 运用多种机器学习方法比较短文本分类处理过程与结果差别
运用多种机器学习方法比较短文本分类处理过程与结果差别
目标
从头开始实践中文短文本分类,记录一下实验流程与遇到的坑运用多种机器学习(深度学习 + 传统机器学习)方法比较短文本分类处理过程与结果差别
工具
深度学习:keras
传统机器学习:sklearn
参与比较的机器学习方法
CNN 、 CNN + word2vec
LSTM 、 LSTM + word2vec
MLP(多层感知机)
朴素贝叶斯
KNN
SVM
SVM + word2vec 、SVM + doc2vec
第 1-3 组属于深度学习方法,第 4-6 组属于传统机器学习方法,第 7 组算是种深度与传统合作的方法,画风清奇,拿来试试看看效果
源代码、数据、word2vec模型下载
github:https://github.com/wavewangyue/text-classification
word2vec模型文件(使用百度百科文本预训练)下载:https://pan.baidu.com/s/13QWrN-9aayTTo0KKuAHMhw;提取码 biwh
数据集:搜狗实验室 搜狐新闻数据 下载地址:http://www.sogou.com/labs/resource/cs.php
先上结果
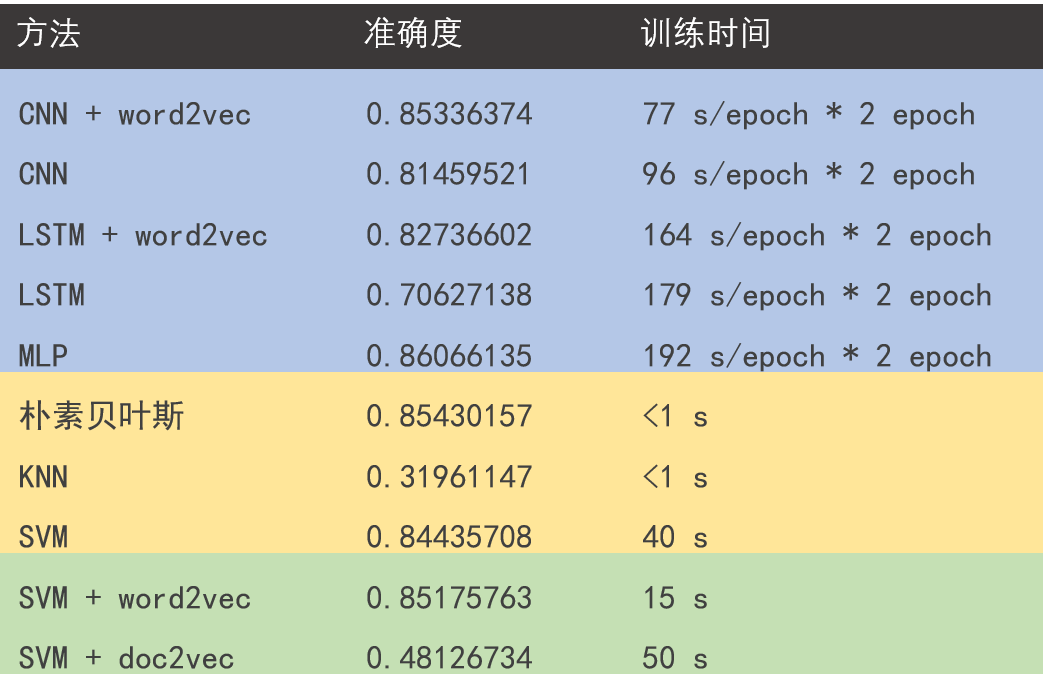
实验结论
引入预训练的 word2vec 模型会给训练带来好处,具体来说:(1)间接引入外部训练数据,防止过拟合;(2)减少需要训练的参数个数,提高训练效率
LSTM 需要训练的参数个数远小于 CNN,但训练时间大于 CNN。CNN 在分类问题的表现上一直很好,无论是图像还是文本;而想让 LSTM 优势得到发挥,首先让训练数据量得到保证
将单词在 word2vec 中的词向量加和求平均获得整个句子的语义向量的方法看似 naive 有时真挺奏效,当然仅限于短句子,长度 100 以内应该问题不大
机器学习方法万千,具体选择用什么样的方法还是要取决于数据集的规模以及问题本身的复杂度,对于复杂程度一般的问题,看似简单的方法有可能是坠吼地
干货上完了,下面是实验的具体流程
0 数据预处理
将下载的原始数据进行转码,然后给文本标类别的标签,然后制作训练与测试数据,然后控制文本长度,分词,去标点符号
哎,坑多,费事,比较麻烦
首先,搜狗实验室提供的数据下载下来是 xml 格式,并且是 GBK (万恶之源)编码,需要转成 UTF8,并整理成 json 方便处理。原始数据长这个样:

这么大的数据量,怎么转码呢?先尝试利用 python 先读入数据然后转码再保存,可傲娇 python 并不喜欢执行这种语句。。。再尝试利用 vim 的 :set fileencoding=utf-8,乱码从███变成锟斤拷。。。
经过几次尝试,菜鸡的我只能通过文本编辑器打开,然后利用文本编辑器转换编码。这样问题来了,文件大小1.6G,记事本就不提了,Notepad 和 Editplus 也都纷纷阵亡。。。
还好最后发现了 UltraEdit,不但可以打开,速度简直飞起来,转码后再整理成的 json 长这个样子:
UltraEdit 就是好就是秒就是呱呱叫
搜狗新闻的数据没有直接提供分类,而是得通过新闻来源网址的 url 来查其对应得分类,比如 http://gongyi.sohu.com 的 url 前缀对应的新闻类型就是“公益类”。对着他提供的对照表查,1410000+的总数据,成功标出来的有510000+,标不出来的新闻基本都来自 http://roll.sohu.com,这是搜狐的滚动新闻,乱七八糟大杂烩,难以确定是什么类
对成功标出来的15个类的新闻,统计一下类别的分布,结果如下:
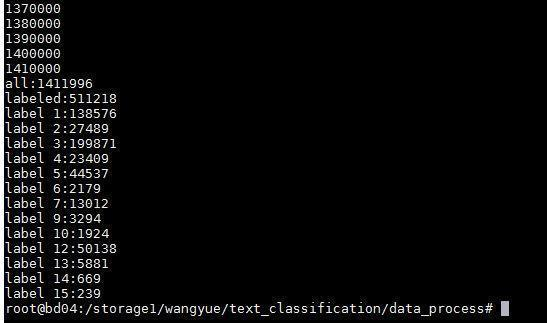
分布比较不均,第 14 类和第 15 类的新闻很少,另外第 8 类和第 11 类一个新闻也没有
所以最后选了剩下的11个类,每个类抽2000个新闻,按4:1分成训练与测试,如图
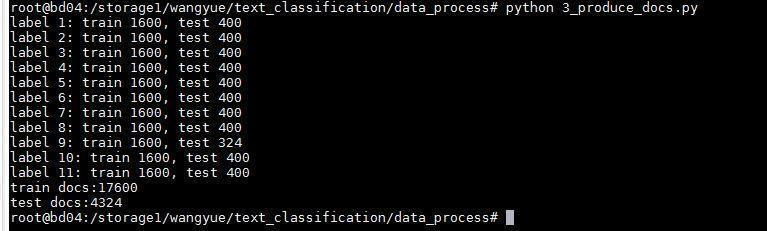
11个类分别是
对这些新闻的长度进行统计结果如下:
横轴是新闻的长度,纵轴是拥有此长度的新闻数量。在长度为500字和1600字时突然两个峰,猜测是搜狐新闻的一些长度限制???
长度0-100的放大观察,分布还可以,说明如果基于这套数据做短文本分类,需要对原始文本进行固定长度的截取,长度 100 可能是个不错的选择
上一步选出来的训练新闻长这样,因为考虑到新闻标题的意义重大,这里就将新闻标题和新闻内容接到一起,用空格隔开,然后截取每条新闻的前 100 个字

一行是一条新闻,训练数据17600行,测试数据4324行。然后用jieba分词,分词后利用词性标注结果,把词性为‘x’(字符串)的去掉,就完成了去标点符号

jieba真是好真是秒真是呱呱叫
最后得到以下结果文件:(1)新闻文本数据,每行 1 条新闻,每条新闻由若干个词组成,词之间以空格隔开,训练文本 17600 行,测试文本 4324 行;(2)新闻标签数据,每行 1 个数字,对应这条新闻所属的类别编号,训练标签 17600行,测试标签 4324 行
1 CNN
深度学习用的 keras 工具,操作简单易懂,模型上手飞快,居家旅行必备。keras 后端用的 Tensorflow,虽然用什么都一样
不使用预训练 word2vec 模型的 CNN:
首先一些先设定一些会用到的参数
MAX_SEQUENCE_LENGTH=100#每条新闻最大长度 EMBEDDING_DIM=200#词向量空间维度 VALIDATION_SPLIT=0.16#验证集比例 TEST_SPLIT=0.2#测试集比例
第一步先把训练与测试数据放在一起提取特征,使用 keras 的 Tokenizer 来实现,将新闻文档处理成单词索引序列,单词与序号之间的对应关系靠单词的索引表 word_index 来记录,这里从所有新闻中提取到 65604 个单词,比如 [苟,国家,生死] 就变成了 [1024, 666, 233] ;然后将长度不足 100 的新闻用 0 填充(在前端填充),用 keras 的 pad_sequences 实现;最后将标签处理成 one-hot 向量,比如 6 变成了 [0,0,0,0,0,0,1,0,0,0,0,0,0],用 keras 的 to_categorical 实现
fromkeras.preprocessing.textimportTokenizer fromkeras.preprocessing.sequenceimportpad_sequences fromkeras.utilsimportto_categorical importnumpyasnp tokenizer=Tokenizer() tokenizer.fit_on_texts(all_texts) sequences=tokenizer.texts_to_sequences(all_texts) word_index=tokenizer.word_index print('Found%suniquetokens.'%len(word_index)) data=pad_sequences(sequences,maxlen=MAX_SEQUENCE_LENGTH) labels=to_categorical(np.asarray(all_labels)) print('Shapeofdatatensor:',data.shape) print('Shapeoflabeltensor:',labels.shape)
再将处理后的新闻数据按 6.4:1.6:2 分为训练集,验证集,测试集
p1=int(len(data)*(1-VALIDATION_SPLIT-TEST_SPLIT)) p2=int(len(data)*(1-TEST_SPLIT)) x_train=data[:p1] y_train=labels[:p1] x_val=data[p1:p2] y_val=labels[p1:p2] x_test=data[p2:] y_test=labels[p2:] print'traindocs:'+str(len(x_train)) print'valdocs:'+str(len(x_val)) print'testdocs:'+str(len(x_test))
然后就是搭建模型,首先是一个将文本处理成向量的 embedding 层,这样每个新闻文档被处理成一个 100 x 200 的二维向量,100 是每条新闻的固定长度,每一行的长度为 200 的行向量代表这个单词在空间中的词向量。下面通过 1 层卷积层与池化层来缩小向量长度,再加一层 Flatten 层将 2 维向量压缩到 1 维,最后通过两层 Dense(全连接层)将向量长度收缩到 12 上,对应新闻分类的 12 个类(其实只有 11 个类,标签 0 没有用到)。搭完收工,最后,训练模型,测试模型,一鼓作气,攻下高地。
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportConv1D,MaxPooling1D,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(Embedding(len(word_index)+1,EMBEDDING_DIM,input_length=MAX_SEQUENCE_LENGTH)) model.add(Dropout(0.2)) model.add(Conv1D(250,3,padding='valid',activation='relu',strides=1)) model.add(MaxPooling1D(3)) model.add(Flatten()) model.add(Dense(EMBEDDING_DIM,activation='relu')) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
模型长这个样子
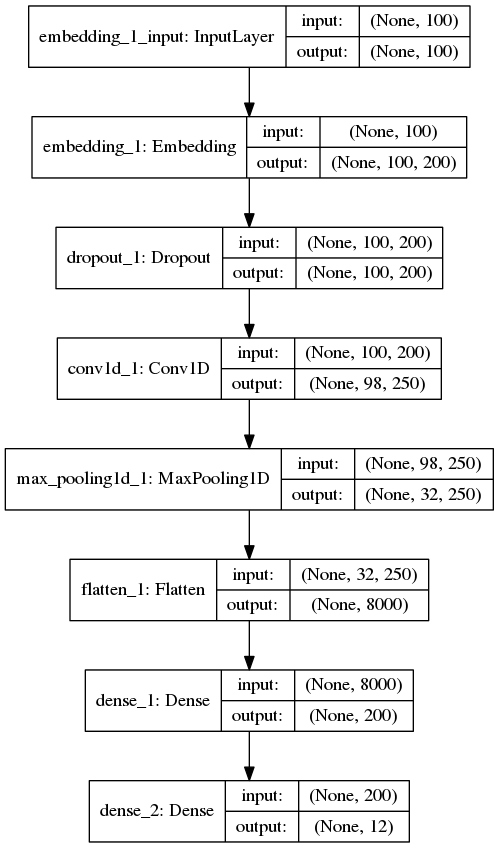
问:这里只使用了 1 层卷积层,为什么不多加几层?
答:新闻长度只有100个单词,即特征只有100维,1 层卷积加池化后特征已经缩减为 32 维,再加卷积可能就卷没了。2 层 3 层也做过,效果都不好
问:为什么只训练 2 轮
答:问题比较简单,1 轮训练已经收敛,实验表明第 2 轮训练基本没什么提升
问:为什么卷积核为什么选择 250 个?
答:因为开心
实验结果如下
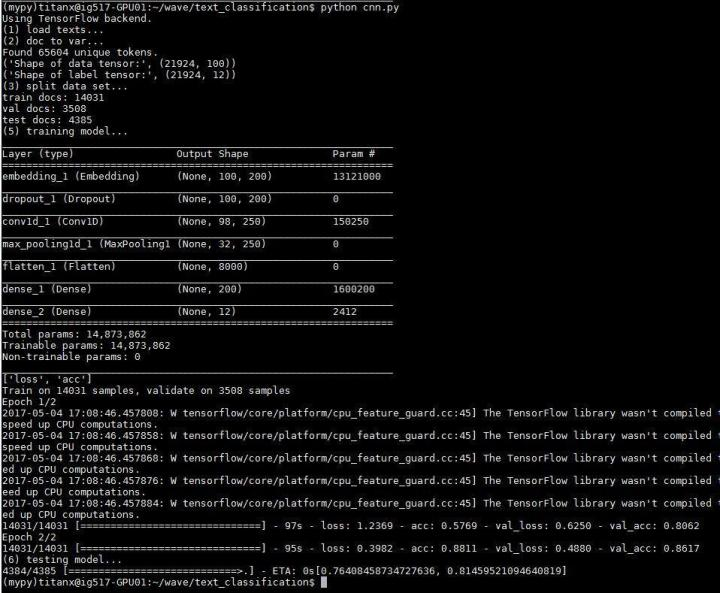
准确度 0.81459521
拥有11个分类的问题达到这个准确度,应该也不错(易满足)。并且搜狗给的数据本来也不是很好(甩锅)。可以看到在训练集上的准确度达到了 0.88,但是测试集上的准确度只有 0.81,说明还是有些过拟合。另外,整个模型需要训练的参数接近 1500 万,其中 1300 万都是 embedding 层的参数,说明如果利用 word2vec 模型替换 embedding 层,解放这 1300 万参数,肯定会让训练效率得到提高
基于预训练的 word2vec 的 CNN :
keras示例程序 pretrained_word_embeddings.py 代码地址https://github.com/fchollet/keras/blob/master/examples/pretrained_word_embeddings.py
中文讲解地址(在Keras模型中使用预训练的词向量)http://keras-cn.readthedocs.io/en/latest/blog/word_embedding/
既然提到了 word2vec 可能会提高训练效率,那就用实验验证一下。(重点)(重点)(重点)正常的深度学习训练,比如上面的 CNN 模型,第一层(除去 Input 层)是一个将文本处理成向量的 embedding 层。这里为了使用预训练的 word2vec 来代替这个 embedding 层,就需要将 embedding 层的 1312 万个参数用 word2vec 模型中的词向量替换。替换后的 embedding 矩阵形状为 65604 x 200,65604 行代表 65604 个单词,每一行的这长度 200 的行向量对应这个词在 word2vec 空间中的 200 维向量。最后,设定 embedding 层的参数固定,不参加训练,这样就把预训练的 word2vec 嵌入到了深度学习的模型之中
VECTOR_DIR='wiki.zh.vector.bin'#词向量模型文件 fromkeras.utilsimportplot_model fromkeras.layersimportEmbedding importgensim w2v_model=gensim.models.KeyedVectors.load_word2vec_format(VECTOR_DIR,binary=True) embedding_matrix=np.zeros((len(word_index)+1,EMBEDDING_DIM)) forword,iinword_index.items(): ifunicode(word)inw2v_model: embedding_matrix[i]=np.asarray(w2v_model[unicode(word)], dtype='float32') embedding_layer=Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix], input_length=MAX_SEQUENCE_LENGTH, trainable=False)
模型搭建与刚才类似,就是用嵌入了 word2vec 的 embedding_layer 替换原来的 embedding 层
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportConv1D,MaxPooling1D,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(embedding_layer) model.add(Dropout(0.2)) model.add(Conv1D(250,3,padding='valid',activation='relu',strides=1)) model.add(MaxPooling1D(3)) model.add(Flatten()) model.add(Dense(EMBEDDING_DIM,activation='relu')) model.add(Dense(labels.shape[1],activation='softmax')) model.summary() #plot_model(model,to_file='model.png',show_shapes=True) model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['acc']) model.fit(x_train,y_train,validation_data=(x_val,y_val),epochs=2,batch_size=128) model.save('word_vector_cnn.h5') printmodel.evaluate(x_test,y_test)
模型长相跟之前一致,实验输出与测试结果如下
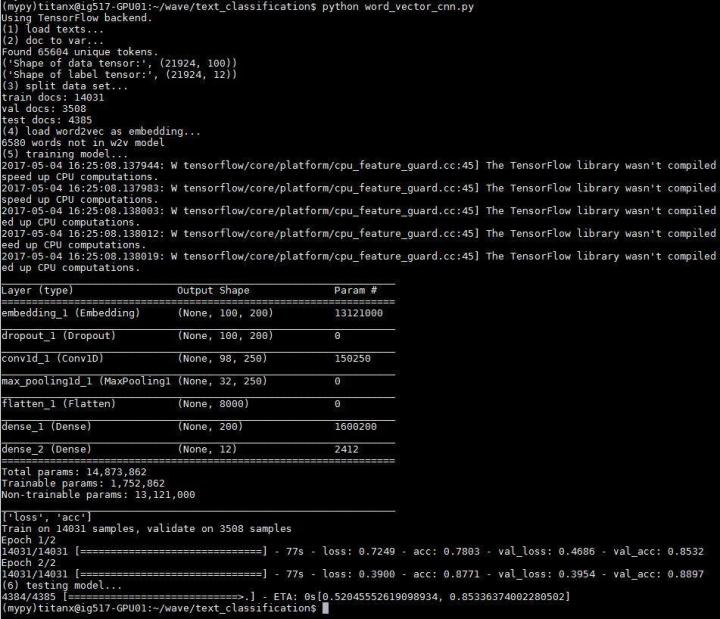
准确度 0.85336374
相比不使用 word2vec 的 cnn,过拟合的现象明显减轻,使准确度得到了提高。并且需要训练的参数大大减少了,使训练时间平均每轮减少 20s 左右
2 LSTM
终于到了自然语言处理界的大哥 LSTM 登场,还有点小期待
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportLSTM,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(Embedding(len(word_index)+1,EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH)) model.add(LSTM(200,dropout=0.2,recurrent_dropout=0.2)) model.add(Dropout(0.2)) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
模型长这样
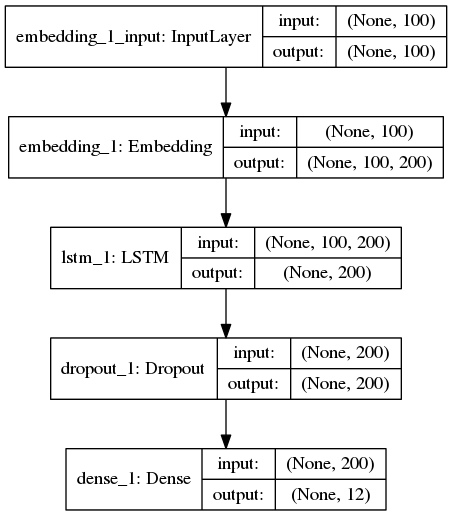
大哥开动!
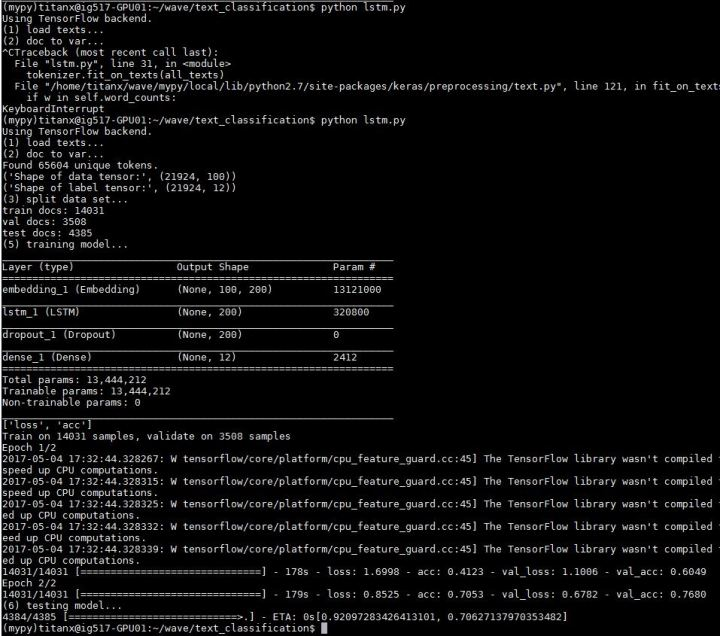
准确度 0.70627138
并没有期待中那么美好。。。原因是这点小数据量,并没有让 LSTM 发挥出它的优势。并不能给大哥一个奔驰的草原。。。并不能让大哥飞起来。。。另外使用 LSTM 需要训练的参数要比使用 CNN 少很多,但是训练时间是 CNN 的 2 倍。大哥表示不但飞不动,还飞的很累。。。
基于预训练的 word2vec 模型:
流程跟上面使用 word2vec 的 CNN 的基本一致,同样也是用嵌入了 word2vec 的 embedding_layer 替换原始的 embedding 层
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportLSTM,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(embedding_layer) model.add(LSTM(200,dropout=0.2,recurrent_dropout=0.2)) model.add(Dropout(0.2)) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
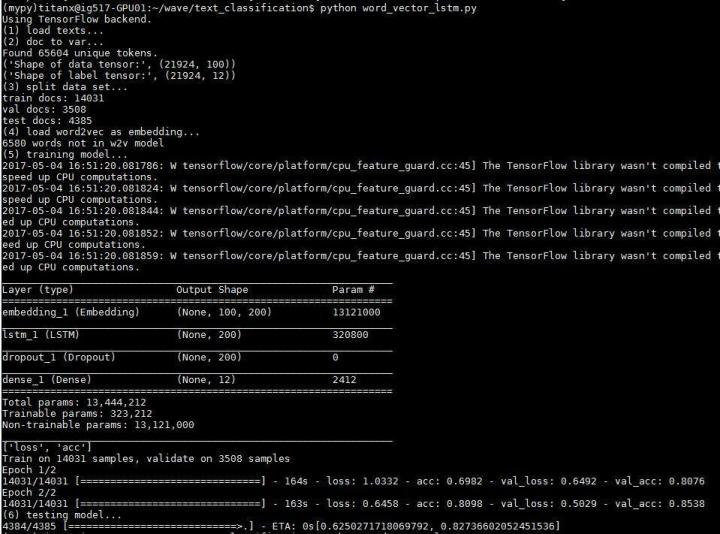
准确度 0.82736602
效果好了不少,依然存在过拟合现象,再一次说明了数据量对 LSTM 的重要性,使用预训练的 word2vec 模型等于间接增加了训练语料,所以在这次实验中崩坏的不是很严重
LP(多层感知机)
参考资料
keras 示例程序:reuters_mlp.py
代码地址:https://github.com/fchollet/keras/blob/master/examples/reuters_mlp.py
MLP 是一个结构上很简单很 naive 的神经网络。数据的处理流程也跟上面两个实验差不多,不过不再将每条新闻处理成 100 x 200 的 2 维向量,而是成为长度 65604 的 1 维向量。65604 代表数据集中所有出现的 65604 个单词,数据的值用 tf-idf 值填充,整个文档集成为一个用 17600 x 65604 个 tf-idf 值填充的矩阵,第 i 行 j 列的值表征了第 j 个单词在第 i 个文档中的的 tf-idf值(当然这里也可以不用 tf-idf 值,而只是使用 0/1 值填充, 0/1 代表第 j 个单词在第 i 个文档中是否出现,但是实验显示用 tf-idf 的效果更好)
tokenizer=Tokenizer() tokenizer.fit_on_texts(all_texts) sequences=tokenizer.texts_to_sequences(all_texts) word_index=tokenizer.word_index print('Found%suniquetokens.'%len(word_index)) data=tokenizer.sequences_to_matrix(sequences,mode='tfidf') labels=to_categorical(np.asarray(all_labels))
模型很简单,仅有两个全连接层组成,将长度 65604 的 1 维向量经过 2 次压缩成为长度 12 的 1 维向量
fromkeras.layersimportDense,Dropout fromkeras.modelsimportSequential model=Sequential() model.add(Dense(512,input_shape=(len(word_index)+1,),activation='relu')) model.add(Dropout(0.2)) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
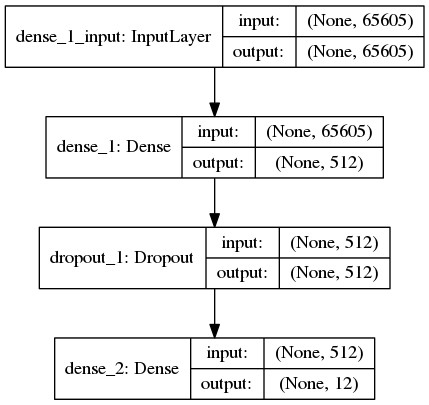
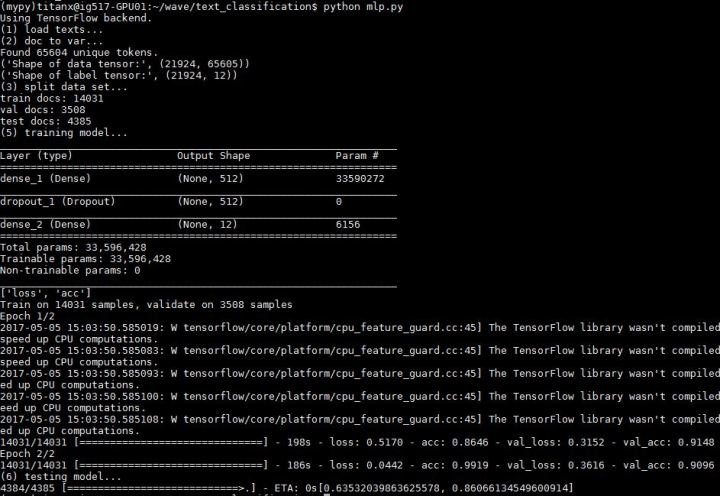
准确度 0.86066135
相比 CNN 与 LSTM 的最好成绩,虽然简单,但是依然 NB
只是不能像 CNN 与 LSTM 那样借助预训练 word2vec 的帮助,加上数据量不大,所以稍微有些过拟合,不过结果依旧很不错。没有复杂的 embedding,清新脱俗的传统感知机模型在这种小数据集的简单问题上表现非常好(虽然训练参数已经达到了 3300 万个,单轮耗时也将近 200s 了)
4 朴素贝叶斯
非深度学习方法这里使用 sklearn 来实践
首先登场的是朴素贝叶斯。数据处理的过程跟上述的 MLP 是一致的,也是将整个文档集用 tf-idf 值填充,让整个文档集成为一个 17600 x 65604 的 tf-idf 矩阵。这里需要使用 sklearn 的 CountVectorizer 与 TfidfTransformer 函数实现。代码如下
fromsklearn.feature_extraction.textimportCountVectorizer,TfidfTransformer count_v0=CountVectorizer(); counts_all=count_v0.fit_transform(all_text); count_v1=CountVectorizer(vocabulary=count_v0.vocabulary_); counts_train=count_v1.fit_transform(train_texts); print"theshapeoftrainis"+repr(counts_train.shape) count_v2=CountVectorizer(vocabulary=count_v0.vocabulary_); counts_test=count_v2.fit_transform(test_texts); print"theshapeoftestis"+repr(counts_test.shape) tfidftransformer=TfidfTransformer(); train_data=tfidftransformer.fit(counts_train).transform(counts_train); test_data=tfidftransformer.fit(counts_test).transform(counts_test);
这里有一个需要注意的地方,由于训练集和测试集分开提取特征会导致两者的特征空间不同,比如训练集里 “苟” 这个单词的序号是 1024,但是在测试集里序号就不同了,或者根本就不存在在测试集里。所以这里先用所有文档共同提取特征(counts_v0),然后利用得到的词典(counts_v0.vocabulary_)再分别给训练集和测试集提取特征。然后开始训练与测试
fromsklearn.naive_bayesimportMultinomialNB fromsklearnimportmetrics clf=MultinomialNB(alpha=0.01) clf.fit(x_train,y_train); preds=clf.predict(x_test); num=0 preds=preds.tolist() fori,predinenumerate(preds): ifint(pred)==int(y_test[i]): num+=1 print'precision_score:'+str(float(num)/len(preds))
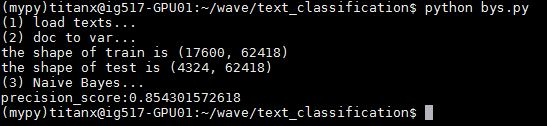
准确度 0.85430157
这只是一个简单的朴素贝叶斯方法,准确度高到惊人,果然最简单的有时候就是最有效的
5 KNN
跟上面基本一致,只是将 MultinomialNB 函数变成 KNeighborsClassifier 函数,直接上结果
fromsklearn.neighborsimportKNeighborsClassifier forxinrange(1,15): knnclf=KNeighborsClassifier(n_neighbors=x) knnclf.fit(x_train,y_train) preds=knnclf.predict(x_test); num=0 preds=preds.tolist() fori,predinenumerate(preds): ifint(pred)==int(y_test[i]): num+=1 print'K='+str(x)+',precision_score:'+str(float(num)/len(preds))
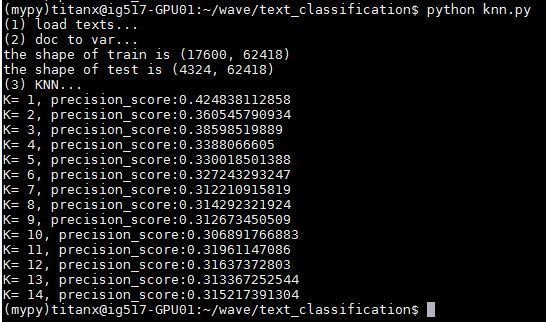
K=11时,准确度 0.31961147,非常低,说明 KNN 方法不太适合做此类问题
6 SVM
这里 svm 的 kernel 选用了线性核,其他的比如多项式核和高斯核也都试过,效果极差,直接上结果
fromsklearn.svmimportSVC svclf=SVC(kernel='linear') svclf.fit(x_train,y_train) preds=svclf.predict(x_test); num=0 preds=preds.tolist() fori,predinenumerate(preds): ifint(pred)==int(y_test[i]): num+=1 print'precision_score:'+str(float(num)/len(preds))
准确度 0.84435708,还是不错的,超过 LSTM ,不及 CNN 与 MLP
7 SVM + word2vec 与 doc2vec
这两个实验是后期新加入的,画风比较清奇,是骡是马溜一圈,就决定拿过来做个实验一起比较一下
svm + word2vec:
这个实验的主要思想是这样:原本每条新闻由若干个词组成,每个词在 word2vec 中都有由一个长度 200 的词向量表示,且这个词向量的位置是与词的语义相关联的。那么对于每一条新闻,将这条新闻中所有的词的词向量加和取平均,既能保留句子中所有单词的语义,又能生成一个蕴含着这句话的综合语义的“句向量”,再基于这个长度 200 的句向量使用 svm 分类。这个思想看起来很 naive,但是又说不出什么不合理的地方。尝试一下,代码与结果如下:
importgensim importnumpyasnp w2v_model=gensim.models.KeyedVectors.load_word2vec_format(VECTOR_DIR,binary=True) x_train=[] x_test=[] fortrain_docintrain_docs: words=train_doc.split('') vector=np.zeros(EMBEDDING_DIM) word_num=0 forwordinwords: ifunicode(word)inw2v_model: vector+=w2v_model[unicode(word)] word_num+=1 ifword_num>0: vector=vector/word_num x_train.append(vector) fortest_docintest_docs: words=test_doc.split('') vector=np.zeros(EMBEDDING_DIM) word_num=0 forwordinwords: ifunicode(word)inw2v_model: vector+=w2v_model[unicode(word)] word_num+=1 ifword_num>0: vector=vector/word_num x_test.append(vector)
准确度 0.85175763,惊了,这种看似很 naive 的方法竟然取得了非常好的效果。相比于之前所有包括 CNN、LSTM、MLP、SVM 等方法,这种方法有很强的优势。它不需要特征提取的过程,也不需固定新闻的长度,一个模型训练好,跨着数据集都能跑。但是也有其缺陷一面,比如忽略词语的前后关系,并且当句子长度较长时,求和取平均已经无法准确保留语义信息了。但是在短文本分类上的表现还是很亮
svm + doc2vec:
上面 svm + word2vec 的实验提到当句子很长时,简单求和取平均已经不能保证原来的语义信息了。偶然发现了 gensim 提供了一个 doc2vec 的模型,直接为文档量身训练“句向量”,神奇。具体原理不讲了(也不是很懂),直接给出使用方法
importgensim sentences=gensim.models.doc2vec.TaggedLineDocument('all_contents.txt') model=gensim.models.Doc2Vec(sentences,size=200,window=5,min_count=5) model.save('doc2vec.model') print'numofdocs:'+str(len(model.docvecs))
all_contents.txt 里是包括训练文档与测试文档在内的所有数据,同样每行 1 条新闻,由若干个词组成,词之间用空格隔开,先使用 gensim 的 TaggedLineDocument 函数预处理下,然后直接使用 Doc2Vec 函数开始训练,训练过程很快(可能因为数据少)。然后这所有 21924 篇新闻就变成了 21924 个长度 200 的向量,取出前 17600 个给 SVM 做分类训练,后 4324 个测试,代码和结果如下:
importgensim model=gensim.models.Doc2Vec.load('doc2vec.model') x_train=[] x_test=[] y_train=train_labels y_test=test_labels foridx,docvecinenumerate(model.docvecs): ifidx< 17600: x_train.append(docvec) else: x_test.append(docvec) print 'train doc shape: '+str(len(x_train))+' , '+str(len(x_train[0])) print 'test doc shape: '+str(len(x_test))+' , '+str(len(x_test[0])) from sklearn.svm import SVC svclf = SVC(kernel = 'rbf') svclf.fit(x_train,y_train) preds = svclf.predict(x_test); num = 0 preds = preds.tolist() for i,pred in enumerate(preds): if int(pred) == int(y_test[i]): num += 1 print 'precision_score:' + str(float(num) / len(preds))
准确度 0.48126734,惨不忍睹。原因可能就是文档太短,每个文档只有不超过 100 个词,导致对“句向量”的学习不准确,word2vec 模型训练需要 1G 以上的数据量,这里训练 doc2vec 模型20000个文档却只有 5M 的大小,所以崩坏
另外!这里对 doc2vec 的应用场景有一些疑问,如果我新加入一条新闻想要分类,那么我必须先要把这个新闻加到文档集里,然后重新对文档集进行 doc2vec 的训练,得到这个新新闻的文档向量,然后由于文档向量模型变了, svm 分类模型应该也需要重新训练了。所以需要自底向上把所有模型打破重建才能让为新文档分类?那实用性很差啊。也可能我理解有误,希望是这样
总结
总结放在开头了
打完收工
责任编辑:xj
原文标题:新闻上的文本分类:机器学习大乱斗
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
机器学习
+关注
关注
66文章
8095浏览量
130514 -
深度学习
+关注
关注
73文章
5221浏览量
119863 -
cnn
+关注
关注
3文章
326浏览量
21292
原文标题:新闻上的文本分类:机器学习大乱斗
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工智能中文本分类的基本原理和关键技术
stm32学习方法及资料
华为云 API 自然语言处理的魅力—AI 情感分析、文本分析
《电子工程师必备——九大系统电路识图宝典》+附录5学习方法
自然语言处理和人工智能的区别
chatgpt怎么用 ChatGPT的多种使用方法
华为云ModelArts入门开发(完成物体分类、物体检测)

NLP中的迁移学习:利用预训练模型进行文本分类

机器学习相关介绍:支持向量机(低维到高维的映射)





 工商网监
工商网监
评论