 基于主动学习的半监督图神经网络模型来对分子性质进行预测方法
基于主动学习的半监督图神经网络模型来对分子性质进行预测方法
1 引言
最近,越来越多的研究开始将深度学习方法应用到图数据领域。图神经网络在数据具有明确关系的结构场景,如物理系统,分子结构和知识图谱中有着广泛的研究价值和应用前景,本文将介绍在KDD 2020上发表的两个在这一场景下的最新工作。
第一个工作是Research Track的《ASGN: An Active Semi-supervised Graph Neural Network for Molecular Property Prediction》,提出了一种基于主动学习的半监督图神经网络模型来对分子性质进行预测方法。
第二个工作是Research Track的《Hierarchical Attention Propagation for Healthcare Representation Learning》,基于注意力机制,提出了一种利用的层次信息表示医学本体的表示学习模型。
2 ASGN: An Active Semi-supervised Graph Neural Network for Molecular Property Prediction
2.1 动机与贡献
分子性质(如能量)预测是化学和生物学中的一个重要问题。遗憾的是,许多监督学习方法都存在着标记分子在化学空间中稀缺的问题,而这类属性标记通常是通过密度泛函理论(DFT)计算得到的,计算量非常大。一个有效的解决方案是使用半监督方法使未标记的分子也能参与训练。然而,学习大量分子的半监督表示具有挑战性,存在包括分子本质和结构的联合表征,表征与属性学习的冲突等问题。本文作者提出了一个新的框架,结合了标记和未标记的分子来预测分子性质,称为主动半监督图神经网络(ASGN)。
2.2 模型
本文提出了一种新的主动半监督图神经网络(ASGN)框架,通过在化学空间中合并标记和未标记的分子来预测分子的性质。总体框架如图2所示。
总体来讲,本文使用教师模型和学生模型来迭代训练。每个模型都是一个图神经网络。在教师模型中,使用半监督的方式来获得分子图的一般表示。我们联合训练分子的无监督表示和基于属性预测的embedding。在学生模型中,通过微调教师模型中的参数来处理损失冲突。之后,再使用学生模型为未标记的数据集分配伪标签。作为对教师模型的反馈,教师模型可以从这些伪标签中学习学生模型学到的知识。同时,为了提高标记效率,作者使用了主动学习来选择新的有代表性的未标记分子进行标记。然后再将它们添加到标记的集合中,并反复fine-tune两个模型,直到达到预设精度。整个模型的核心思想是利用教师模型输出的embedding来寻找整个未标记集合中最具有多样化性质的子集,然后再使用DFT等方法给这些分子分配基本的真值标签。之后,将它们添加到标签集中,并重复迭代以提高性能。
2.2.1 教师模型
在教师模型中,本文采用了半监督学习方式。教师模型的损失函数由三部分组成,一个具有标记的分子的性质损失函数和两个无监督损失函数(分别从节点和图层面)。
(1) 本文使用了一种消息传递图神经网络(MPGNN),先将分子图转化为基于消息传递图神经网络的表示向量,之后在预测和标记(即中的标记属性)之间使用均方损失(MSE)来指导模型参数的优化
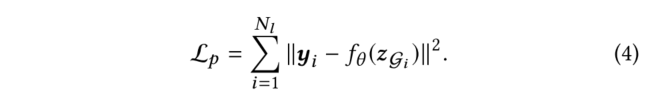
(2)在节点级表示学习中,模型主要学习从分子图的几何信息中获取领域知识。其主要思想是使用node embedding从表示中重建节点类型和拓扑(节点之间的距离)。具体地说,我们首先从图2所示的图中对一些节点和边进行随机采样,然后将这些节点的表示传递给MLP,并用它们重建节点类型和节点间的距离。从数学上讲,本文最小化了以下交叉熵:
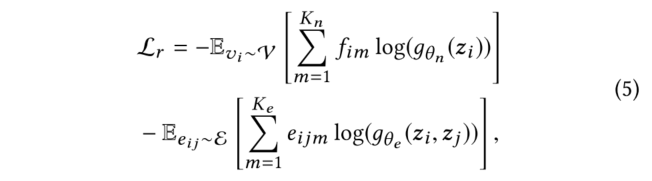
(3)虽然能够重构分子拓扑结构的节点嵌入可以有效地表示分子的结构,然而结合图级表示学习对属性预测等下游任务也是有益的。为了学习图级表示,关键是利用化学空间中分子之间的相互关系,即相似的分子具有相似的性质。本文提出了一种基于学习聚类的图级表示方法。首先,计算网络的图级embedding。然后,我们使用一种基于隐式聚类的方法来为每个分子分配一个由隐式聚类过程生成的聚类ID,然后利用一个惩罚损失函数对模型进行优化,该过程迭代进行直到达到局部最小值。
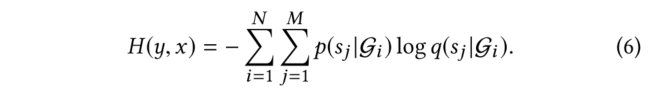
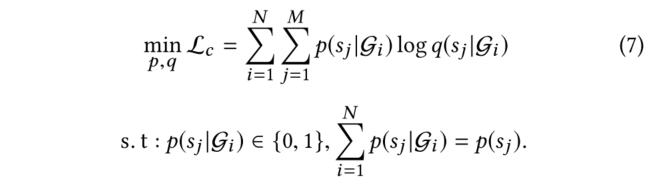
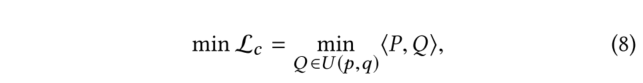
(4)总LOSS:
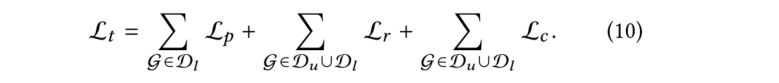
2.2.2 学生模型
在实际应用中,直接优化教师模型中的公式(10)对属性预测的结果并不理想。由于教师模型中的优化目标之间存在冲突,每个联合优化目标的性能都比单独优化的性能要差。尤其是当带标记分子远少于无标记分子时,模型很少关注一个epoch内对的优化,但对于分子性质的预测是本文最关心的问题。因此,与只需学习分子性质的模型相比,教师模型对于分子预测的损失要高得多。为了缓解这个问题,本文引入了一个学生模型。具体过程为:使用教师模型,通过共同优化上述对象函数来学习分子表示,当教师模型的学习过程结束时,我们将教师模型的权重转移到学生模型上,并使用学生模型仅对标记的数据集进行fine-tuning,以学习与图2所示公式(4)相同的分子性质:
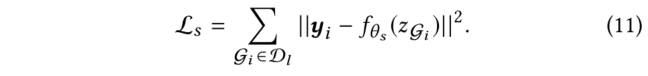
在fine-tuning之后,我们使用学生模型来推断整个未标记的数据集,并为每个未标记的数据分配一个伪标签,表示学生对其性质的预测,未标记的数据集为
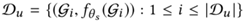
,其中为学生模型的参数。在下一次迭代中,教师模型还需要学习这样的伪标签,公式(10)变成:
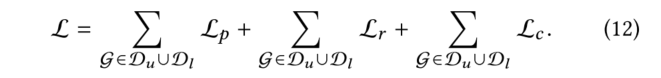
2.2.3 使用主动学习进行数据选择
在模型中本文已经把这些信息包括在有标记和未标记的分子中。然而,由于可用标签数量有限,准确度仍可能不尽如人意,所以需要寻找新的标签数据来提高其性能。因此,在每一次迭代中,我们使用教师模型输出的embedding迭代地选择一个分子子集,并通过DFT计算其性质(真值标签)。然后我们将这些通过主动学习输出的分子加入到标记集中,以迭代的方式微调两个模型。主动学习的关键策略是在化学空间中中找到一小批最多样化的分子来进行标记。一个经过充分研究的测量多样性的方法是从k-DPP中取样。然而,由于子集选择是NP难的,因此本文采用了贪婪近似,即k-中心法。用表示未标记的数据集,用表示有标记的数据集,我们采用一种贪婪的方法,在每次迭代中选择一个子集,使标记集和未标记集之间的距离最大化。具体来说,对于第k批中的每个0
是两个分子之间的距离。
2.3 实验
2.3.1 实验设置
• Datasets:
(1) QM9: 130,000 molecules, <9 heavy atoms
(2) OPV: 100,000 medium sized molecules
• Properties (All calculated by DFT)
(1) QM9:
(2) OPV:
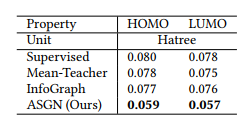
2.3.2 实验结果
Results on QM9
Results on OPV
3 Hierarchical Attention Propagation for Healthcare Representation Learning
3.1 动机与贡献
医学本体论被广泛用于表示和组织医学术语。例如ICD-9、ICD-10、UMLS等。本体论通常以层次结构构建,编码不同医学概念之间的多层次子类关系,允许概念之间有非常细微的区别。医学本体论为将领域知识整合到医疗预测系统中提供了一个很好的途径,并可以缓解数据不足的问题,提高稀有类别的预测性能。为了整合这些领域知识,Gram是一种最新的图形注意力模型,它通过一种注意机制将医学概念表示为其祖先embedding到本体中的加权和。尽管表现出了不错的性能,但Gram只考虑了概念的无序祖先,没有充分地利用层次结构,因此表达能力有限。在本文中,我们提出了一种新的医学本体嵌入模型HAP,该模型将注意力分层地传播到整个本体结构中,医学概念自适应地从层次结构中的所有其他概念学习其embedding,而不仅仅是它的祖先。本文证明了HAP能够学习到更具表现力的医学概念embedding——从任意医学概念embedding中能够完全还原整个本体结构。在两个序列程序/诊断预测任务上的实验结果表明,HAP的embedding质量优于Gram和其他baseline。此外,本文发现使用完整的本体并不总是最好的。有时只使用较低层次的概念比使用所有层次的效果要好。
3.2 模型
本文提出了一种新的医学本体嵌入方法:
1)充分层次化知识的DAG(有向无环图)
2)尊重层次内节点的有序性。
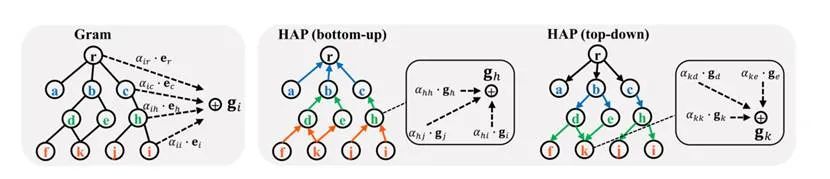
HAP对模型进行两轮信息传播,更新每一级节点的嵌入:第一次是自下而上的传播,第二次是自上而下的传播。
假设本体节点有L层,其中第一层只包括单个根节点,第L层只有叶子医疗代码。第2,3,……L −1层可以包含中间类别节点或叶医疗代码(因为某些医疗代码没有完整的L层)。一开始,每个节点的embedding是由一个基本embedding 初始化的。在自底向上的信息传播中,我们从第L-1层开始依次更新节点的embedding,直到第一层。对于第层的某一节点,本文通过使用注意力机制自适应地将当前embedding与第层的其子级embedding相结合来更新其embedding :
其中表示开始更新-1层节点前节点的embedding,表示embedding大小。注意力权重的计算公式为:
其中是一个用于计算和之间标量原始注意力的MLP。
自下而上的传播从第二层直到根节点为止。同一级别的节点更新可以并行执行,而上层节点的更新必须等到其所有较低级别都已更新为止。给定由自下而上传播计算的embedding,HAP以自顶向下的方式执行第二轮传播。具体地说,我们从第二层,第三层……直到第L层顺序更新节点的embedding。对于来自第-1层的节点,使用一个使用一个类似的注意力机制自适应地将当前节点的embedding与来自第层的其父级embedding相结合来更新其embedding :
其中表示开始更新+1层节点前节点的embedding。注意力权重的计算公式为:
最后,在两轮传播之后,每个节点都将其注意力传播到整个知识DAG中。因此,每个节点的最终嵌入不仅有效地吸收了其祖先的知识,还吸收了其后代、兄弟姐妹,甚至一些遥远节点的知识。此外,由于传播顺序与层次结构严格一致,因此保留了节点排序信息。例如,在自顶向下的传播阶段,节点的祖先按顺序逐级向下传递信息,而不是像(1)中那样一次性传递信息。这使得HAP能够从不同层次上区分祖先/后代,并对排序信息进行编码。
最终的医学代码嵌入用于顺序程序/诊断预测任务。在之后,本文采用了端到端的RNN框架。将最终得到的embedding , ,…… 以列的形式进行拼接得到embedding矩阵 ,注意一个访问记录可以被表示为multi-hot向量。为了对于每一个属于的医学代码都得到一个embedding向量,本文用与相乘并使用一个非线性变换:
之后我们依次将,,……,输入RNN中,并对每一个访问输出一个中间隐藏态,隐藏状态是通过过去所有的时间戳直到到t的访问给出的:
之后,对于下一时间戳的预测由下式给出:
我们使用分批梯度下降来最小化所有时间戳(除了时间戳1)的预测损失。单个患者的预测损失由下式得出:
3.3 实验
数据集设置:
结果:
•HAP (lv3): 所提出的HAP模型只使用最低的3个层次。也就是说,自下而上的传播在L-2层停止,自顶向下的传播也从L-2层开始。可以发现有时只使用较低层次的层次,就可以提供足够的领域知识,同时降低了计算复杂度。
• HAP (lv2): HAP模型只使用最低的2个层次.
责任编辑:lq
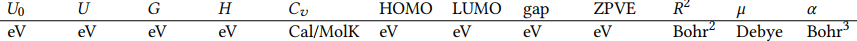


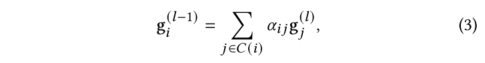
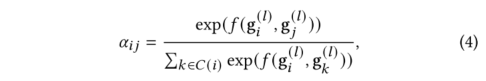
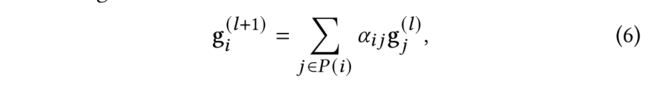
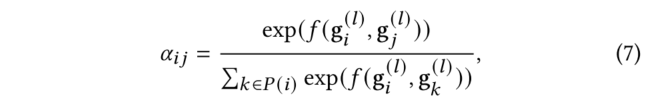
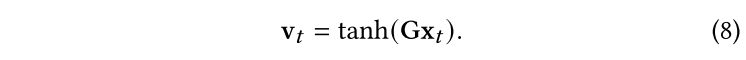
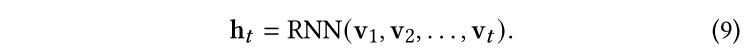
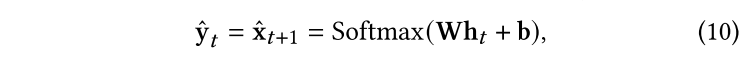
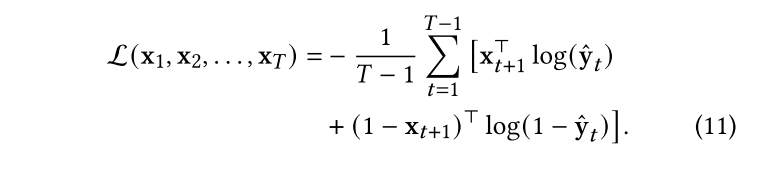
-
神经网络
+关注
关注
42文章
4570浏览量
98702 -
函数
+关注
关注
3文章
3861浏览量
61303 -
模型
+关注
关注
1文章
2704浏览量
47667
原文标题:【KDD20】图神经网络在生物医药领域的应用
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
构建神经网络模型的常用方法 神经网络模型的常用算法介绍
人工神经网络和bp神经网络的区别
卷积神经网络模型的优缺点
卷积神经网络模型搭建
常见的卷积神经网络模型 典型的卷积神经网络模型
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别
卷积神经网络模型有哪些?卷积神经网络包括哪几层内容?
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法
神经网络模型用于解决什么样的问题 神经网络模型有哪些
如何使用TensorFlow将神经网络模型部署到移动或嵌入式设备上
什么是神经网络?为什么说神经网络很重要?神经网络如何工作?





 工商网监
工商网监
评论