases
在机器学习中,人们对算法做了各种的假设,这些假设就是inductive biases(归纳偏置),例如卷积神经网络就有很强的inductive biases。文中做了一个实验,在中等大小数据集训练时,精度会略逊色于ResNets。但是这个结果也是应该预料到的,因为Transformer缺少了CNN固有的一些inductive biases,比如平移不变性和局部性。所以当没有足够的数据用于训练时,你懂的。但是恰恰Transformer就强在这一点,由于Transformer运算效率更高,而且模型性能并没有因为数据量的增大而饱和,至少目前是这样的,就是说模型性能的上限很高,所以Transformer很适合训练大型的数据集。
ViT
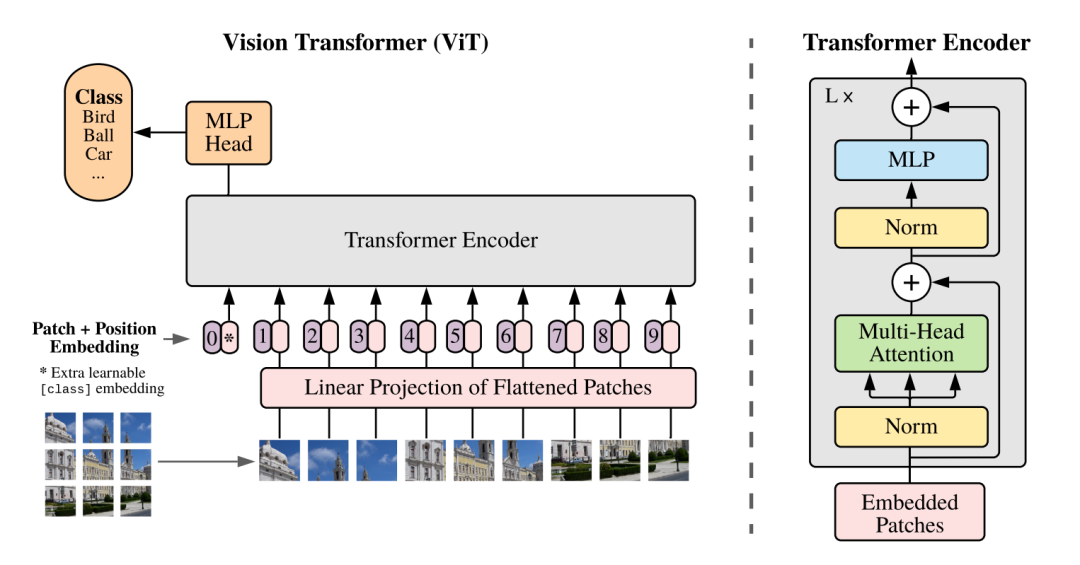
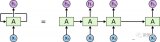
在ViT中,模型只有Encoder的,没有Decoder,因为只是用于识别任务,不需要Decoder。
首先按照惯例,先把图像的patch映射成一个embedding,即图中的linear projection层。然后加上position embedding,这里的position是1D的,因为按照作者的说法是在2D上并没有性能上的提升。最后还要加上一个learnable classification token放在序列的前面,classification由MLP完成。
Hybrid Architecture。模型也可以是CNN和Transformer的混合,即Transformer的输入不是原图像的patch,而是经过CNN得到的feature map的patch。
实验结果
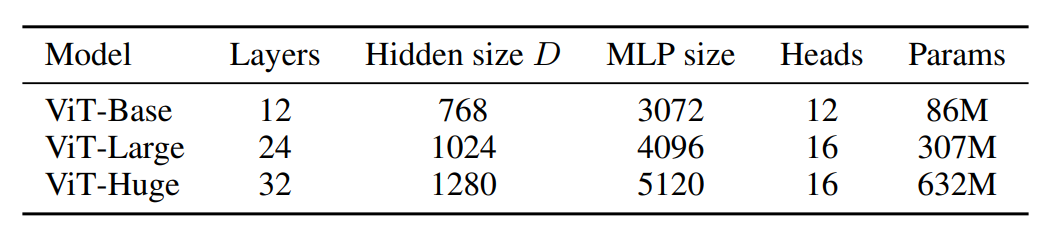
不同大小的ViT的参数量。
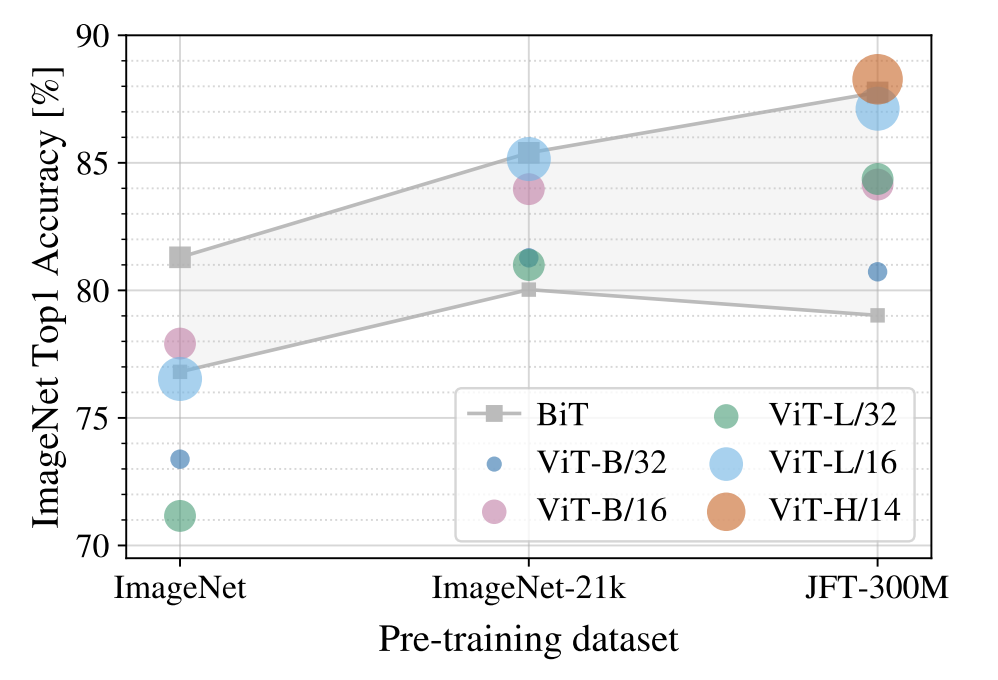
可以看到在预训练数据集很小的情况下ViT的效果并不好,但是好在随着预训练数据集越大时ViT的效果越好,最终超过ResNet。
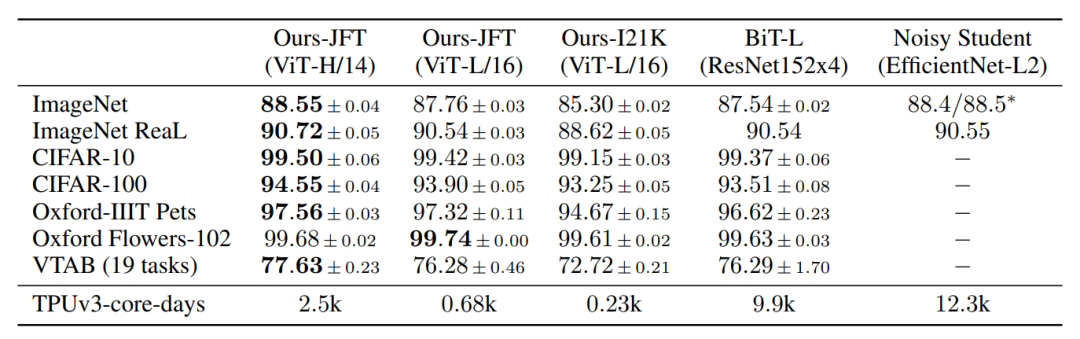
BiT[2]是谷歌用JFT-300M(谷歌内部非公开数据集)训练的ResNet模型。Noisy Student[3]是谷歌提出借助半监督大大提升了imagenet性能的算法。可以看到,在JFT-300M预训练的情况下,ViT比ResNet好上不少,并且开销更小。
总结
ViT的成功我认为是以下几点:
1、self-attention比CNN更容易捕捉long-range的信息;
2、大量的数据,在视觉中CNN是人类实践中很成功的inductive biases,显然大量的数据是能战胜inductive biases的;
3、计算效率高,因为self-attention可以看作是矩阵运算,所以效率很高,容易训练大型的模型。
原文标题:视觉新范式Transformer之ViT
文章出处:【微信公众号:深度学习实战】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
机器视觉
+关注
关注
160文章
4032浏览量
118252 -
机器学习
+关注
关注
66文章
8096浏览量
130520 -
Transforme
+关注
关注
0文章
12浏览量
8759
原文标题:视觉新范式Transformer之ViT
文章出处:【微信号:gh_a204797f977b,微信公众号:深度学习实战】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
视觉Transformer基本原理及目标检测应用
基于Transformer模型的压缩方法

更深层的理解视觉Transformer, 对视觉Transformer的剖析
LLM的Transformer是否可以直接处理视觉Token?

马毅团队新作:白盒ViT成功实现

介绍一种基于卷积和VIT的混合网络
汽车领域拥抱Transformer需要多少AI算力?
什么是编程范式?常见的编程范式有哪些?各大编程范式详解
使用 Vision Transformer 和 NVIDIA TAO,提高视觉 AI 应用的准确性和鲁棒性
超强Trick,一个比Transformer更强的CNN Backbone

基于 Transformer 的分割与检测方法

CVPR 2023 | 清华大学提出LiVT,用视觉Transformer学习长尾数据

Transformer结构及其应用详解
基于Transformer做大模型预训练基本的并行范式
爱芯元智AX650N成端侧、边缘侧Transformer最佳落地平台






 工商网监
工商网监
评论