 浪潮AI服务器NF5488A5的实测数据分享,单机最大推理路数提升88%
浪潮AI服务器NF5488A5的实测数据分享,单机最大推理路数提升88%
近日,在GTC China元脑生态技术论坛上,中科极限元、趋动科技、睿沿科技等元脑生态伙伴分享了多个场景下浪潮AI服务器NF5488A5的实测数据,结果表明浪潮NF5488A5大幅提升了智能语音、图像识别等AI模型的训练和推理性能,促进了产业AI解决方案的开发与应用。
NF5488A5是浪潮自研的新一代AI服务器,在4U空间内支持8颗第三代NVLink全互联的A100芯片,可为用户提供高达5 PetaFLOPS的AI计算性能和超高速带宽,为各类AI应用场景提供强大的计算力支撑。NF5488A5曾屡次打破全球权威AI测试榜单MLPerf的记录,基于ImageNet的ResNet50基准测试显示,NF5488A5完成训练仅需33.37分钟,单机性能高居第一;推理性能达到每秒54.9万张图片,3倍于去年推理榜单的服务器最好性能。
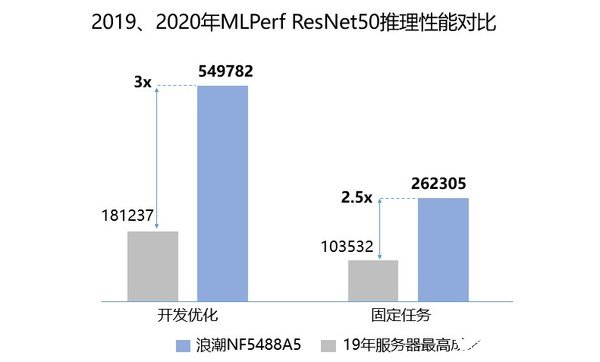
在本次GTC元脑生态技术论坛上,生态伙伴展示了与浪潮的合作方案并公布了在NF5488A5上的性能实测数据。
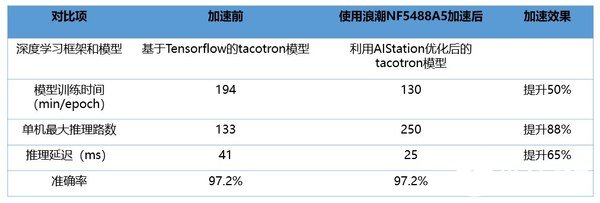
中科极限元开发的智能语音交互解决方案在国内处于领先水平,广泛应用于教育、交通、呼叫中心、智能硬件等多个领域,本次在浪潮NF5488A5进行加速。NF5488A5高性能、高带宽、易部署的特性极大地促进了智能语音模型训练及线上推理。测试数据显示,在相同准确率下,与原有的系统相比,NF5488A5将模型训练速度提升了50%,单机最大推理路数提升88%,推理延迟提升65%。
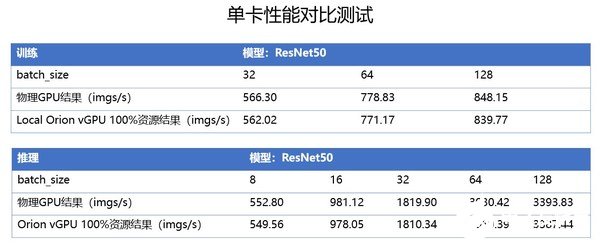
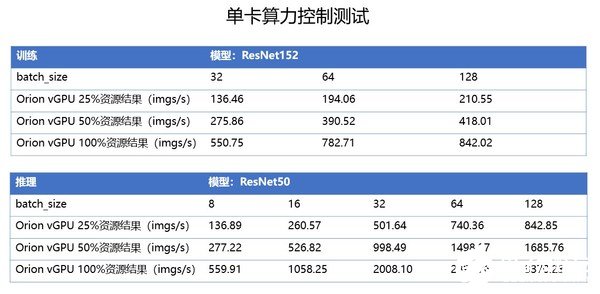
趋动科技与浪潮联合打造了业内领先的一体化GPU资源池化解决方案。本次测试采用TensorFlow框架的Benchmark,测试小模型推理、大模型训练等多种AI应用场景,验证趋动科技OrionX AI加速器资源池化方案对浪潮NF5488A5的兼容性和性能。结果表明,NF5488A5服务器性能优异,部署资源池化方案后,本机性能损耗小于1%,对比以往服务器的GPU性能,数据提升近50%。
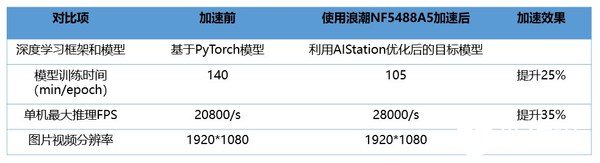
睿沿科技推出的高山雨燕工业视觉平台是为工业生产场景构建的智能多业务管理安全生产管理平台,可实现远程巡检、作业安全监管、区域安防等功能。该平台在计算层使用了浪潮NF5488A5加速训练和推理。实测结果显示,在图片视频分辨率相同的情况下,模型原来的训练时间为140分钟,使用NF5488A5之后,训练时间可缩短到105分钟,速度提升25%。单机最大推理FPS(每秒传输帧数)由20800提高到28000,提升35%。
以上实测数据显示,浪潮NF5488A5可广泛应用于图像视频、语音识别、金融分析、智能客服等典型AI应用场景,帮助AI用户高效完成AI基础设施和开发环境的构建,缩短开发周期,显著提升AI开发和应用效率。
浪潮是全球领先的AI计算领导厂商,其AI服务器在中国的市场份额已连续三年保持在50%以上。面对产业AI化的趋势,浪潮提出元脑生态,将聚集左右手伙伴、浪潮AI资源,以更加优质的产品技术能力和整体方案实施能力助力更多用户实现智能化转型和升级。在元脑生态中,浪潮将共享AI计算平台、AI资源平台和AI算法平台。目前元脑生态吸引了200+左右手伙伴参与,孵化出6大行业100+解决方案。
责任编辑:gt
-
服务器
+关注
关注
12文章
8088浏览量
82433 -
浪潮
+关注
关注
1文章
404浏览量
23562 -
AI
+关注
关注
87文章
26362浏览量
263947
发布评论请先 登录
相关推荐
台积电:AI服务器处理器预计翻番,拉动收入增长
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型开发效率提升10倍
使用NVIDIA Triton推理服务器来加速AI预测
浪潮信息服务器NF5180G7荣获SPECjbb2015性能冠军

1U和2U服务器有何区别?
浪潮信息NF5468系列AI服务器率先支持英伟达最新推出的L40S GPU
浪潮信息NF5468服务器LLaMA训练性能
台湾AI服务器及玩家分析(2023)

浪潮NF5468A5 GPU服务器整体设计及性能深度测评解读

AI服务器与传统服务器的区别是什么?
如何使用FasterTransformer进行单机及分布式模型推理





 工商网监
工商网监
评论