 如何让神经声码器高效地用于序列到序列声学模型
如何让神经声码器高效地用于序列到序列声学模型
往往在放下手机之后你才会意识到,电话那头的客服其实是个机器人;或者准确地说,是“一位”智能客服。
没错,今天越来越多的工作正在被交给人工智能技术去完成,文本转语音(TTS,Text To Speech)就是其中非常成熟的一部分。它的发展,决定了今天我们听到的许多“人声”,是如此地逼真,以至于和真人发声无异。
除了我们接触最多的智能客服,智能家居中的语音助手、可以服务听障人士的无障碍播报,甚至是新闻播报和有声朗读等服务,事实上都基于TTS这项技术。它是人机对话的一部分——简单地说,就是让机器说人话。
它被称为同时运用语言学和心理学的杰出之作。不过在今天,当我们称赞它的杰出时,更多的是因为它在在线语音生成中表现出的高效。
要提升语音合成效率当然不是一件容易的事。这里的关键是如何让神经声码器高效地用于序列到序列声学模型,来提高TTS质量。
科学家已经开发出了很多这样的神经网络声码器,例如WaveNet、Parallel WaveNet、WaveRNN、LPCNet 和 Multiband WaveRNN等,它们各有千秋。
WaveNet声码器可以生成高保真音频,但在计算上它那巨大的复杂性,限制了它在实时服务中的部署;
LPCNet声码器利用WaveRNN架构中语音信号处理的线性预测特性,可在单个处理器内核上生成超实时的高质量语音;但可惜,这对在线语音生成任务而言仍不够高效。
科学家们希望TTS能够在和人的“交流”中,达到让人无感的顺畅——不仅是语调上的热情、亲切,或冷静;更要“毫无”延迟。
新的突破出现在腾讯。腾讯 AI Lab(人工智能实验室)和云小微目前已经率先开发出了一款基于WaveRNN多频带线性预测的全新神经声码器FeatherWave。经过测试,这款高效高保真神经声码器可以帮助用户显著提高语音合成效率。
英特尔的工程团队也参与到了这项开发工作中。他们把面向第三代英特尔至强可扩展处理器所做的优化进行了全面整合,并采用了英特尔深度学习加速技术(英特尔 DL Boost)中全新集成的 16 位 Brain Floating Point (bfloat16) 功能。
bfloat16是一个精简的数据格式,与如今的32位浮点数(FP32)相比,bfloat16只通过一半的比特数且仅需对软件做出很小程度的修改,就可达到与FP32同等水平的模型精度;与半浮点精度 (FP16) 相比,它可为深度学习工作负载提供更大的动态范围;与此同时,它无需使用校准数据进行量化/去量化操作,因此比 INT8 更方便。这些优势不仅让它进一步提升了模型推理能力,还让它能为模型训练提供支持。
事实上,英特尔至强可扩展处理器本就是专为运行复杂的人工智能工作负载而设计的。借助英特尔深度学习加速技术,英特尔志强可扩展处理器将嵌入式 AI 性能提升至新的高度。目前,此种处理器现已支持英特尔高级矢量扩展 512 技术(英特尔AVX-512 技术)和矢量神经网络指令 (VNNI)。
在腾讯推出的全新神经声码器FeatherWave 声码器中,就应用了这些优化技术。
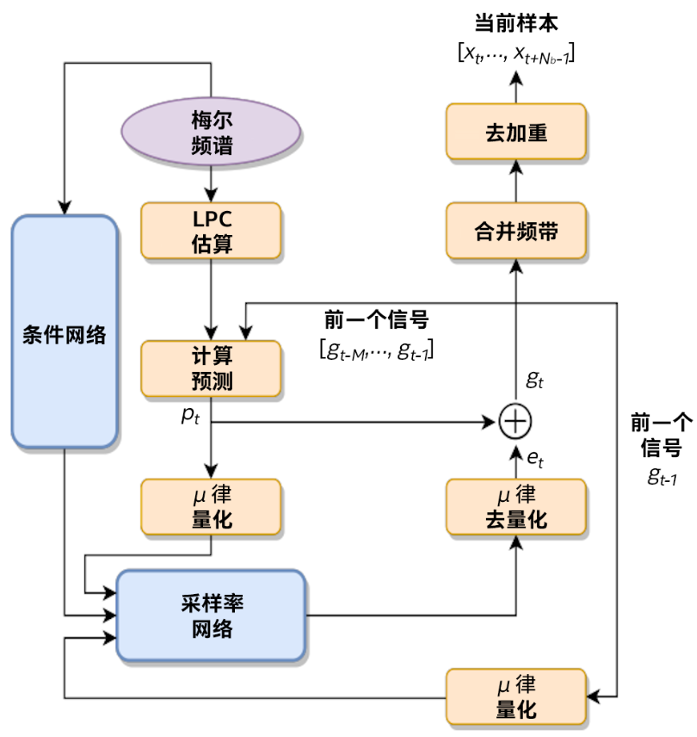
FeatherWave 声码器框图
利用英特尔AVX-512技术和bfloat16指令,腾讯的科学家们确保了GRU模块和Dense运算符中粗略部分/精细部分的所有SGEMV计算都使用512位矢量进行矢量化,并采用bfloat16点积指令;对于按元素逐个加/乘等运算以及其他非线性激活,都使用最新的英特尔AVX-512 指令运行。
在最终都性能测试中,通过优化,相同质量水平(MOS4.5)的文本转语音速度比FP32提升了高达1.54倍。
此外,腾讯还以 GAN 和 Parallel WaveNet (PWaveNet)为基础,推出了一种改进后的模型,并基于第三代英特尔至强可扩展处理器对模型性能进行了优化,最终使性能与采用FP32相比提升了高达1.89倍,同时质量水平仍保持不变 (MOS4.4)。
腾讯在TTS领域的进展显示出了人工智能领域的一个趋势,那就是科学家们越来越多开始利用英特尔深度学习加速技术在CPU平台上开展工作。
就像腾讯在针对TTS的探索中获得了性能提升那样,第二代和第三代英特尔至强可扩展处理器在集成了加速技术后,已经显著提升了人工智能工作负载的性能。
在更广泛的领域内,我们已经能够清楚地看到这种变化——在效率表现上,由于针对常见人工智能软件框架,如TensorFlow和PyTorch、库和工具所做的优化,CPU平台可以帮助保持较高的性能功耗比和性价比。
尤其是扩展性上,用户在设计系统时可以利用如英特尔以太网700系列,和英特尔傲腾内存存储技术,来优化网络和内存配置。这样一来,他们就可以在充分利用现有硬件投资的情况下,轻松扩展人工智能训练的工作负载,获得更高的吞吐量,甚至处理巨大的数据集。
不止于处理器平台本身,英特尔目前在面向人工智能优化的软件,以及市场就绪型人工智能解决方案两个维度,都建立起了差异化的市场优势。
例如在软件方面,英特尔2019年2月进行的 OpenVINO/ResNet50 INT8 性能测试显示,使用 OpenVINO或TensorFlow和英特尔深度学习加速技术时,人工智能推理性能可提高多达 3.75 倍。
今天,英特尔已经携手解决方案提供商,构建了一系列的精选解决方案。这些方案预先进行了配置,并对工作负载进行了优化。这就包括了如基于人工智能推理的英特尔精选解决方案,以及面向在面向在Apache Spark上运行的BigDL的英特尔精选解决方案等。
这些变化和方案的出现对于那些希望能从整体业务视角,去观察人工智能进展的机构或企业的管理层显然也很有意义——如果只通过优化,就能在一个通用平台上完成所有人工智能的探索和落地,那么投资的价值就能够实现最大化。
许多企业做出了这样的选择,GE医疗就是其中一家。作为GE集团旗下的医疗健康业务部门,它构建了一个人工智能医学影像部署架构。
通过采用英特尔至强可扩展处理器,和英特尔固态盘,以及多项英特尔关键技术——例如英特尔深度学习开发工具包,和面向深度神经网络的英特尔数学核心函数库等;GE医疗收获了未曾预料到的成果:
这一解决方案最终比基础解决方案的推理速度提升了多达14倍,且超过了GE原定推理目标5.9倍。
责任编辑:xj
-
机器人
+关注
关注
206文章
26964浏览量
201281 -
神经网络
+关注
关注
42文章
4562浏览量
98643 -
智能化
+关注
关注
15文章
4423浏览量
54071
发布评论请先 登录
相关推荐
TSMaster 序列发送模块在汽车开发测试中的应用

ICLR 2024高分投稿:用于一般时间序列分析的现代纯卷积结构

实序列的z变换为什么会出现一对相互共轭的复数零点?
FPGA电路实现:m序列及应用
时间序列的基础模型像自然语言处理那样存在吗
如何用C语言进行json的序列化和反序列化
如何使用Serde进行序列化和反序列化
什么是序列化 为什么要序列化
FPGA学习-序列检测器






 工商网监
工商网监
评论