 基于带约束强化学习的 BPP-1 求解
基于带约束强化学习的 BPP-1 求解
国防科技大学、克莱姆森大学和视比特机器人的研究人员合作使用深度强化学习求解在线装箱问题,该方法的性能表现优于现有的启发式算法。用户研究显示,该算法达到甚至超越了人类的在线码垛水平。作者团队还将训练模型部署到了工业机器人上,实现了业界首个高效能(连续码放 50 个以上随机尺寸箱子,空间利用率大于 70%)无序混合码垛机器人。
在物流仓储场景中,无序混合纸箱码垛机器人有着大量的应用需求。对于乱序到来的、多种尺寸规格的箱子,如何用机器人实现自动、高效的码垛,节省人力的同时提升物流周转效率,是物流仓储自动化的一个难点问题。其核心是求解装箱问题(Bin Packing Problem,BPP)这一经典的 NP 难题,即为每一个纸箱规划在容器中的摆放位置,以最大化容器的空间利用率。求解 BPP 问题的传统方法大多是基于启发式规则的搜索。
在实际应用场景中,机器人往往无法预先看到传送带上即将到来的所有箱子,因而无法对整个箱子序列进行全局最优规划。因而现有的 BPP 方法无法被直接用于真实物流场景。
事实上,人可以根据即将到来的几个箱子的形状尺寸,很快地做出决策,并不需要、也无法做到对整个箱子序列的全局规划。这种仅仅看到部分箱子序列的装箱问题,称为在线装箱问题(Online BPP)。物流输送线边上的箱子码垛任务一般都可以描述为 Online BPP 问题。因此,该问题的求解对于开发真正实用的智能码垛机器人有重要意义。
在 Online BPP 问题中,机器人仅能观察到即将到来的 k 个箱子的尺寸信息(即前瞻 k 个箱子),我们称其为 BPP-k 问题。对按序到来的箱子,机器人必须立即完成规划和摆放,不允许对已经摆放的箱子进行调整,同时要满足箱子避障和放置稳定性的要求,最终目标是最大化容器的空间利用率。Online BPP 问题的复杂度由箱子规格、容器大小、箱子序列的分布情况、前瞻数量等因素共同决定。由于仅知道部分箱子序列的有限信息,以往的组合优化方法难以胜任。
近日,国防科技大学、克莱姆森大学和视比特机器人的研究人员合作提出了使用深度强化学习求解这一问题。该算法性能优异,实现简单,可适用于任意多个前瞻箱子的情形,摆放空间利用率达到甚至超过人类水平。同时,该团队结合 3D 视觉技术,实现了业界首个高效能无序混合码垛机器人。论文已被人工智能顶会 AAAI 2021 大会接收。

论文链接:https://arxiv.org/abs/2006.14978
方法介绍
作者使用带约束的深度强化学习求解 BPP-1 问题,即只能前瞻一个箱子的情形。然后基于蒙特卡洛树搜索实现了从 BPP-1 到 BPP-k 的拓展。下图 1 给出了 BPP-1 和 BPP-k 问题的场景示意。

图 1(上):BPP-1的场景示意,绿色箱子为前瞻箱子。

图1(下):BPP-k 问题的场景示意,绿色箱子为前瞻箱子。
基于带约束强化学习的 BPP-1 求解
强化学习是一种通过自我演绎并从经验中学习执行策略的算法,很适合求解 Online BPP 这种基于动态变化观察的序列决策问题。同时,堆箱子过程的模拟仿真非常「廉价」,因而强化学习算法可以在模拟环境中大量执行,并从经验中学习码垛策略。然而,将强化学习算法应用到 Online BPP 上面临几个方面的挑战:首先,如果将水平放置面划分成均匀网格,BPP 的动作空间会非常大,而样本效率低下的强化学习算法并不擅长应对大动作空间的问题;此外,如何让强化学习算法更加鲁棒、高效地学习箱子放置过程中的物理约束(如碰撞避免、稳定支持等),也是需要专门设计的。
为了提升算法的学习效率,同时保证码放的物理可行性和稳定性,作者在 Actor-Critic 框架基础上引入了一种「预测 - 投影」的动作监督机制(图 2)。该方法在学习 Actor 的策略网络和 Critic 的 Q 值(未来奖励的期望)网络之外,还让智能体「预测」当前状态下的可行动作空间(可行掩码,feasibility mask)。在训练过程中,依据预测得到的可行掩码将探索动作「投影」到可行动作空间内,再进行动作采样。这样的有监督可行性预测方法,一方面可以让强化学习算法快速学习到物理约束,另一方面也尽可能避免了训练中箱子放置到不可行位置而提前终止序列,从而显著提升训练效率。
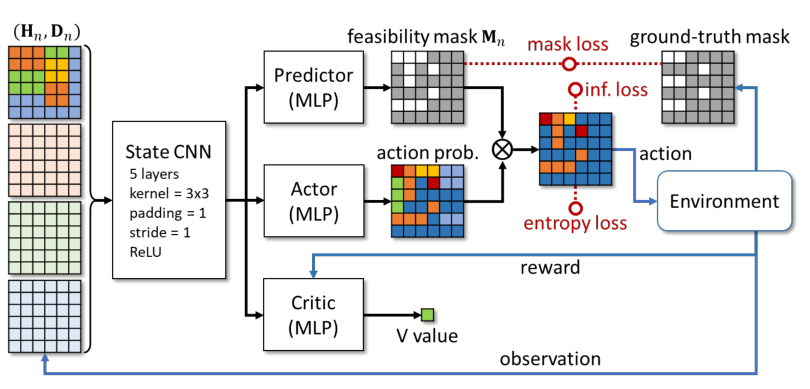
图 2:基于「预测 - 投影」的动作监督机制实现带约束的深度强化学习。
基于蒙特卡洛树搜索的 BPP-k 扩展
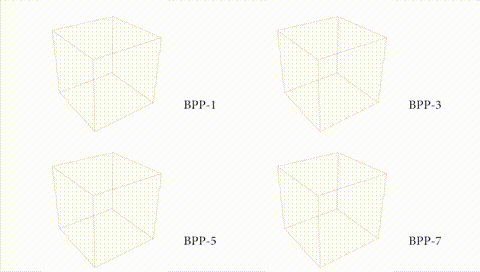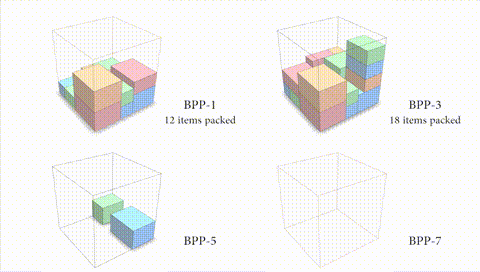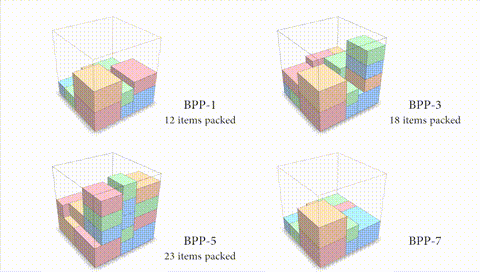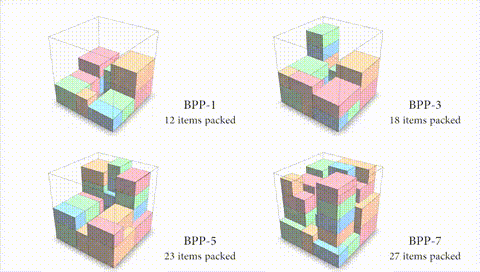
图 3:本文算法的空间利用率与前瞻箱子个数正相关。
如果算法能够在码放当前箱子的同时考虑之后到来的箱子尺寸,可能会得到更好的码放效果(如图 3 所示)。对于前瞻 k(k》1)个箱子的情况,一种方法是直接学习前瞻多个箱子的码放策略。但是,这种策略往往难以在任意前瞻箱子数目上很好地泛化。针对不同的 k 单独训练一种策略显然是不够聪明的做法。
对此,本文的处理方法是基于 BPP-1 这一基础策略,通过排序树搜索的方法拓展到 BPP-k 的情况。事实上,前瞻多个箱子的基本思想,就是在摆放当前箱子时,为后续箱子「预留」合适的空间,以使得这些箱子的整体摆放空间利用率更高。「预留」暗含了对于 k 个前瞻箱子的不同排序。因此,我们只需要搜索 k 个前瞻箱子的不同排序(图 4),找出一种空间利用率最高的排序,该序列所对应的当前箱子的摆放位置,即为当前箱子的最佳摆放位置。这样的处理方式,等同于在当前箱子的摆放过程中考虑了后来的箱子。不过,需要注意的是,在这些虚拟的摆放序列中,实际顺序中先到的箱子不能摆在后到的上面。
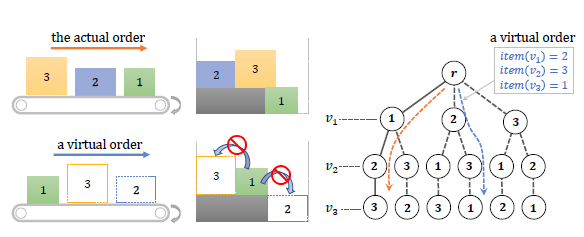
图 4:箱子的真实顺序(左上)和虚拟重排顺序(左下,实际顺序靠前的箱子不能放在实际顺序靠后箱子的上面),右边展示了不同序列的排序树。
显然,考虑所有的排序可能很快带来组合爆炸问题。为此,作者使用蒙特卡洛树搜索(MCTS)来减小搜索空间。作者基于 critic 网络输出的 Q 值,对从当前状态之后可能得到的奖励进行估计。在排序树搜索过程中,优先选择可能得到更高奖励的节点进行展开。这样可将搜索复杂度控制在线性级别。
此外,作者还介绍了处理箱子水平旋转和多容器码放的扩展情况。如果码放过程中允许箱子水平旋转,则只需将 BPP-1 模型中的动作空间和可行掩码同时复制,分别处理两种朝向。针对多容器码放,算法需要对箱子放入每个容器所带来的 Q 值变化进行量化:作者使用 critic 网络对箱子码放到某个容器前后的 Q 值进行评估,每次都将箱子放入 Q 值下降最小的容器内。
实验结果
在 BPP-1 上,作者将本文方法和其他启发式算法进行了对比(图 5)。在三种不同数据集上,基于深度强化学习算法的性能显著优于人为设计启发式规则(尤其是面向 Online BPP 的)。
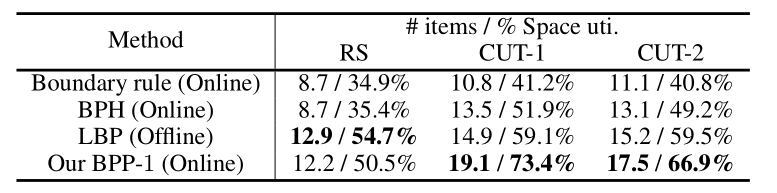
图 5:深度强化学习算法和启发式算法在 BPP-1 问题上的性能(摆放箱子数目和空间利用率)对比。
同样在 BPP-1 问题上,作者针对不同的约束项进行了消融实验(图 6):MP - 可行掩码预测;MC - 可行掩码投影;FE - 动作熵(多样性)最大化。实验结果表明,在训练过程中加入可行动作约束对训练效果有显著提升。

图 6:本文算法在 BPP-1 问题上的消融实验
作者在 BPP-k 上验证了排序树搜索可以使空间利用率随着前瞻数量 k 的提升而提升(图 7b),而使用蒙特卡洛树搜索可以在不明显影响性能的前提下,显著降低排序树搜索的时间开销(图 7a)。此外,作者针对 BPP-1 进行了用户研究,比较本文 BPP-1 算法和人摆放的空间利用率。如图 7c 所示,本文方法超越了人类摆放的性能:在总共 1851 个高难度随机箱子序列中,人类获胜的次数是 406 次,平均性能表现是 52.1%,而强化学习获胜的次数是 1339 次,平均性能表现是 68.9%。
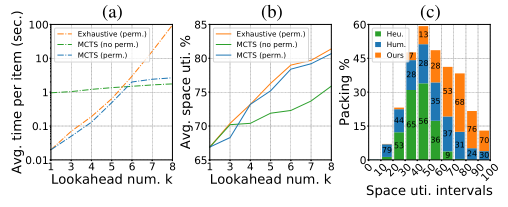
图 7 (a):穷举排序数搜索和 MCTS 算法的时间开销对比;(b):穷举排序数搜索和 MCTS 算法的时间开销对比;(c):本文算法、启发式算法 BPH 和人类用户的码放性能对比。
对于不同的前瞻箱子数,本文方法和启发式算法 BPH 的性能对比情况如图 8 所示。尽管 BPH 算法允许对前瞻箱子的顺序进行任意调整而本文方法不允许,但本文方法仍然能取得更好的性能。
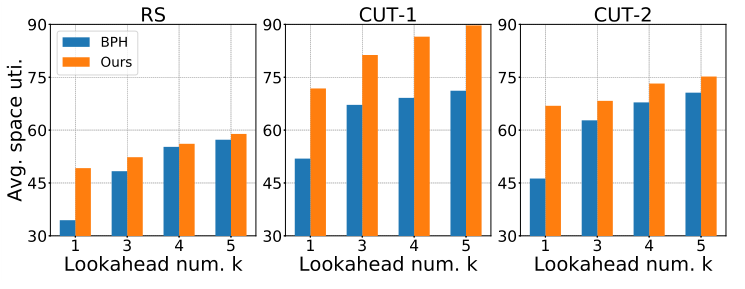
图 8:在三个数据集上的 BPP-k 任务中,深度强化学习算法与启发式算法的性能对比。
为验证本文算法的有效性,作者团队将模型部署到工业机器人上,实现了一个智能码垛机器人(图 9,查看完整视频)。将仿真环境训练的策略应用到真实环境,涉及从虚拟到真实环境的策略迁移(Sim2Real)问题。为此,作者基于「Real2Sim」的思路,采用 3D 视觉算法,实时检测容器上箱子的真实摆放情况,并转换为与虚拟世界对应的理想 box 表示,作为强化学习模型的输入。对于乱序到来的随机尺寸箱子,该机器人能够连续、稳定、快速码放数十个箱子,容器空间利用率达到 70% 以上,性能远超现有同类型机器人。
图9: 基于深度强化学习的高效能无序混合码垛机器人。
责任编辑:lq
-
机器人
+关注
关注
206文章
27021浏览量
201365 -
算法
+关注
关注
23文章
4453浏览量
90746 -
强化学习
+关注
关注
4文章
259浏览量
11113
原文标题:强化学习与3D视觉结合新突破:高效能在线码垛机器人
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是强化学习

NeurIPS 2023 | 扩散模型解决多任务强化学习问题

模拟矩阵在深度强化学习智能控制系统中的应用

语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路

基于强化学习的目标检测算法案例

什么是深度强化学习?深度强化学习算法应用分析


利用强化学习来探索更优排序算法的AI系统

使用信赖域法求解无约束优化问题
基于深度强化学习的视觉反馈机械臂抓取系统
ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2

彻底改变算法交易:强化学习的力量
一种用于随机约束仿真的SAT增强的字级求解器

基于多智能体深度强化学习的体系任务分配方法





 工商网监
工商网监
评论