 神经网络加速器架构的优劣分析
神经网络加速器架构的优劣分析
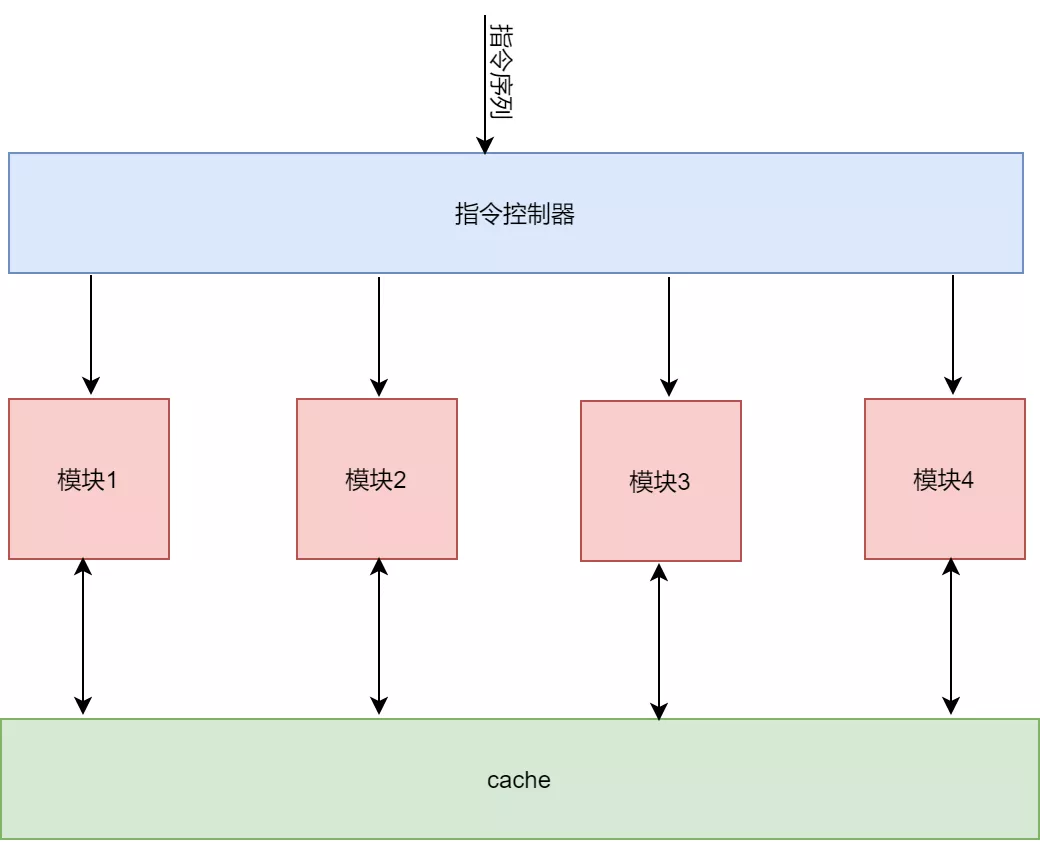
神经网络加速器基本上是一个中介拓扑架构的神经网络加速器,其通过指令解析模块将不同指令分发到不同的数据处理模块。这些数据处理模块共享片上的存储。这种结构的优点有:
1) 结构简单,控制起来容易。对应每个数据处理模块都对应一个复杂指令,在进行神经网络加速的时候,只需要根据神经网络的中的不同数据计算部分,提取出可在硬件上进行布置的部分,根据这部分完成指令编写。同时一个神经网络的计算流图决定了不同类型指令之间的依赖关系。
2) 可扩展性强。数据处理模块可以任意进行扩展,对应着指令集也可以任意增加。每个模块和指令的接口以及cache的接口形式是一定的,它们之间可以通过cache来进行数据交互。指令集和模块的增加和减少都不会影响到整体架构。我们只要开发出新的模块IP以及指令就够了。
我个人认为,目前的架构还存在如下缺陷:
1) 架构不够灵活。相对于千变万化的神经网络结构,其只能加速有限的的计算模块。而且如果不同神经网络之间进行切换的时候,如果这两种神经网络差别很大,则可能造成不太好找到一个比较匹配的XRNN结构。比如一个神经网络要用到模块A,但是另外一个神经网络要用到模块B,那么我们的架构就需要将模块A和B都加上,这样才能适合两种网络。当然也可以选择不加,但是终归是有模块不能得到充分利用。
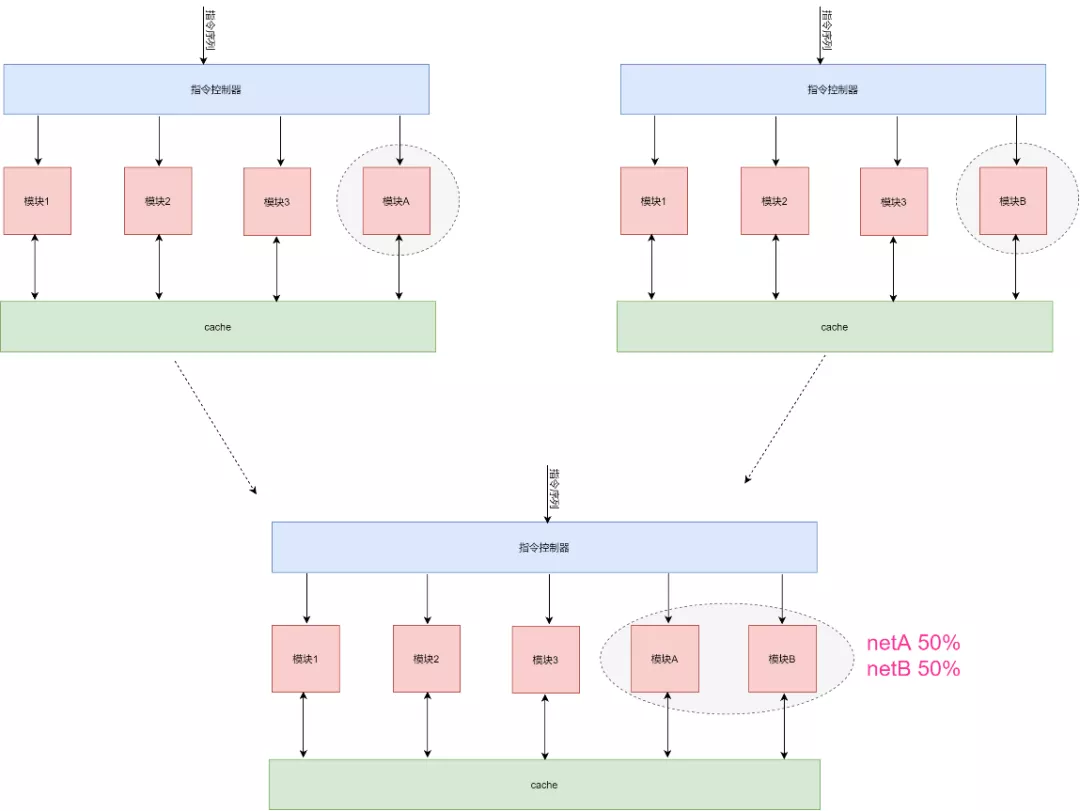
2) 不同数据处理模块之间通过cache进行数据交互,以及指令分发造成了延时。这对于一个大的神经网络来说,这些开销占比很小,但是当一个神经网络很小,计算复杂的时候,不同模块之间的数据交互就会降低整体效能。

3) 介于AI芯片和GPU之间的尴尬处境。使用FPGA来进行神经网络加速器,和GPU比不过算力,同时又不能像AI芯片那样具有高速和充足资源的特点。所以针对大计算的网络,面对GPU我们的性能很难PK过。
4) FPGA的优势没有显现出来。可以和GPU等竞争的优势在于FPGA的动态可重配置以及流水线处理,这些是GPU等芯片不具备的。流水线可以容纳更多的计算核,而且能够减少计算核之间数据延时,而可重配置的特点可以更好的适配千变万化的神经网络结构。这两个优点在神经网络加速器中也得到了一定的体现,比如矩阵乘法核的大小,cache大小都是可配置的。而且不同的计算模块之间还可以做一定的直连,也能够降低读写cache带来的延时。但是这些特点还并没有得到很好的利用。
图架构设想:
对于神经网络加速器,我们总是渴望在FPGA上构建一个统一的IP核,能够尽力去适应不同的神经网络,能够尽力去加速每个神经网络。于是乎,我们增加了一个个模块IP,不断扩充指令集。但是这些都受到了两个条件的制约:一个是FPGA资源的有限性,另外一个就是神经网络的千变万化。如果我们换一种思路,不去追求一种统一的神经网络加速IP,而是基于FPGA可重配置特点构建一种平台,在这个平台下,可以由用户根据需要加速的不同神经网络来自行搭建一套加速器。而我们要做的就是,建立一个IP库,库里包含各种计算IP,比如矩阵乘法,向量加法,concat,embedding等等。整个平台来根据网络模型选择不同IP来构建一个神经网络加速器。
基本设想的结构是这样的:

硬核IP不仅仅包括在FPGA上开发出的各种计算核,还包含有CPU,因为FPGA资源限制以及计算的复杂性,并不是所有的神经网络计算都可以在FPGA上实现。
软件根据网络模型,分析哪些计算可以用FPGA实现,评估其实现性能,选择最适合在FPGA上进行加速的计算。同时需要评估FPGA资源情况,配置每个核的大小,使用资源等。然后根据神经网络计算流图,确定不同IP核的连接关系,构建图。
图结构大致设想如下:
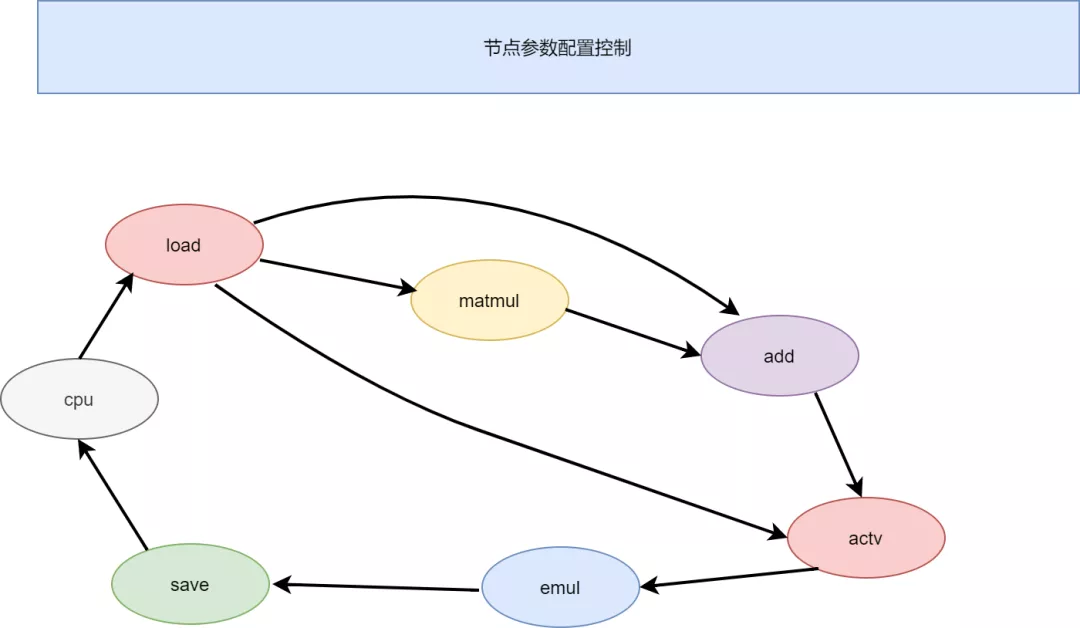
不同节点代表一个计算模块,这些模块之间直接通过数据流交互,不经过共享内存的方式,计算可以实现流水。节点控制器对每个节点实现参数配置,和数据流控制,数据流控制也很简单,只需要控制数据闸门的开关,以及数据量流通的多少就行了。
-
FPGA
+关注
关注
1599文章
21273浏览量
592820 -
加速器
+关注
关注
2文章
740浏览量
36569 -
神经网络
+关注
关注
42文章
4562浏览量
98643
发布评论请先 登录
相关推荐
PowerVR Series2NX神经网络加速器设计
张量计算在神经网络加速器中的实现形式





 工商网监
工商网监
评论