 视觉信号辅助的自然语言文法学习
视觉信号辅助的自然语言文法学习
长久以来,自然语言的文法学习(Grammar Learning)只考虑纯文本输入数据。我们试图探究视觉信号(Visual Groundings),比如图像,对自然语言文法学习是否有帮助。为此,我们提出了视觉信号辅助下的概率文法的通用学习框架。 该框架依赖于概率文法模型(Probabilistic Context-Free Grammars),具有端到端学习、完全可微的优点。其次,针对视觉辅助学习中视觉信号不足的问题。我们提出在语言模型(Language Modeling)上对概率文法模型进行额外优化。我们通过实验验证视觉信号以及语言模型的优化目标有助于概率文法学习。 论文一作赵彦鹏:爱丁堡大学语言、认知和计算研究所博士生,导师是Ivan Titov和Mirella Lapata教授。他的研究兴趣是结构预测和隐变量模型。现在主要关注语言结构和图像结构的学习,以及二者之间的联系。 1
背景
本次分享内容是,用视觉信号来辅助概率文法学习的一个通用学习框架。我们关注的问题是,视觉信号能否帮助我们来推理出自然语言的句法结构? 接下来我将从以下几个部分展开。 首先介绍视觉信号辅助下的概率文法学习的一些背景知识和现有的一些工作。 然后介绍本文提出的Visually Grounded Compound PCFGs (VC-PCFGs)。 最后实验验证VC-PCFGs的有效性。 论文:《Visually Grounded Compound PCFGs》
首先了解问题定义:给定一张图片以及它的自然语言描述,比如这里有一张鸽子的图片,它的语言描述是a white pigeon sniffs flowers,我们的目标是通过图片和文字两个输入,得到对应句子的句法结构,也就是右边的图。句法结构由不同的词组嵌套而成,每个词组可能有不同的类型,它可以是一个名词词组或者是一个动词的组。在学习过程中,这种词组的类别信息依赖于文法模型的选择,但是评测的时候一般会忽略。 为什么视觉信号可以帮助文法结构的学习?这依赖于如下观测:给定一个句子,如果相邻的两个词组,比如white和pigeon,对应/关联于图片中一个相同的区域,那么就有理由相信它们更有可能形成一个大的词组,进而把它们合并起来。接下来的问题是如何表示这种相关性信息?我们的想法是通过相似度来量化相关性。
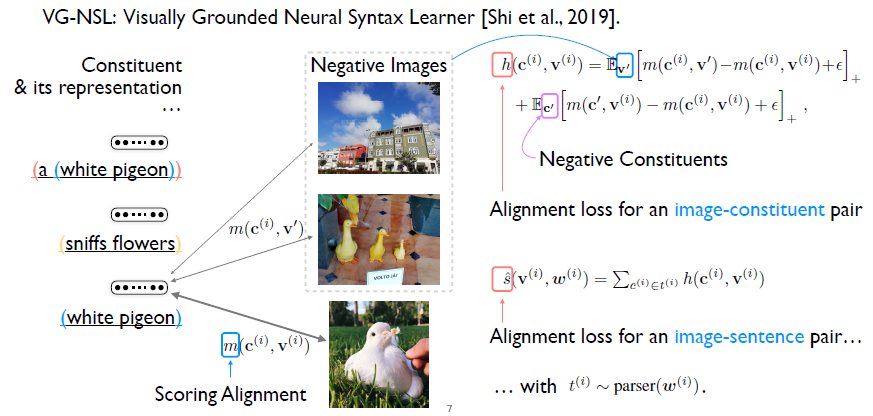
如何去学习相似度?之前的模型应用对比学习的方式(Contrastive Learning)。首先给定一张图片以及句子,然后通过文法模型,得到句子的句法结构的表示。刚才已经提到句法结构对应的就是一些嵌套的词组,我们可以把这些词组提取出来,和相应的图片组成词组图片对,称之为正样本。 然后固定一个词组,从数据集里面随机采样一些图片。并将采样得到的图片和当前固定的词组同样组成新的词组图片对,作为负样本。对比学习的优化目标就是使正样本的得分比负样本的得分高。类似的,我们也可以固定图片,从其他句子里面随机的采样一些词组,和当前图片组合构成负样本。这样就完整定义了一个词组图片对的损失函数。 因为一个句子可以包含多个不同的词组,那么在所有的词组图片对上加和,就可以得到一个句子图片对的损失函数。需要注意的是这里提到的这些词组是来自于一个句法结构,这个句法结构是从一个文法模型里面采样得到的。 我们已经能够表示和学习这种相似度,接下来如何从相似度学习文法模型?
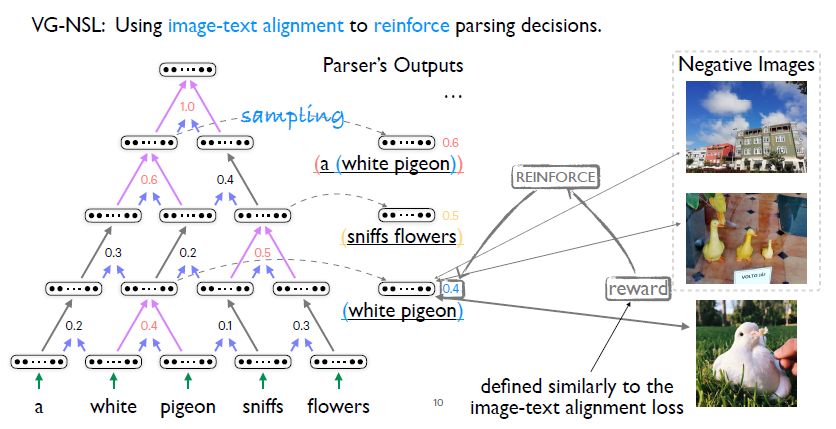
首先了解一下之前的工作,其选择了一个贪心文法模型。所谓贪心就是每次它只会选择最有可能合并到一起的两个词组,进行合并。其次,贪心意味着它只能去采样,不能够在有限时间内枚举所有可能的句法结构,所以它学习就依赖于强化学习的方法。直观理解是,如果当前合并起来的两个词组和给定的图像相似度很高,那么有理由相信它们更有可能被合并。我们应用之前定义的词组图片对之间的相似度,作为一个reward,强化合并操作。 虽然这样一个模型比较直观,但是还有下列这些缺陷,首先强化学习依赖于采样,所以在优化过程中,即评估梯度的时候会有很大的噪声。
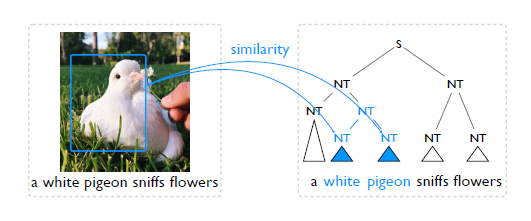
其次对于视觉信号辅助下的自然语言文法学习,有一个本质的问题,即有些句法结构的信息在相应的图片里面是找不到支撑信息的。比如这里稍微改变一下这个句子, a white pigeon is sitting in the grass peacefully。我们很难去找到sitting这样一个动词以及peacefully这样一个副词在这个图片里面所对应的视觉信号是什么。观察之前的文章作者汇报的一些结果,我们发现他们的模型在名词词组,即NPs,相对于在动词VPs上的结果要好很多。为了缓解这个问题,他们不得不借助于语言特定的先验信息。 2
我们的模型:VC-PCFGs
那么我们是如何解决这些问题的呢?首先,对于强化学习带来的梯度评估中的噪声问题。我们提出把贪心文法模型替换为概率文法模型,即PCFGs。替换之后我们可以将采样操作去掉,同时优化过程是完全可微的。我们称之为,Visually Grounded Compound PCFGs。至于compound这个名词的解释稍后会提到。 其次是视觉信号不充分的问题。对于一个概率文法模型,只给定纯文本,而没有视觉信号的情况下,我们可以通过优化语言模型的目标函数来学习概率文法模型,所以我们提出在语言模型目标函数上对概率文法模型进行优化。 也就是说我们的模型包含两部分,首先是引入视觉信号的概率文法模型的学习,其次在语言模型目标上来优化概率文法模型。值得注意的是,这两个过程都是完全可微的。接下来我们详述这两部分。

首先回顾视觉信号辅助的文法模型学习中的一个重要的损失函数,在之前的工作中,给定一个文法模型,即parser,采样得到一个句法结构,通过枚举这个句法结构所定义的所有词组,之后在词组图片对上把它们的loss加和,得到一个句子图片对上的loss。我们的目标是把这样一个采样过程去掉,也就意味着必须想办法计算句法结构分布下的损失函数的期望值。

期望可以写成加和的形式。给定一个句子的话,这个句法结构空间是指数级别的,我们不可能枚举所有句法结构。但是我们可以把这个式子中的两个加法操作交换顺序。第一个加法操作是枚举所有的句法结构,第二个加法是要枚举句法结构中所有的词组。交换顺序之后做一些简单的推导,就可以得到最右边的等式。这个等式意味着只需要枚举给定句子的所有的词组,这是很容易做到的,因为其所有的词组数目也就N平方级别。 接下来问题转换成如何来评估条件概率?即给定一个句子,其中一个词组的条件概率是什么?这就是通常所说的后验评估的问题。其次,还需要得到这个词组Span c的表示。我们需要用它和图像做一个相似度的计算。最终的问题可以划分成两个部分:后验评估和Span的表示。
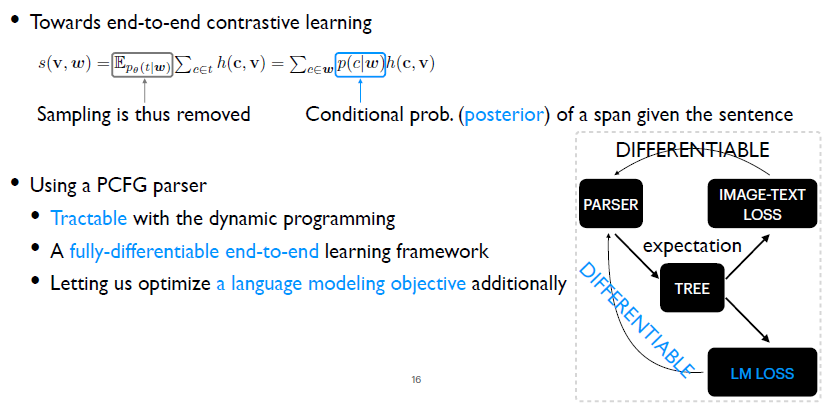
首先第一个部分,后验评估。我们选择了一个概率文法模型,PCFG parser。因为用这样一个概率文法模型的话,可以通过动态规划的方法方便地计算后验概率。然后通过计算句法树分布下的损失函数期望值,得到去除采样过程的损失函数。同时它的优化是完全可微的。其次,因为概率文法模型的优化本身可以不依赖于视觉信号,所以我们可以直接去优化它的语言模型上的目标函数,这个过程同样是完全可微的,同时缓解了视觉信号不充分的问题。 对于概率文法模型,我们选择了当前最好的一个概论文法模型,即Compound PCFGs。需要指出的就是Compound PCFGs只是PCFGs的一个扩展,所以之前提到的关于PCFGs的所有的优点它都是具备的。这样便得到我们的完整模型,即Visually Grounded Compound PCFGs。

接下来来看第二个模块。第二个模块是给定一个句子如何来表示它的词组。我们这里选择了双向的LSTM模型。对于一个句子中所有不同长度的词组,我们在词组级别上做编码,得到词组的向量化表示。这样一个模型能够保证当前词组的表示,不会用到词组之外的信息。通过一些代码实现上的技巧,我们可以在线性时间复杂度内得到所有词组的表示。 3
结论验证
最后是实验部分。

实验部分使用了MSCOCO数据集,每个图片对应有一个自然语言的描述。由于数据集中的自然语言描述没有真实的句法结构标注,为了评测,我们使用了当前最好的一个有监督的文法模型,得到自然语言描述的句法结构。对于图像的编码,我们沿用之前工作的方法,对每个模型用预练好的,ResNet-101,把每个图片编码成一个向量的表示。
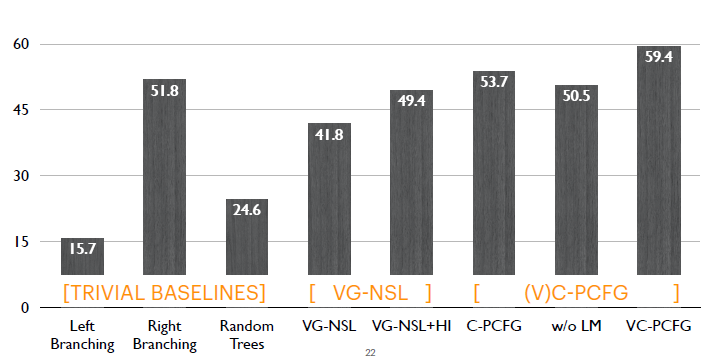
评测中,我们在每一种设置下重复运行模型4次并取平均,每次使用了不同的随机数种子。评测指标使用句子级别的F1评测。模型之间的对比,这里主要有三组模型: 1.第一组是很简单的对比模型,比如Left Branching, Right Branching, Random Trees。 2.第二组是之前模型,即VG-NSL,我们对比它在使用和不使用语言特定先验下的结果。 3.第三组是我们的模型,因为这里主要评测两个模块: a)仅应用语言模型的目标函数,对应Compound PCFGs(C-PCFGs)。 b)只应用视觉信号,也就第二个without language mode objective(w/o LM)。 最后是我们完整的模型VC-PCFG,既用语言模型的目标函数,又用视觉信号信息。
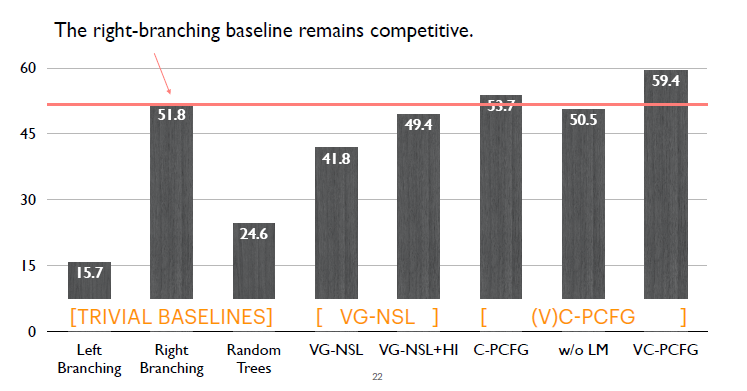
接下来看一下整体结果。首先是Right-branching模型表现强势,只有Compound PCFG以及VC-PCFG,远远的超过了它,其他模型都比这个简单的模型表现要差。
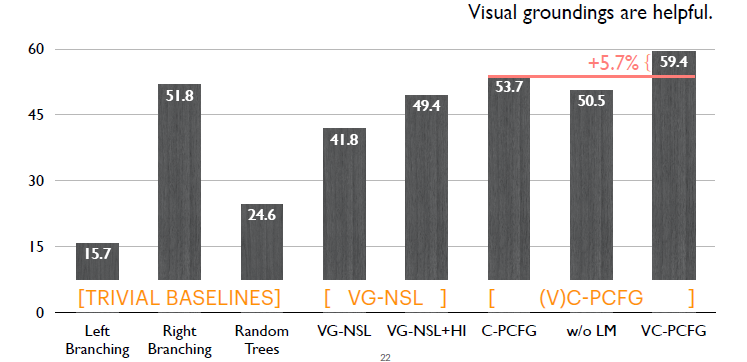
这里对比C-PCFG和VC-PCFG。模型如果额外使用视觉信号的话,可以带来接近6%的提升。
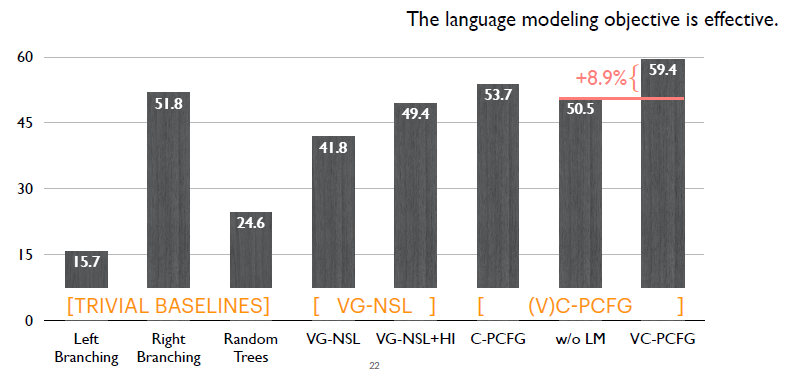
这里对比只使用视觉信号的模型(w/o LM)与加入语言模型目标函数的完整模型(VC-PCFG),我们可以看出语言模型目标函数带来将近9%的一个提升。
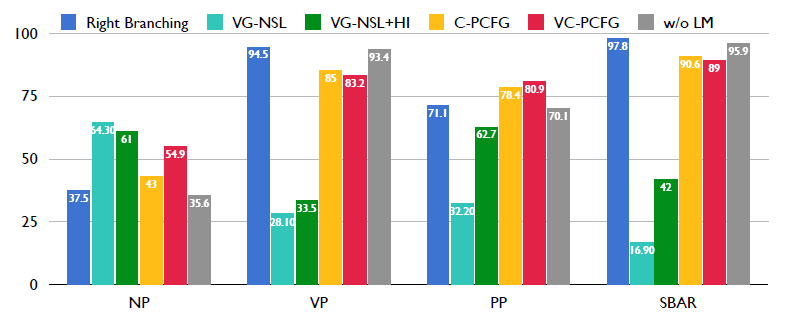
我们想知道这些模型提升主要来自于哪一种类型的词组?我们这里选择了测试集里面四个频率比较高的词组类型。首先第一个是名词词组,然后第二个是动词词组,第三个是介词词组,第四个是连词词组。因为模型在介词和连词上的性能和在动词词组上的性能比较类似,接下来我们只在名词词组和动词词组上做比较。
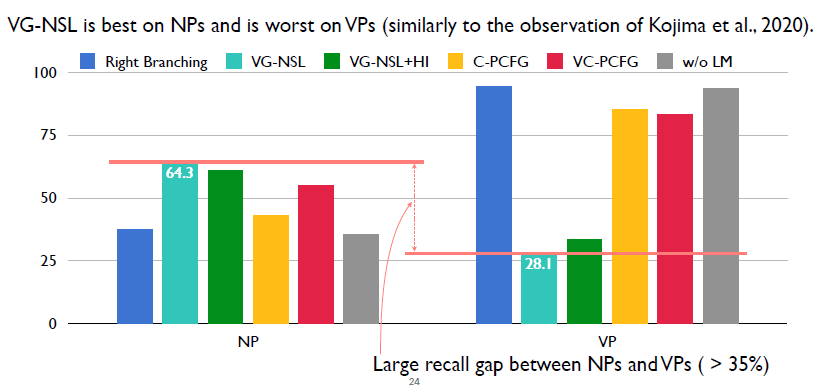
首先先看一下之前的模型VG-NSL,这里重新验证了作者的实验结果。VG-NSL在NP上的性能超过VP上的性能大于35%。
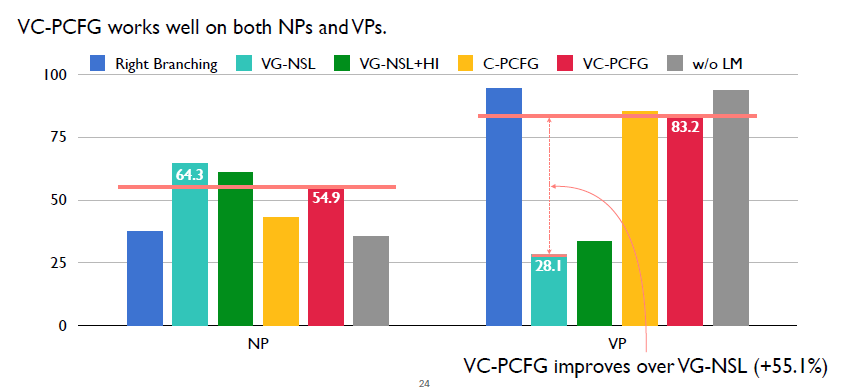
这里显示的是我们的完整模型,VC-PCFG对应的是红色柱状图。可以看出相对于其他模型,它的效果虽然不是最好的,但是它整体来说是较好的。然后在VP上,相对于之前的VG-NSL,我们的模型比它高出了55%。
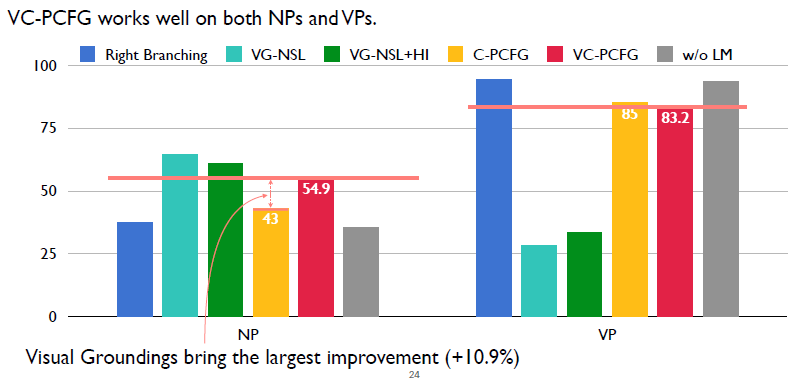
接下来验证视觉信号的有效性。没有用视觉信号的是黄色柱状图,使用了视觉信号的是红色柱状图。在NP上,使用视觉信号可以带来将近11%的一个提升,也就是说视觉信号对NP是有帮助的。
这里验证语言模型的目标函数的有效性。同样我们发现语言模型目标函数也是在NP上带来一个很大的提升,提升了大概19%。
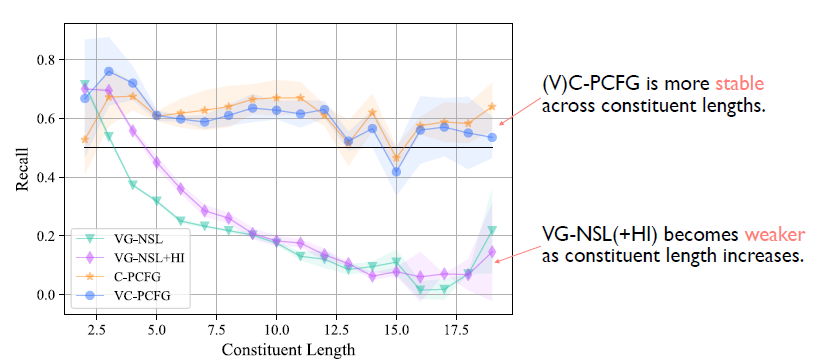
最后我们从另外一个角度来分析模型。即这些模型在不同长度的词组上的效果如何。这张图首先可以看有一个明显的差别:上面两个对应的是C-PCFG以及VC-PCFG,这两个模型明显是要优于之前的VG-NSL。 具体来说的话,当词组的长度大于4的时候,这两个模型始终是优于之前的VG-NSL,即便之前的VG-NSL加了一个语言特定的先验知识。
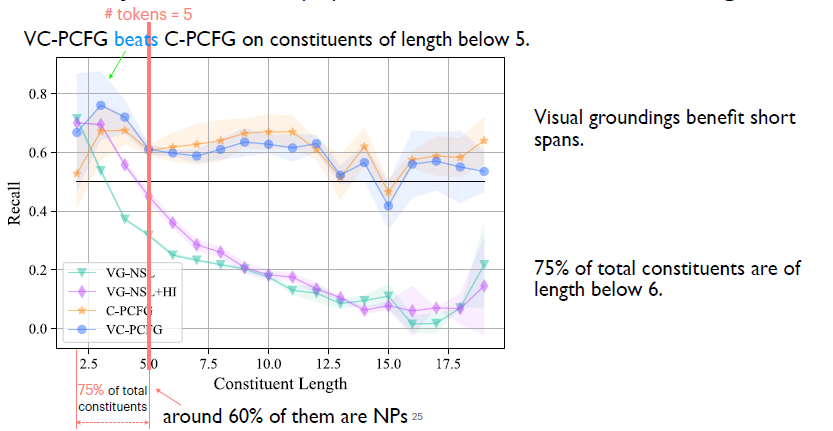
这里对比视觉信号是否有帮助。蓝色是是我们完整的模型,橙色的是没有加入视觉信号的模型。我们发现当词组的长度小于5的时候,蓝色对应的模型,即使用了视觉信号模型是要显著优于不用视觉信号的模型,所以我们结论是视觉信号对于短的一些词组是有帮助的。然而我们发现这些短词组占了整个数据集所有词组大概75%,而在75%里面又有60%是名词词组,所以我们可以说视觉信号对于文法学习的帮助主要体现在名词词组上。 4
结论
我们提出了VC-PCFGs。它应用Compound-PCFGs作为文法模型,是一个端到端可微,在视觉信号辅助下的文法学习通用框架。 VC-PCFGs允许我们额外优化一个语言模型的目标函数,进而缓解视觉信号不充分的问题。 我们实验验证了视觉信号以及语言模型的优化目标函数对于文法学习都有帮助。
原文标题:EMNLP 2020最佳论文荣誉提名:视觉信号辅助的自然语言文法学习
文章出处:【微信公众号:通信信号处理研究所】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
信号
+关注
关注
11文章
2635浏览量
75379 -
自然语言
+关注
关注
1文章
269浏览量
13202
原文标题:EMNLP 2020最佳论文荣誉提名:视觉信号辅助的自然语言文法学习
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于自然语言的轨迹修正方法
自然语言处理的研究内容
2023年科技圈热词“大语言模型”,与自然语言处理有何关系

自然语言处理和人工智能的区别
自然语言处理和人工智能的概念及发展史 自然语言处理和人工智能的区别
自然语言处理的概念和应用 自然语言处理属于人工智能吗
自然语言处理的优缺点有哪些 自然语言处理包括哪些内容
亚马逊云科技结合大语言模型和自然语言问答,加速的数据决策
自然语言处理包括哪些内容 自然语言处理技术包括哪些
PyTorch教程-16.7。自然语言推理:微调 BERT

PyTorch教程-16.5。自然语言推理:使用注意力






 工商网监
工商网监
评论