 C++中字符编码的转换
C++中字符编码的转换
作者:FlushHip
在处理东方语言(中日韩)时,经常会遇到各种编码问题,而且被这类问题搞的晕头转向。到网上查资料,看的也是一头雾水,最后往往是误打误撞的把问题解决了,自己仍然稀里糊涂。
这篇文章介绍了如何在最常见的编码方式(Unicode, UTF-8, ANSI)之间进行转换,结合代码实例,清晰明了,方便读者理解,例子也可以直接拿来使用。本文推荐给经常对文字字符串进行处理的程序员阅读,使其掌握字符转换的一些基本方法。
正文
C++的项目,字符编码是一个大坑,不同平台之间的编码往往不一样,如果不同编码格式用一套字符读取格式读取就会出现乱码。因此,一般都是转化成UTF-8这种平台通用,且支持性很好的编码格式。
Unicode、UTF-8的概念不做过多解释,这里说一下ANSI,我第一次看到这个名词,我看成了ASCII。被Mentor狠批一顿。
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00 ~ 0x7F范围的1 个字节来表示 1 个英文字符。超出此范围使用0x80~0xFFFF来编码,即扩展的ASCII编码。
不同的国家和地区制定了不同标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统,ANSI编码代表Big5;在日文Windows操作系统,ANSI 编码代表 Shift_JIS 编码。
以上内容摘自百度百科,可以看出,ANSI和ASCII还是有关系的。ANSI也叫本地码。
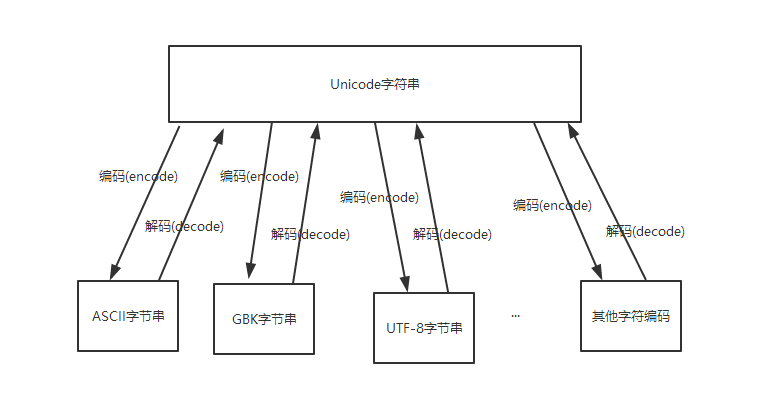
我们要做到能在Unicode、UTF-8、ANSI这三种编码格式中自由转换。如下图所示:
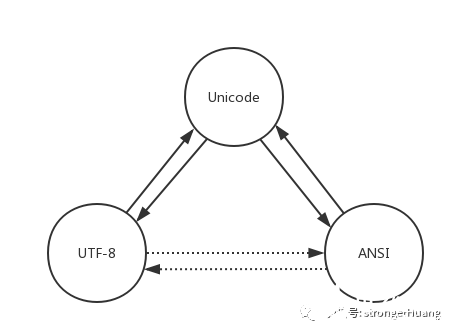
在C++中,要怎么做呢?当然是用标准库的东西啦,C++11对国际化标准做得还是可以的,提供了这些接口,正如图中虚线所示,标准库没有提供UTF-8到ANSI的互相转化接口,但是我们可以自己封转接口,借用这条路(UTF-8 《=》 Unicode 《=》 ANSI)来实现。
因此,接下来就聊聊UTF8 《=》 Unicode和Unicode 《=》 ANSI。
UTF8 《=》 Unicode
先看代码:
std::string UnicodeToUTF8(const std::wstring & wstr){ std::string ret; try { std::wstring_convert《 std::codecvt_utf8《wchar_t》 》 wcv; ret = wcv.to_bytes(wstr); } catch (const std::exception & e) { std::cerr 《《 e.what() 《《 std::endl; } return ret;}std::wstring UTF8ToUnicode(const std::string & str){ std::wstring ret; try { std::wstring_convert《 std::codecvt_utf8《wchar_t》 》 wcv; ret = wcv.from_bytes(str); } catch (const std::exception & e) { std::cerr 《《 e.what() 《《 std::endl; } return ret;}
UTF-8是多字节字符串(multibyte string),而Unicode是宽字符字符串(wchar_t string)。
而C++11提供了wstring_convert这个类,这个类可以在wchar_t string和multibyte string之间来回转换;
而codecvt_utf8可以提供UTF-8的编码规则。这个类在#include 《codecvt》中。有了wstring_convert提供宽字符字符串到多字节字符串的转化,而这个转换规则由codecvt_uft8提供。这样子就可以实现UTF8和Unicode的互相转换。
从UTF8到Unicode调用成员函数wstring_convert::from_bytes;
从Unicode到UTF8调用成员函数wstring_convert::to_bytes;
Unicode 《=》 ANSI
std::string UnicodeToANSI(const std::wstring & wstr){ std::string ret; std::mbstate_t state = {}; const wchar_t *src = wstr.data(); size_t len = std::wcsrtombs(nullptr, &src, 0, &state); if (static_cast《size_t》(-1) != len) { std::unique_ptr《 char [] 》 buff(new char[len + 1]); len = std::wcsrtombs(buff.get(), &src, len, &state); if (static_cast《size_t》(-1) != len) { ret.assign(buff.get(), len); } } return ret;}std::wstring ANSIToUnicode(const std::string & str){ std::wstring ret; std::mbstate_t state = {}; const char *src = str.data(); size_t len = std::mbsrtowcs(nullptr, &src, 0, &state); if (static_cast《size_t》(-1) != len) { std::unique_ptr《 wchar_t [] 》 buff(new wchar_t[len + 1]); len = std::mbsrtowcs(buff.get(), &src, len, &state); if (static_cast《size_t》(-1) != len) { ret.assign(buff.get(), len); } } return ret;}
标准库提供了wcsrtombs和mbsrtowcs这两个函数,当然C的标准库也提供了这两个函数。
讲下wcsrtombs,这个函数把宽字符串转成多字节字符串。编码规则受地域的LC_CTYPE影响。因此这个函数可以用于本地码的转化(和本地的编码息息相关)。
因此,有关于本地码的使用,在代码中要加上下列语句:
setlocale(LC_CTYPE, “”);
目的是让本地码生效,这条代码的作用就是让C++语言的Locale(地域)和本地的地域相同。在Linux下可以运行locale命令看看:
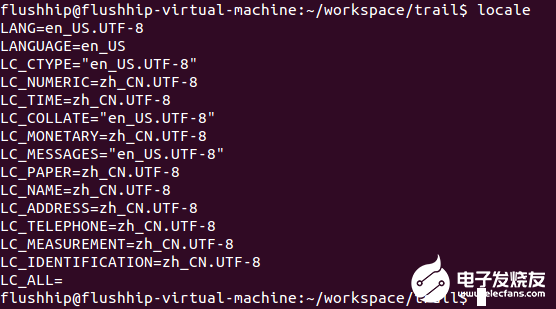
可以看到,LC_CTYPE = en_US.UTF-8,这表示英文,英国,UTF-8编码,也就是说本地码就是这个。
当然,你也可以在setlocale中指定一些编码规则,把wcsrtombs用于别的编码转化,但是,这里不推荐,因为setlocale是全局的,设置了这个就会影响其他地方的编码。
wcsrtombs的四个参数分别代表什么意思呢?
std::size_t wcsrtombs( char* dst, const wchar_t** src, std::size_t len, std::mbstate_t* ps );
dst,转化后的结果存入dst指向的内存;
src,待转化的字符串的指针的指针;
len,dst指向内存的可用字节数;
ps,转换的状态,一般默认初始化就好了;
return type,转化后结果的长度,不包含\0。
注意:如果dst == nullptr,这个时候wcstombs的返回值表示会有这么多字节的结果产生,因此,我们可以拿到这个返回值去新建一个数组来存储new char[len + 1]。所以,一般调用两次wcstombs。
mbsrtowcs同理。
UTF-8 《=》 ANSI
以Unicode为中介装换便是。
std::string UTF8ToANSI(const std::string & str){ return UnicodeToANSI(UTF8ToUnicode(str));}std::string ANSIToUTF8(const std::string & str){ return UnicodeToUTF8(ANSIToUnicode(str));}
总结
C++11的标准库还是挺强大的,虽然这么强大,但是很多特性还不了解,因此还是要多扩宽自己的视野,不然有好东西都不知道用,那就棒槌了。
对了,在Linux下加上setlocale(LC_CTYPE, “”)后程序在命令行中可以正常显示,不加有可能不正常显示,原因是setlocale(LC_CTYPE, “”)也影响了cout,全局的嘛;而在CodeBlocks下不能正常显示,不知道为什么,但是调试的过程中,观察到了正常的结果;Visual Studio中没有做实验,不过应该没问题。
责任编辑:haq
-
计算机
+关注
关注
19文章
6631浏览量
84380 -
编程
+关注
关注
88文章
3439浏览量
92325 -
C++
+关注
关注
21文章
2066浏览量
72880 -
UTF-8
+关注
关注
0文章
13浏览量
7816
发布评论请先 登录
相关推荐
哈夫曼编码怎么算 哈夫曼编码左边是0还是1
c语言如何把字符变成ascii码
oracle怎么把clob字段转换为字符串
字符串如何转换成日期型
mysql数据库默认字符编码是什么
C++演示中的推理速度比Python演示中的推理速度更快是为什么?
如何为Arm编译C和c++代码
C++字符串string





 工商网监
工商网监
评论