 基于点云的机器人抓取过程详解
基于点云的机器人抓取过程详解
机器人作为面向未来的智能制造重点技术,其具有可控性强、灵活性高以及配置柔性等优势,被广泛的应用于零件加工、协同搬运、物体抓取与部件装配等领域,如图1-1所示。然而,传统机器人系统大多都是在结构化环境中,通过离线编程的方式进行单一重复作业,已经无法满足人们在生产与生活中日益提升的智能化需求。随着计算机技术与传感器技术的不断发展,我们期望构建出拥有更加灵敏的感知系统与更加智慧的决策能力的智能化机器人系统。

图1-1 机器人的应用领域
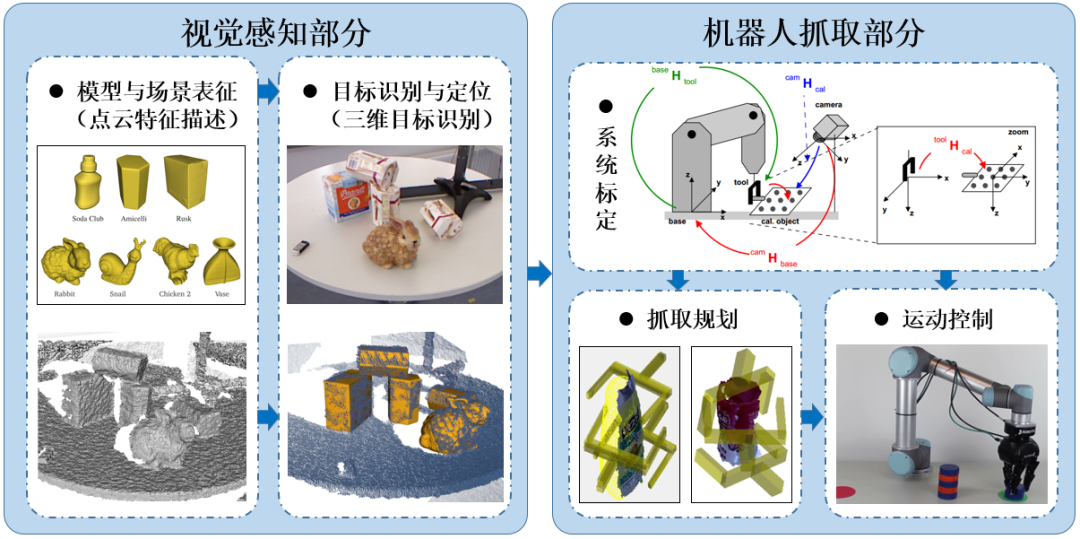
图1-2 机器人抓取的操作流程与步骤
机器人抓取与放置是智能化机器人系统的集中体现,也是生产与生活中十分重要的环节,近几年来在工业界与学术界得到了深入而广泛的研究。具体的机器人抓取可以分为视觉感知部分与机器人抓取操作部分。视觉感知部分又包含:模型与场景表征、目标识别与定位这两个步骤;而机器人抓取操作部分则包含:系统标定、运动控制与抓取规划等步骤,如图1-2所示。这其中,机器人通过视觉传感器感知环境并实现对目标物体的识别与定位,也就是视觉感知部分,是十分重要的环节,其直接决定了后续机器人的抓取精度。

图1-3 二维图像的部分缺陷
受益于计算机算力的不断提高以及传感器成像水平的高速发展,目前针对结构化环境或者半结构化环境中,基于二维图像的机器人平面单目标物体的抓取技术已经趋于成熟,并取得了丰富的研究成果[1][2][3]。然而,对于现实复杂环境中的三维物体,仅使用二维信息对三维目标进行表征,会不可避免的造成信息损失,如图1-3所示,从而难以实现非结构化环境中机器人对于多目标物体的高精度抓取操作。因此,如何提升机器人的视觉感知能力,并基于此在复杂环境中自主完成对目标物体的识别、定位、抓取等操作是一个很有价值的研究问题。
近年来,随着低成本深度传感器(如Intel RealSense、Xtion以及Microsoft Kinect等)与激光雷达的飞速发展,如图1-4所示,三维点云的获取越来越方便。这里的点云实际上就是在相机坐标系下,对所拍摄的物体或者场景表面进行点采样。物体对应的点云数据在在数学上可以简单的理解为三维坐标的无序集合。三维点云数据相对于平面二维图像具有如下优势:(1)可以更加真实准确的表达物体的几何形状信息与空间位置姿态;(2)受光照强度变化、成像距离以及视点变化的影响较小;(3)不存在二维图像中的投影变换等问题。三维点云数据具有的以上优势使得其有望克服平面二维图像在机器人目标识别与抓取中存在的诸多不足,所以其具有很重要的研究意义以及广泛的应用前景。因此,近年来针对点云的视觉研究以及基于点云的机器人抓取成为了机器人领域新的研究热点。

图1-4 点云获取设备示意图
对应前文的,在基于点云的机器人抓取可以分为点云特征描述(模型与场景表征)、三维目标识别(目标识别与定位)与机器人抓取操作这三个部分[39][40]。进一步的,点云特征描述指的是,将模型与场景对应的无序点集通过特定的算法编码为低维的特征向量,用此来表征对象的局部或者全局信息,其应当具有足够的描述力与稳定性。三维目标识别则主要是指,利用模型与场景的表征结果,在场景中识别出目标物体,并估计出其对应的位置与姿态。对于特征描述与目标识别,尽管现有文献提出了不少算法,并且在特定的环境中取得了不错的效果,然而如何在包含噪声、干扰、遮挡与密度变化的复杂非结构化环境中提取有效而稳定的特征,实现对多目标物体的准确识别定位以及高精度抓取,仍然是极富挑战性的一个问题[4]。
综上所述,基于点云的机器人抓取作为智能化机器人系统的集中体现,近几年来得到了工业界和学术界的广泛关注,并围绕点云特征描述、三维目标识别与机器人抓取操作这三个方面展开了深入研究。具体的,在点云特征描述部分,主要关注描述子的鉴别力、鲁棒性、计算效率与紧凑性等性能;在三维目标识别部分,主要关注目标的识别准确率与定位精度问题;而在机器人抓取操作部分,抓取系统的参数标定与多目标物体的数据分析都是很重要的环节。
1.1国内外研究现状
受益于点云数据自身的优势、计算机算力的不断提高与传感技术的不断发展,基于点云的机器人抓取成为了机器人领域新的研究热点,具有十分诱人的研究价值与应用前景。近年来,学术界与工业界围绕基于点云的机器人抓取,在点云特征描述、三维目标识别与机器人抓取操作这三个方面展开了广泛而深入的研究,取得了显著进展,下面分别从上述三个方面进行文献综述。
1.1.1点云特征描述
点云特征描述在机器人抓取中主要是应用于视觉感知部分的模型与场景表征。一种合格的特征描述算法应该有较高的描述力来表征对应的局部点云表面。此外,此外其还应该对于点云噪声、表面孔洞、部分遮挡、视点改变以及分辨率变化等稳健[4],如图1-5所示。
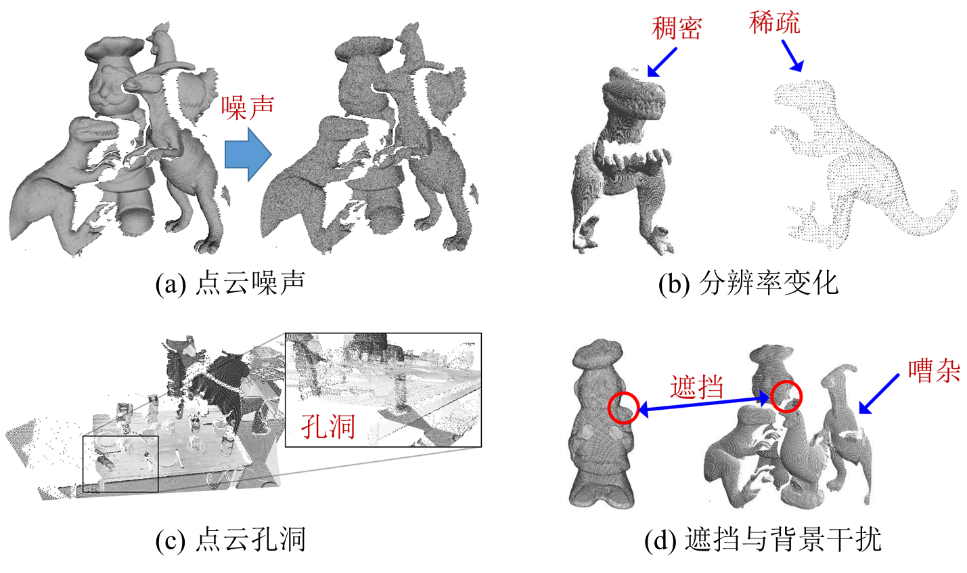
图1-5 点云场景存在的挑战
现有的特征描述算法可以分为全局特征和局部特征两大类[5]。全局特征采用模型的整体几何信息构建得到,典型代表有Osada等[6]提出来的Shape distribution描述子,Wahl等[7]提出来的SPR(Surflet-pair-relation)描述子以及Funkhouser等[8]提出来的Spherical harmonics描述子。全局描述子拥有较高的计算效率和分类能力,但是其对于遮挡比较敏感,很难用于目标识别和精确定位[9]。鉴于此,局部点云的概念被提出,局部特征描述算法得到了深入的研究和广泛的关注。其首先提取关键点建立局部邻域,根据邻域内各点的空间分布信息和几何特征构建描述矩阵。局部描述子对于背景干扰和遮挡鲁棒,相比于全局描述子更适合用于非结构化环境中的目标识别[4][10]。
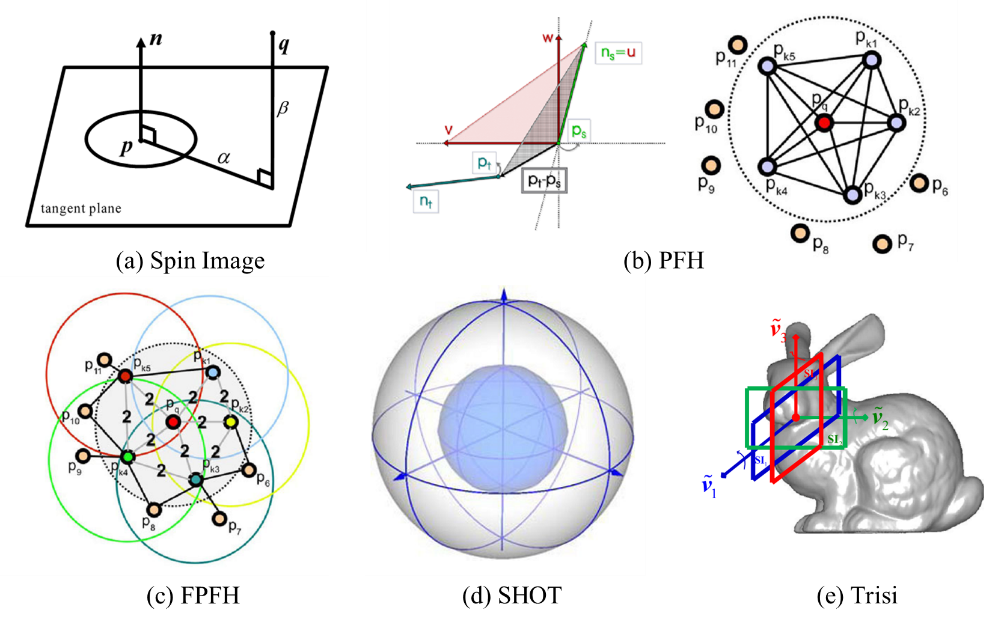
图1-6 部分局部描述算法示意图
局部描述算法又可以根据有无建立局部参考坐标系(Local Reference Frame, LRF)进行分类[11]。不依赖LRF的特征描述子都是使用局部几何信息的统计直方图或者信息量来构成特征矩阵[12]。例如,Johnson等[13]提出了Spin image描述算法,如图1-6(a),它首先以关键点的法线作为参考轴,用两个参数对关键点的每个邻域点进行编码,然后根据这两个参数将局部邻域点进行分箱,进而生成一个二维直方图。Spin image描述子已经成为了三维特征描述子评估体系的实验基准[4][14]。但是,其存在诸如对数据分辨率变化和非均匀采样敏感等缺陷[15]。Rusu等[16]提出了PFH(Point Feature Histogram)描述算法:其对于关键点邻域内的每一个点对,首先建立Darboux框架,然后采用[7]中的方法计算由法向量和距离向量得到的四个测量值,最后将所有点对的测量值进行累加生成一个长度为16的直方图,如图1-6(b)。为了降低计算复杂度,Rusu[17]等仅将关键点与其邻域点之间的测量值进行累加,随后进行加权求和得到FPFH(Fast-PFH),如图1-6(c)。FPFH保留了PFH的绝大部分鉴别信息,但是其对于噪声敏感[5]。目前绝大多不依赖于LRF的描述子仅利用了点云的部分几何特征,而很难编码局部空间分布信息,因而其都鉴别力不强或者鲁棒性较弱[15]。
对于建立了局部参考坐标系的描述子,则利用定义的LRF来同时对空间分布信息和几何特征进行编码以提高其鉴别力和鲁棒性[18]。例如,Tombari等人[19]首先利用加权主成分分析(PCA)的方法为关键点构建了一个局部参考坐标系,进而在该LRF下将关键点对应的球形R-近邻空间进行栅格化处理,然后依据关键点法线与落入每一个子单元的点法线间的夹角将这些点累积到一个数据统计直方图中,最后串联各个直方图便获得SHOT(Signatures of Histograms of Orientation)特征,如图1-6(d)。SHOT计算效率高,但是对于分辨率变化敏感[5]。Guo等[18]通过计算局部表面对应散布矩阵的特征向量来建立LRF,然后利用旋转投影的方法对三维点集进行降维并建立分布矩阵,之后提取分布矩阵的信息量生成最后的RoPS(Rotational Projection Statistics)描述子。RoPS有着优越的综合性能[5],但是其只能用于mesh网格文件,也就是说其无法作用于原始的xyz点云数据[20]。并且,其将数据投影到了二维平面会造成较大的信息损失[21]。之后,Guo[15]在RoPS的LRF算法基础上进行改进,提高了稳定性,然后在坐标系的每一个参考坐标轴上求取局部邻域的Spin Image特征,串联组成Trisi(Triple-Spin Image)局部特征描述子,如图1-6(e)。基于LRF的局部描述算法的鉴别力和鲁棒性很依赖于所建立的局部参考坐标系的可重复性与稳定性,如果坐标系存在轻微的偏差,会对最终的描述向量造成严重的影响[22],如图1-7。然而,目前已有的局部坐标系算法存在可重复性差或者方向歧义的问题[23]。
综上所述,对于不建立局部参考坐标系的特征描述子,由于不能融入空间分布信息,普遍存在鉴别力不高、对于噪声比较敏感等问题;而拥有局部参考坐标系的特征描述子的描述力和鲁棒性则主要依赖于所对应的坐标系建立算法,然而目前已有的坐标系建立方法均存在可重复性差或者方向歧义的问题[22],相应的特征提取算法在鉴别力、鲁棒性与计算效率方面依然有提升的可能[5]。
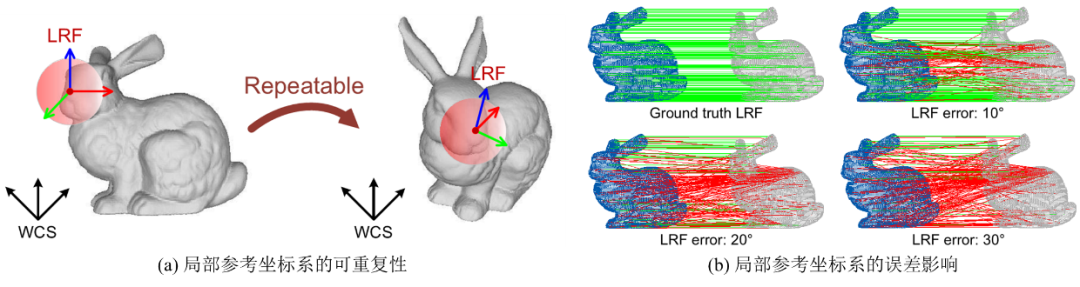
图1-7 LRF的误差影响
1.1.2三维目标识别
在基于点云的机器人抓取领域,完成了模型与场景的表征,下一步则是进行目标识别与定位,也就是在点云场景中对待抓取模型进行三维目标识别以及对应的姿态估计。现有的三维目标识别算法主要包括基于局部特征的算法、基于投票的算法、基于模板匹配的算法以及基于学习的方法[24][25]。
基于局部特征的目标识别算法则主要分成五个部分:关键点检测、特征提取、特征匹配、假设生成、假设检验[26][27]。在这里关键点检测与特征提取组合对应的就是进行模型与场景表征。由于点云的点集数量巨大,如果对每个点都进行特征提取则会造成计算机算力不足的情况,因此会在原点云中提取稀疏而区分度高的点集作为关键点。关键点应当满足可重复性和独特性这两个重要属性[28]。前者涉及的是在各种干扰下(噪声、分辨率变化、遮挡与背景干扰等)可以精确提取相同关键点的能力;而后者则是指提取的关键点应当易于描述、匹配与分类[29]。在点云领域,经典的关键点提取算法包括Harries 3D[30],ISS(Intrinsic Shape Signature)算法[31],NARF(Normal Aligned Radial Feature)算法[32]。特征提取部分则主要是在物体表面提取稳固的局部特征,详见本章1.3.1部分的讨论。
特征匹配的作用则是建立一系列的关键点特征对应关系,如图1-8所示。经典的特征匹配算法有最近邻距离比值(NNDR)、阈值法、最近邻策略(NN)等[33]。论文[33]则表明NNDR与NN的匹配算法优于阈值法的匹配效果,NNDR亦是目前使用最多的匹配策略[34]。为了降低计算复杂度,一般都会使用高效的搜索算法来优化特征匹配,使其快速地找到场景特征库中与当前特征对应的k近邻特征。常用搜索算法包括k-d树[35]、局部敏感树[31]、哈希表[36]与二维索引表[37]等。
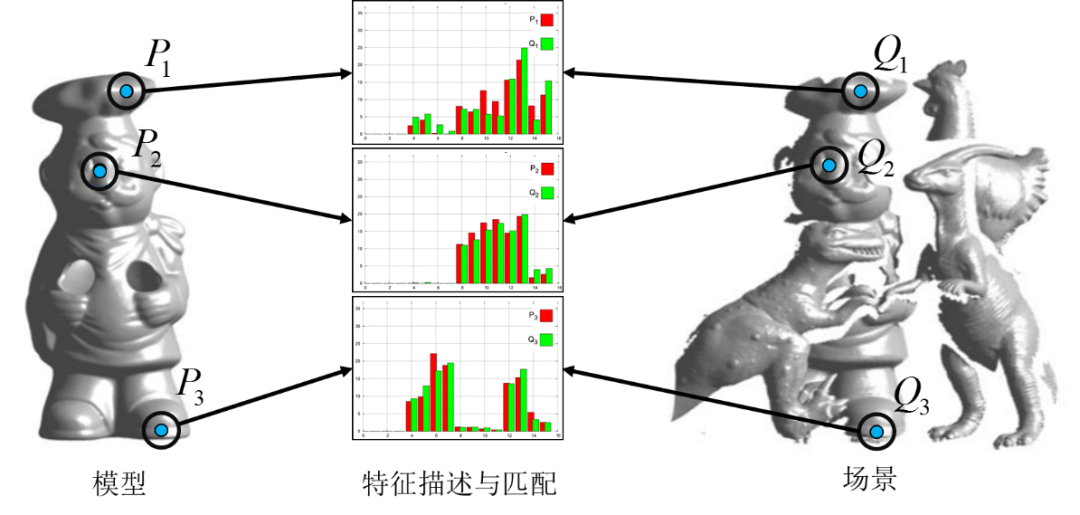
图1-8 局部特征匹配过程示意图
假设生成部分则主要是利用匹配上的特征对集合找出在场景中可能的模型位置,并建立对应的姿态估计(即计算变换假设)[38]。值得注意的是,在匹配上的特征对集合中,既会存在正确的特征对,也会有大量有误差的特征对。因此在计算变换假设的时候,需要使用有效的算法策略尽可能的剔除错误特征对,从而得到较为准确的模型与场景间的变换关系。这一部分的方法主要包括随机一致性采样(RANSAC)、姿态聚类、几何一致性以及扩展霍夫变换等。RANSAC算法首先随机选取k组特征对来计算模型到场景间的变换矩阵(这里k为生成一个变换矩阵所需要的最少特征对数量),并统计满足这个变换矩阵的点对数量。使用这个算法的论文包括[38][39][40]。姿态聚类算法则认为当模型在场景中被正确识别后,大多数模型与场景对齐的假设生成变换矩阵都应当在真实的位姿矩阵(ground truth)附近。使用这个算法的论文包括[31][41][42]。几何一致性技术则认为如果特征对不满足几何约束关系则会使得估计出来的变换矩阵有较大的误差,所以希望使用几何约束来剔除误差较大的匹配点对,进而提高生成的变换矩阵的准确性。使用该算法的论文包括[13][43][44]。扩展霍夫变换则是利用特征对间的平移和旋转等参数构成广义的霍夫空间,然后进行投票统计。这个广义的参数化霍夫空间中的每一个点都对应模型与场景间的一组变换关系,空间中的峰值点被认为是模型到场景变换矩阵估计的最优解。采用这种算法的论文包括[45][46][47]。
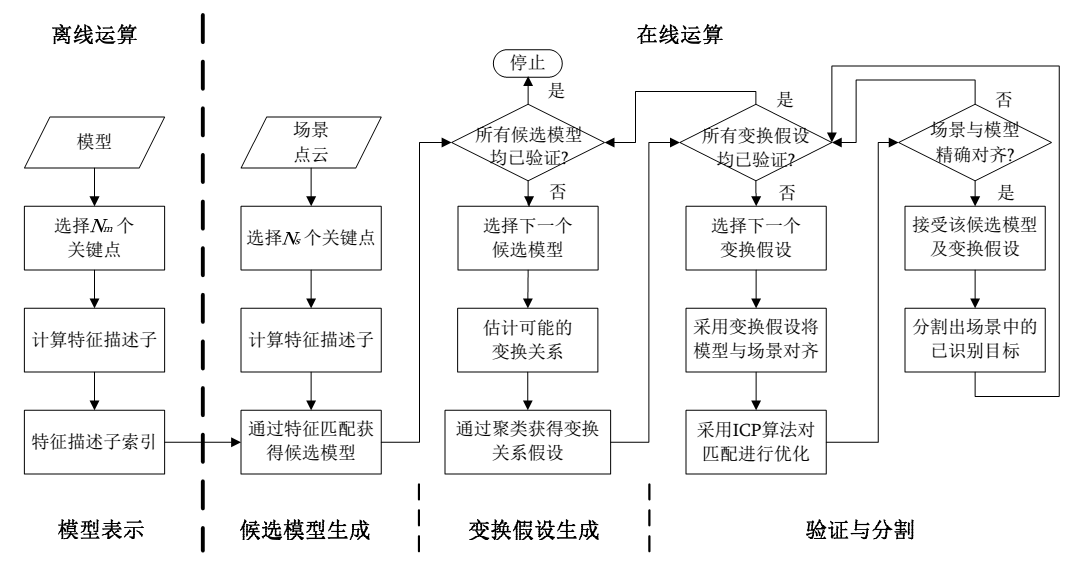
图1-9 基于特征提取的目标识别流程图
假设检验部分则是为了得到假设生成部分所计算出来的潜在变换关系中真正正确的变换矩阵。Hebert与Johnson[13][48]采用模型与场景的对应点数和模型总点数的比值作为相似度参数。当相似度大于设定的阈值时,则认为当前的变换矩阵是正确的。Main[49]则采用特征相似度与点云匹配精度作为综合评价指标。Bariya[43]首先计算出模型与场景的交叠面积,并将模型可见面积和重叠面积的比值作为相似度度量。Papazov[40]则提出了一个包含惩罚项和支持项的接收函数用于评估建设生成的姿态变换质量。Aldoma[44][26]则建立了场景到模型的拟合、模型到场景的拟合、遮挡关系以及不同模型间的关联这几个条件建立了一个代价函数,然后通过求取这个函数的极小值来获得理论上最优的变换姿态。
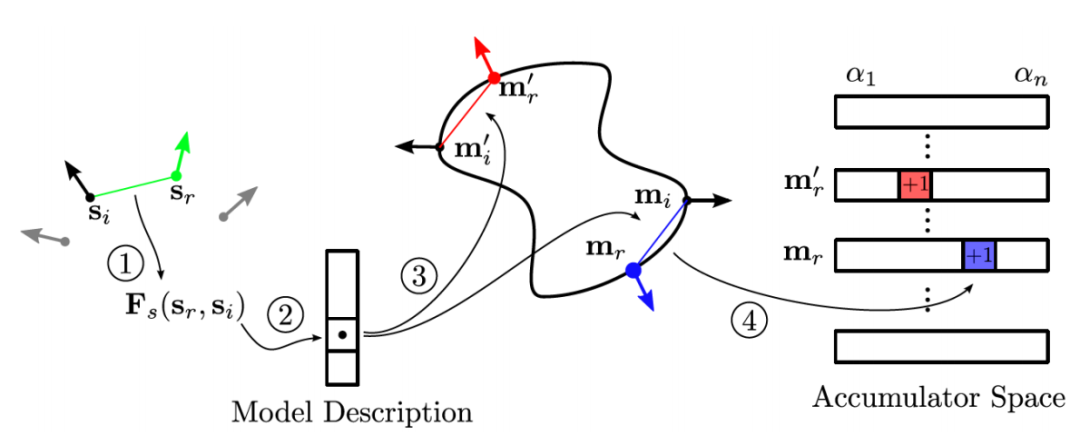
图1-10 PPF投票算法示意图
基于投票的三维目标识别算法则是直接匹配模型与场景间的固有特性,生成有限的候选姿态集后,利用先验条件构造支持函数与罚函数并对每一个姿态进行投票,进而得出最优的变换矩阵。Drost等人[41]提出了用于目标识别的点对特征(Point Pair Features, PPF),这也是三维目标识别领域的经典算法,算法原理如图1-10所示。其利用了点对间最为朴素的特征:距离与法线夹角,构造出有四个参数的特征数组;然后结合哈希表进行穷举匹配,利用高效的投票方案得出最优的姿态估计。Kim等人[50]则在原始PPF特征中加入了可见性特征(空间、表面与不可见表面),增强了PPF的匹配能力。Choi等人[51]在此基础上提出了对点对特征进行分类的策略,如边界上的点对或者是由边缘点组成的点对等。利用这种分类方法可以减少训练和匹配的特征数量,加快了匹配速度以及投票效率。此外,Choi等人[52]还在PPF的点对特征上加入了颜色分量,创建了Color-PPF,实验结果表明其识别率明显提高。随后,Drost等人[53]又提出了利用几何边缘(边界和轮廓)来计算PPF,这种算法显著改进了在高度遮挡场景中的识别率。Birdal等人[54]则提出了先对场景进行分割,在进行PPF匹配的识别策略。更进一步的,Hinterstoisser等人[55]针对PPF提出了一种新的采样方法以及一种新的姿态投票方案,使得这种算法对噪声和背景干扰更加稳健。Tejan等人[56]则从RGB-D图像中训练了一个霍夫森林,在树中的叶子上存储着目标识别6D姿态的投票。
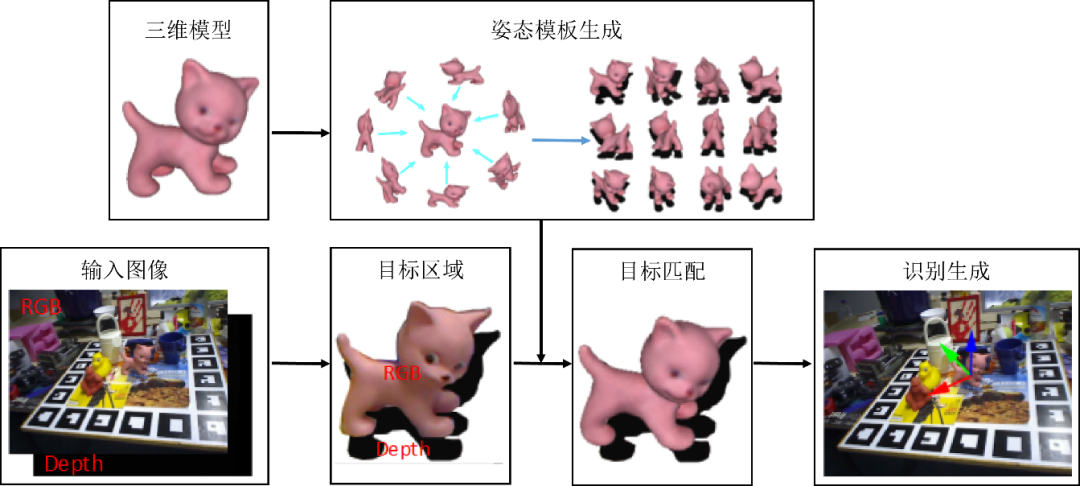
图1-11 基于模板匹配的目标识别流程
基于模板匹配的目标识别算法则主要是针对无纹理物体的检测。其利用已有的三维模型从不同的角度进行投影,生成二维RGB-D图像后再生成模板;然后将所有的模板与场景匹配,进而得出最优的模型位姿,算法原理如图1-11。Hinterstoisser等人[57]提出了经典的Linemod算法,其结合了彩色图像中的梯度信息再结合深度图像中的表面法线信息生成图像模板,在场景图像中利用滑窗搜索的方式进行模板匹配。Hodan等人[58]提出了一种实用的无纹理目标检测方法,也是实用滑动窗口的模式,对于每个窗口进行有效的级联评估。首先通过简单的预处理过滤掉大部分位置;然后对于每一个位置,一组候选模板(即经过训练的对象视图)通过哈希投票进行识别;最后通过匹配不同模式下的特征点来验证候选模板进而生成目标的三维位姿。
基于学习的方法,Brachmann等人[59]提出的基于学习的目标识别算法,对于输入图像的每一个像素,利用其提出的回归森林预测待识别对象的身份和其在对象模型坐标系中的位置,建立所谓的“对象坐标”。采用基于随机一致性采样算法的优化模式对三元对应点对集进行采样,以此创建一个位姿假设池。选择使得预测一致性最大化的假设位姿作为最终的位姿估计结果。这个学习模型在论文[60]中得到了多种扩展。首先,利用auto-context算法对于随机森林进行改进,支持只是用RGB信息的位姿估计;其次,该模型不仅考虑已知对象的位姿,同时还考虑了没有先验模型库的目标识别;更多的,其使用随机森林预测每一个像素坐标在目标坐标系上的完整三维分布,捕捉不确定性信息。自从深度卷积神经网络(DCBB)[61]提出以来,基于深度学习的方法近年来变得十分流行,例如RCNN[62],Mask-RCNN[63],YOLO[64]与SSD[65]等。最近的综述论文[66]对于这些算法进行了详细的阐述和比较。
综上所述,在目前已有的目标识别算法中,基于几何一致性与随机一致性采样的管道方法存在组合爆炸的问题,其对应的计算复杂度为O(n3);而基于点对特征的目标识别方案则会由于法线方向的二义性问题造成识别的准确率下降,并且其对应的计算复杂度为O(n2);基于模板匹配的目标识别算法(Linemod)则存在对于遮挡敏感等问题。虽然各种算法在特定的数据集上都取得了不错的效果,但是在非结构化环境中的目标识别准确率依然有较大的提升空间。
1.1.3机器人抓取操作
基于点云的机器人抓取主要包含视觉感知部分与机器人抓取操作部分。机器人抓取操作部分则又包括系统标定、抓取规划与运动控制。
系统标定包括主要是指对相机与机器人的标定。由于对于视觉感知部分求出的待抓取目标物体的位置与姿态均处于相机坐标系下,为了进行机器人准确抓取,需要将其坐标与姿态变换到机器人坐标系下。这里便需要将相机与机器人进行手眼标定。手眼标定主要求取相机坐标系与机器人基坐标系间的变换关系[67],主要可以分为相机在手上的标定与相机在手外的标定。此外,对于相机,使用时需要进行内参的校准,畸变系数的求取等[68][69];如果是双目立体视觉,则还包含对于双目相机的参数标定[70];如果是结构光或ToF(Time of Flight)成像的点云相机,则还要进行深度校准,以及彩色图与深度图的匹配对齐等操作[71][72][73]。对于机器人,如果是多机器人协同抓取,则组要进行多机器人基坐标系间的标定[74]。
而对于抓取规划部分,其主要作用是可以实现对于场景中目标物体的抓取点的提取[75]。如论文[76]所述,抓取策略应当确保稳定性,任务的兼容性和对于新物体的适应性等;此外,抓取质量可以通过对物体接触点的位置和末端夹爪的配置来进行评价[77]。对于物体的抓取,目前主要有基于经验的方法与基于端到端的方法。
基于经验的方法则是根据特定的任务和抓取对象的几何形状,使用与之相对应的算法来进行抓取。更具体的又可以分为对已知物体的抓取和对相似物体的抓取[78]。如果抓取对象是已知的物体,那么则可以通过学习已有的成功抓取实例,再结合具体环境进行机器人抓取。事实上,如果目标对象已知,则意味着对象的三维模型和抓取点位置在数据库中也是先验已知的。这种情况下,只需要从局部视图估计目标对象的6D位姿,并通过ICP等算法进行姿态细化与精确微调,进一步便可以得到目标物体的抓取位置。这是目前已知的抓取系统中最流行的方法,也是在亚马逊抓取挑战赛[79]中普遍使用的算法。Zeng等人[79]提出了一种利用全卷积神经网络对一个场景的多个视图进行分割和标注,然后将预扫描的三维目标模型与分割结果进行匹配,得到6D目标位姿。他们的方法在2016年APC抓取挑战任务中获得了第三名和第四名。Billings和Johnson-Roberson[80]提出了一种利用卷积神经网络的管道算法,其可以同时完成目标姿态估计和抓取点选择。该管道算法作用于感兴趣区域(ROI),预测出一个中间轮廓来估计目标位姿;然后从先验的数据库中生成抓取点。对于这种方法,当有准确的三维模型是,可以通过估计出6D姿态后进行准确的抓取,由于拥有较高的抓取精度,是目前比较流行的抓取方法。然而,当三维模型不太准确时,如物体不可测量或者易变形等情况,则会导致有较大的抓取偏差。
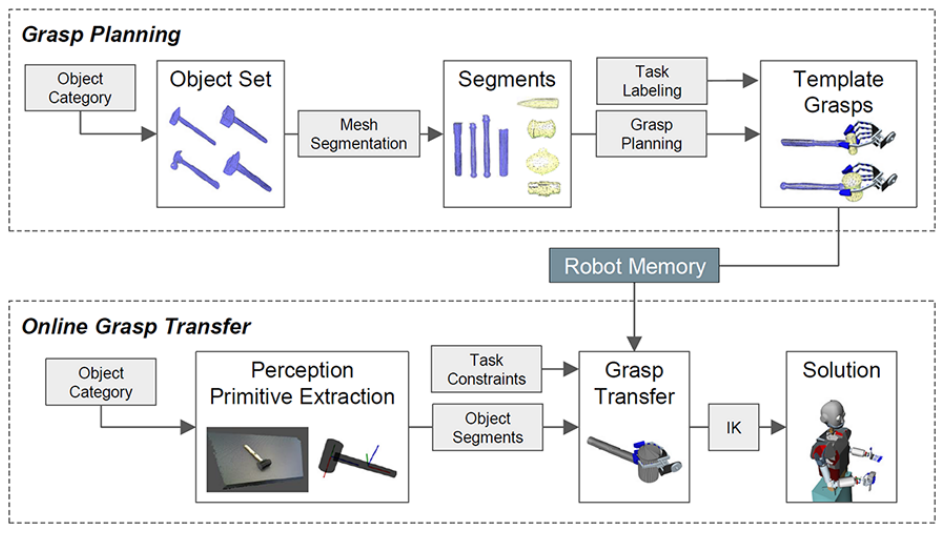
图1-12 局部抓取规划方法
事实上,很多情况下,抓取的目标对象与现有数据库的模型并不完全相同,但是在模型库中相似的同一类的物体,这便涉及到对相近物体的抓取。在目标对象被定位以后,利用基于关键点对应算法便可以将抓取点从模型库中存在的相似三维模型上转移到当前的局部对象中。由于当前的目标对象与数据库中的对象不完全相同,所以这类型的抓取算法是不需要进行六维姿态估计的。Andrew等人[81]提出了一种基于分类法的方法,该方法将对象划分为各个类别,每个类别均存在对应的抓取规范。Vahrenkamp等人[82]提出了一种基于局部的抓取规划方法,用于生成适用于多个已知目标对象的抓取,根据物体的形状和体积信息对物体模型进行分割,并对目标零件标记语义信息和抓取信息。其还提出了一种抓取可转移性的度量方法,用于评估在同一对象类别中的新物体的抓取成功率,如图1-12所示。Tian等人[83]提出了一种将抓取构型从先前的示例对象转移到新目标上的方法,该方法假设新对象和示例对象具有相同的拓扑结构和相似的形状。他们考虑几何形状和语义形状特征对对象进行三维分割,利用主动学习算法为示例对象的每个部分计算一个抓取空间,并为新对象在模型部分和相应的抓取之间建立双射接触映射。这一类型的方法依赖于目标分割的准确性。然而,训练一个能识别出广泛对象的网络并不容易。同时,这些方法要求待抓取的三维物体与标注模型相似,以便找到相应的抓取模型。在经常发生遮挡的杂乱环境中,计算高质量的物体抓取点也是一个挑战。
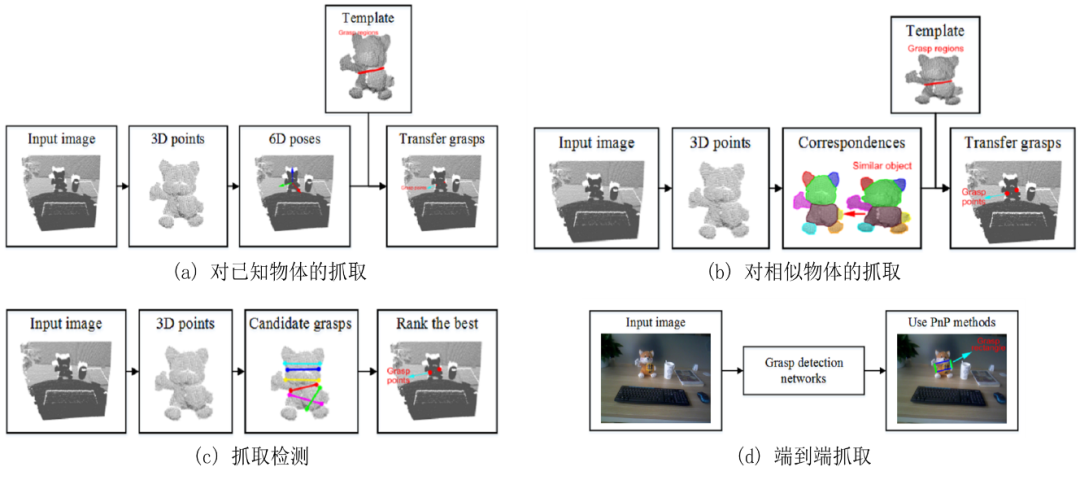
图1-13 不同的抓取方案示意图
端到端的抓取检测则直接跳过了对于抓取目标的定位,直接从输入的图像中提取抓取点位置。在这类方法中,滑动窗口策略是比较常用的方法。Lenz等人[84]提出了一个两步级联系统,该系统具有两个深度网络,第一步的顶部检测结果由第二步重新评估。第一个网络具有更少的特性,运行速度更快,并且可以有效地剔除不可能的候选项。第二个具有更多的特性,速度较慢,但只能在少数几个检测到的信号上运行。尽管他们达到了很高的精度,但是迭代扫描使过程非常缓慢。Ten Pas等人[85]提出了一种无需对目标物体进行精确分割即可在任何可见表面生成抓取假设的方法。他们还提出了一种新的包含表面法线和多个视图的抓取描述符。但是,由于没有执行实例级分段,因此这种算法会将多个对象视为同类物体。由于均匀网络的性能优于双级联系统[84],越来越多的单级方法被提出。Guo等人[86]提出了一种共享卷积神经网络来进行对象发现和抓取检测。Pinto和Gupta[87]提出了一种通过试错预测抓取位置的方法,他们训练了一个基于CNN的分类器来估计给定一个输入图像块的不同抓取方向的抓取可能性。Chu等人[88]提出了一个由抓取区域建议组件和机器人抓取检测组件组成的网络。对于端到端抓取检测方法,计算出的抓取点可能不是全局最优的抓取点,因为在图像中只有部分对象是可见的。
对于机器人抓取中的运动控制这一部分,其主要是设计从机械手目标物体抓取点的路径,这里面的关键问题就是运动表征。虽然从机械手到目标抓取点的轨迹是无限多的,但是由于机械臂的局限性,很多地方都无法达到。因此,轨迹需要规划。
轨迹规划主要有有三种方法,分别是传统的基于DMP的方法、基于模仿学习的方法和基于强化学习的方法,如图1-14所示。传统的方法考虑运动的动态性,生成运动原语。动态运动原语(Dynamic Movement Primitives, DMPs)[89]是最流行的运动表示形式之一,可以作为反馈控制器。DMPs对应的原语是行为单位,或者说是鲁棒的吸引子系统,其实非线性的。在算法中将运动学对应的控制策略按照规则编码为非线性微分方程组,方程组的目标就是吸引子[90]。DMPs已成功地应用于强化学习、模仿学习、以及动作识别等领域。Colome等人[91]的论文则是通过降维(线性)在学习潜在关节耦合过程的同时也进行拥有DMP特征的机器人运动,这实际上是很有价值的研究,因为这样就直接提供了这种运动的最直观的数学描述。Pervez和Lee[92]的论文提出了一个将DMP中的强迫项对应的任务参数化进行建模的数学模型。Li等[93]对应的论文则给出了一种基于高斯混合模型(GMM)和DMP的机器人强化版教学界面模型。所采集的这些动作是通过使用深度摄像头Kinect v2传感器从对应的人体演示者身上采集,采用高斯混合模型(GMM)算法进行DMPs的计算,然后对运动进行建模和泛化。Amor等[94]的论文则描述了一种基于人体动作演示的模仿学习算法,主要是用于机器人学习和运用人体的抓取技能。他们将人类的抓取动作分解为三个部分:从人的教学演示中提取有效的物体抓取策略方法,将抓取策略对应的抓取点迁移到新的待抓取物体上,对抓取动作进行优化。使用他们的方法可以很容易的在机器人中加入新的抓取类型,因为用该算法使用者只需给出一组抓取实例。
在抓取过程中,由于空间有限以及障碍物等原因,会阻碍机器人接近目标物体。这需要机器人与环境进行交互。在这种需要进行避障的抓取任务中,最常见的轨迹规划方法是以抓取对象为中心建模的算法[95],它将目标和环境分离开来。这种方法在结构化或半结构化的环境中工作得很好,因为对象被很好地分隔开了。还有一种以障碍物为中心的方法[96],它利用动作原语与多个对象进行同步联系。通过这种方法,机器人可以在接触和移动目标的同时抓住目标,以清除所需的路径。进一步的,Zeng等人[97]提出了一种更为优越的方法,其采用了无模型的深度强化学习策略来提取抓与推之间的关系。他们的方法中包含了两个卷积神经网络,行为动作与视觉感知。这两个网络是在Q-learning框架下联合训练的,完全是通过尝试和错误的自我监督,成功掌握后会获得奖励。通过仿真和真实场景下的抓取实验,他们的系统可以快速地学习复杂的行为,在存在障碍物的情况获得更高的抓取成功率和效率。

图1-14 典型的轨迹规划方法
从国内外研究现状可知,对于机器人领域中的特征提取、目标识别与机器人抓取等方面均有一些热点问题需要解决。具体的,在特征提取算法方面,鉴别力、鲁棒性与计算效率方面依然有提升的可能;在目标识别与机器人抓取方面,在具有噪声、背景干扰与分辨率变化的非结构化环境中的识别率与抓取的精度不够理想。各个具体问题虽然均由大量的算法被提出,但是不少问题依然没有被很好的处理。每一个问题都是三维视觉领域中亟待解决的热点,期望大家可以给出新的方法进行解决。
责任编辑人:CC
-
机器人
+关注
关注
206文章
26971浏览量
201289
原文标题:基于点云的机器人抓取识别综述
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论