 Ampere架构GPU带来了什么
Ampere架构GPU带来了什么
在今年10月份,NVIDIA正式发布了采用8nm制程工艺Ampere架构的RTX A6000、RTX A40两款专业图形和计算GPU,这两款产品采用RT Core、Tensor Core和CUDA Core,旨在加速图形、渲染、计算和AI,分别面向工作站和服务器用途。
长久以来,NVIDIA在专业级别GPU领域不断进行创新,此前已经推出过Kepler、Maxwel、Pascal以及Turing等架构,此次,最新的Ampere架构在图形处理、AI、光线追踪等性能上又有进一步的提升。
NVIDIA 中国区高级技术市场经理施澄秋表示:“在过去20年里,NVIDIA在各式各样的图形和可视化运算及AI等不同领域,都针对GPU做出相应优化。NVIDIA GPU无论是在软硬件设计,还是功能改进,都针对不同用户产生了不同性能飞跃,包括现在很流行的AEC、BIM、CAM等。”
此外,NVIDIA还带来了全新Omniverse平台的秋季更新,有了这套平台,分散在各地的远程团队,能够同时针对特定的设计项目来进行协同作业。
Ampere架构GPU带来了什么
我们发现,在发布全新的RTX A6000系列显卡时,与此前的“Tesla”一样,“Quadro”品牌也被NVIDIA淡化了。NVIDIA没有对变更名称给出官方的解释,笔者认为主要是因为目前图形卡、计算卡的界限渐渐地模糊,产品线之间的重合度越来越高造成的,这也可以理解为NVIDIA未来的GPU产品线突破了自己“画的圈”,更加“野蛮”地生长。
随着Ampere架构的发布,NVIDIA进一步提升在GPU领域中主导地位,新架构与前代Turing相比有三大优势:
一、新一代的SM(新一代流式多处理器)架构最高可以提供39 TFLOPS的FP32算力。
二、第二代RT Core相对于第一代Turing架构里的RT Core最高可以提供76 TFLOPS光线追踪算力。和以往GPU不同的是除了SM之外,加入了RT Core、Tensor Core,该张量运算核心主要是针对AI里面最有倚重、最主要的运算单元Tensor Core。
三、新架构产品最多可以提供310个Tensor TFLOPS的算力。
NVIDIA Ampere架构和上一代Turing架构相比最重要的就是SM以及传统图形运算核心采用全新设计,进行全新增强,并采用基于全新架构及设计第二代RT Core及第三代Tensor core,使得RTX A6000在性能、AI、光线追踪等方面获得了非常大的增强。
施澄秋表示:“其实就CAD、CAM或者模拟,以及整个大型复杂零组件装配等工作来说,对于GPU的依赖程度非常高。企业去设计一款产品,产品本身可能对于用户而言只是一个最终拿到手上的物品,但生产制造设计人员其实经历了非常多的繁琐、冗长的步骤。”
也的确如此,比如设计一款产品要经过选择材质、考虑材质的牢固程度、材质的耐磨损程度、材质使用过程中的舒适程度以及美观程度,还要考虑产品是否符合人体工学等等一系列的设计和制造流程。在过程中要花费设计人员相当多的时间与精力。
而在使用高性能的RTX A6000或A40时,就可以帮助大家节约很多的工作时长、能够大幅提升工作流程和效率,优化每一个步骤。这样的过程中,其实NVIDIA专业可视化显卡一直以来都是生产类工具。
对于采用A6000的实例,美国NASA给出了一个评价很有意思,他们觉得新一代Ampere架构的A6000与双路的上一代旗舰级别的RTX8000运算能力差不多,而且,功耗、散热、噪音以及管理成本都下降不少,这足以说明Ampere架构的提升。
让远程协助更简单
今年的疫情改变了很多人的工作方式,其中就包括创意工作者以及开发人员。
一直以来,设计人员为了创建视觉效果、建筑可视化和制造设计,需要不同团队协作,并且,在设计完成之后还需要多个客户进行审查。
由于不同的文件格式、所有权、软件和团队不连通等问题,不同软件之间无法建立联系,不但会导致信息延迟,在某些情况下还会影响效率甚至阻碍工作的完成。Omniverse能够让不同的设计师使用不同的工具,无缝地完成同一个设计项目的不同部分。
在Omniverse推出之后,另一个关键创新是仅需一键点击即可在Autodesk.Revit、McNeel.Rhino或Trimble.SketchUp之间进行切换。用户无需进行数据准备或抽样,就能使用兼容的照片级逼真的渲染软件浏览大型模型。这就避免了转化延迟和切换软件工具造成的错误,大量节省了时间和成本。
此外,Omniverse还更好地对光线追踪进行支持,可以把实时光线追踪的能力带到任何一个设备上。我们以前给客户做演示的时候会拿一个手机或者平板电脑,客户可能只会看到一张图或者一个视频,既不可交互也不能改变视角。
借助Omniverse平台,设计师可以用流媒体的方式把设计程序,甚至整套流程串流到任何一个设备上。只需一台平板电脑/手机/上网本/轻型笔记本,就可以给客户进行演示,而且还可以得到实时反馈,让客户看到当前设计的状况,甚至可以利用AR/VR的方式让用户更真实的体验你所使用地应用程序。
如果Omniverse平台有RTX A6000显卡加持,会创造出什么样的画面呢?在NVIDIA刚刚放出来的夜间版《Marbles》便是这两者合体的杰作,施澄秋介绍:“视频中物体的摩擦、弹跳、互动,包括里面不同位置的声音全部由NVIDIA Ampere架构的技术来完成。该视频制作者来自超过12个团队,几十个工程师和设计师分散在全世界各个地方,实时利用NVIDIA Omniverse和NVIDIA RTX Ampere架构GPU完成了这一艺术创举。”
写在最后
在Turing架构推出三年之后,NVIDIA为大家带来了更加强悍的Ampere架构,让我们再一次感受到GPU性能的提升,而且二代RT Core、Tensor Core的引入对全新光线追踪和AI性能的加强也让其成为更出色的生产工具。
今年7月NVIDIA市值达到2513亿美元,首度超越Intel成为美国市值最高半导体公司,截止至目前,其市值更突破3000亿美元大关,在NVIDIA刚刚发布的第三季度财报中,创下收入47.3亿美元的记录。一个个记录随时间迁移不断被打破,未来还会发生什么?我们非常期待。
责任编辑:YYX
-
NVIDIA
+关注
关注
14文章
4576浏览量
101635 -
gpu
+关注
关注
27文章
4400浏览量
126541 -
Ampere
+关注
关注
1文章
54浏览量
4501
发布评论请先 登录
相关推荐
全新NVIDIA RTX A400和A1000 GPU全面加强AI设计与生产力工作流
FPGA在深度学习应用中或将取代GPU
深入解读AMD最新GPU架构
揭秘GPU: 高端GPU架构设计的挑战

NVIDIA GPU的核心架构及架构演进
对英伟达A100芯片算力服务收费价格上调100%,这家企业的硬气来自哪里?

Ampere推出全新软件迁移工具Ampere Porting Advisor
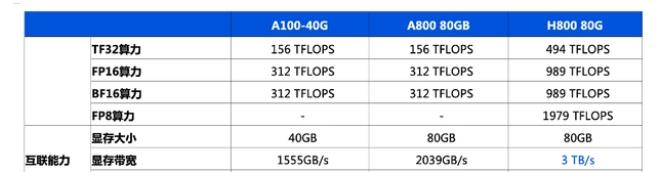
Gaudi2架构和软件的全面解释
基于磁贴的GPU架构优缺点
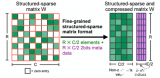
NVIDIA Ampere 架构的结构化稀疏功能及其在搜索引擎中的应用
Ampere Altra系列处理器的锁和内存序

Ampere全新AmpereOne系列处理器,多达192个单线程Ampere核
Ampere Computing发布全新AmpereOne系列处理器,192个自研核
大模型训练,英伟达Turing、Ampere和Hopper算力分析






 工商网监
工商网监
评论