 典型AI运算的功耗最多可减少75%?
典型AI运算的功耗最多可减少75%?
像Nvidia这样的芯片巨头可以负担得起7nm技术,但初创公司和其他规模较小的公司却因为复杂的设计规则和高昂的流片成本而挣扎不已——所有这些都是为了在晶体管速度和成本方面取得适度的改善。格芯的新型12LP+技术提供了一条替代途径,通过减小电压而不是晶体管尺寸来降低功耗。格芯还开发了专门针对AI加速而优化的新型SRAM和乘法累加(MAC)电路。其结果是,典型AI运算的功耗最多可减少75%。Groq和Tenstorrent等客户已经利用初代12LP技术获得了业界领先的结果,首批采用12LP+工艺制造的产品将于今年晚些时候流片。
为了实现这些结果,格芯(GF)采取了整体方法来加速AI运算,特别是推理卷积神经网络(CNN)。此工作负载非常依赖MAC运算,但格芯发现,大部分功耗实际上用在从本地SRAM读取数据并将其传输到MAC单元上。新的SRAM设计大大降低了CNN和其他经常访问长数据向量的应用的功耗。新的MAC针对大多数AI加速器的较小数据类型和较低时钟速度而设计,这也有助于节省功耗。SRAM单元中的成对晶体管经过重新设计以提高匹配度,使电压得以降低,从而减小所需的电压裕量。
格芯在放弃7nm及更小线宽技术的计划之后转而选择了这条道路,专注于FD-SOI、SiGe和其他差异化技术(参见MPR 8/13/18,“格芯新战略”)。12LP+和AI方面的努力就是其差异化战略的又一例证。这种方法的优势在某些方面要比7nm更大,但成本更低。以前,这家晶圆厂专注于制造AMD公司的高性能CPU,但随着AMD将其业务转移至台积电,修订后的战略已帮助格芯吸引到新客户。
为AI而设计
在典型的高性能CPU中,本地SRAM每周期提供一个完整的缓存行,然后CPU通过多路复用器(mux)选择所需的字。例如,使用256位缓存行的64位CPU需要一个4:1多路复用器,如图1(a)所示。在这种情况下,即使CPU每个周期仅使用64位,SRAM阵列中的所有256位缓存行也会在每次访问时放电。这种方法最大程度地减小了SRAM延迟,从而有可能提高最大时钟速度或减少流水线级数——这二者都是影响CPU性能的关键因素。
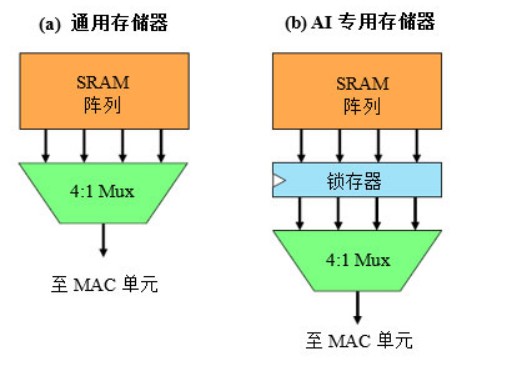
图1. 格芯AI专用存储器。通用阵列最大程度地减小了随机存取的延迟。添加锁存器会增加延迟,但会降低顺序存取的功耗。
AI加速器通常以比PC处理器低的时钟速度运行,其设计师更关心吞吐量而不是延迟。此外,CPU通常具有随机存取模式,但CNN产生的则是顺序存储器存取,其处理的向量常常具有数以百计或数以千计的元素。为了更好地支持这些设计,格芯在SRAM阵列和多路复用器之间添加了一个锁存器,如图1(b)所示。这样做会给读取路径增加一个周期,CPU设计师绝不会接受这种做法,但它为AI加速器带来了可观的好处。
首先,锁存器将多路复用器与阵列解耦,从而减小位缓存行上的电容,进而降低每次SRAM存取的功耗。但更大的好处是,在读操作之后,完整的256位输出仍位于锁存器中。如果随后的读操作访问下一个递增存储器地址,那么可以从锁存器中读取该值,而根本无需驱动阵列。对于从很长的一系列顺序地址读取数据的程序,此设计只需在25%的时间内为SRAM阵列供电。考虑到包括多路复用器和锁存器的整个电路,格芯估计:相对于标准编译的SRAM,CNN工作负载的功耗可降低53%。由于时序约束变得宽松,新的SRAM也缩小了25%。
尽管MAC单元的功耗仅占总功耗的一小部分,但其面积常常占总芯片面积的最大部分。新设计具有一个16x16位乘法器,与高端CPU所需的64位设计不同。基数为4的Booth乘法器馈入一个48位加法器,以进行高精度累加。对于CNN推理中常见的8位整数(INT8)数据,可以将MAC单元拆分为每个周期产生两个8x8乘法,并进行24位累加。格芯的目标工作频率为1.0GHz,物理设计因而得以简化,功耗和芯片面积得以减小。新的MAC单元比之前的12LP单元小12%;在相同电压下都以1.0GHz运行时,所需的功耗减少25%。
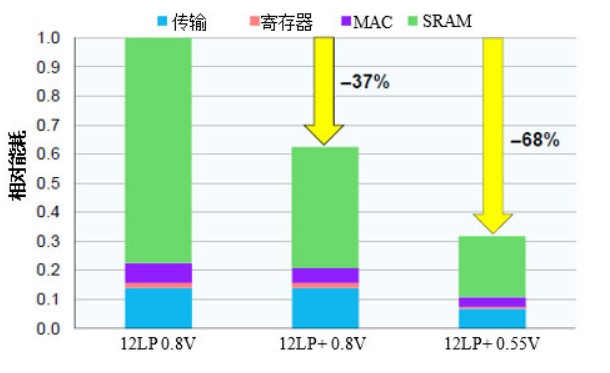
图2. 12LP+的能耗降幅。在典型的脉动MAC阵列中,新的SRAM和MAC设计使总功耗比之前的12LP技术降低了三分之一,而降低工作电压又使总功耗降低了三分之一。
为减小电压而付出的大量工作
为了进一步降低功耗,格芯在工作电压上狠下功夫。无论什么节点,一个重要挑战是管理晶体管的制造偏差。栅极和沟道在形状、厚度或掺杂上的微小差异可能会改变晶体管的功函数(衡量电子移动通过材料所需能量的参数)。功函数会修改阈值电压,从而决定晶体管何时切换状态。对于给定工艺,晶圆厂会将工作电压设置得足够高,以确保芯片上的所有晶体管都能可靠地开关,即它必须超过最坏情况下的阈值电压。
为了应对这一挑战,12LP+增加了双功函数晶体管。此技术原本是为7nm工艺而开发的,格芯将其移植到了12nm节点中。新设计以不同方式掺杂NMOS和PMOS晶体管,以便更好地平衡其功函数。这种方法会使成本略有增加,但大大降低了所需的裕量:对于1.0GHz的目标频率,SRAM的工作电压从12LP的0.7V降至12LP+的0.55V。12LP逻辑的标称电压为0.8V,欠驱电压为0.7V,但在12LP+中,它也可以采用0.55V工作。由于功耗与电压的平方成比例,因此这些变化可以使功耗减半。
SRAM是主要的耗电器件,所以格芯专注于开发低压存储器单元。测试芯片显示,即使在0.45V电压下,新型LVSRAM的良率仍超过95%,这意味着设计在0.55V电压下具有充足的裕量。为使逻辑功能受益,格芯委托Arm的物理知识产权(physical-IP)小组为12LP+工艺创建了一个完整的低压标准单元库。该库定于9月上市,客户可利用它来构建完整的AI加速器以让SRAM和MAC单元采用0.55V电压工作。
新技术的总节电效果非常显著。格芯对MAC单元的脉动阵列(这是CNN加速的常见配置)的功耗进行了仿真。仿真读取权重和激活(图2中显示为SRAM功耗),让数据移动通过脉动阵列(传输),然后执行计算(MAC)。相对于基本设计,新的MAC单元和锁存SRAM使总能耗减少了三分之一以上,而传输能耗保持不变。以0.55V电压工作会产生一个全面的大压降,使该设计的总节电量达到68%。
与往常一样,格芯通过广泛的物理元件库(包括数字、模拟和无源器件)来支持12LP+工艺。格芯提供EDA工具(如Cadence和Synopsys插件)、Spice模型、设计规则检查器、时序模型以及布局布线功能。为了提高良率,格芯提供了完整的可制造性设计(DFM)流程。格芯已针对12LP+重新优化了12LP物理IP,包括存储器和I/O接口。除了Arm的低压标准单元库外,Rambus和Synopsys等第三方IP供应商也支持12LP+。
助力AI领先公司
这项新技术建立在格芯成功的12LP工艺基础上,为行业领先的AI产品提供助力。例如,硅谷初创公司Groq开发了一种新的架构方法来加速集数百个功能单元于单个核心中的神经网络。庞大的设计包括220MB的SRAM和200,000以上的MAC单元(参见MPR 1/6/20,“Groq撼动神经网络”)。Groq采用12LP使如此大型设计的功耗保持在300W的预算之内。该芯片以1.0GHz的初始速度,对INT8数据实现了每秒820万亿次运算(TOPS)的峰值吞吐量,超过了所有其他已发布的加速器。
加拿大初创公司Tenstorrent也加快了推理速度,但它选择了一个不同的设计目标:总线供电的PCIe卡的功耗限值为75W。其第一款芯片具有120个独立的核心,每个核心包含1MB的SRAM和大约500个MAC单元。这种方法仍然需要大量的SRAM和MAC单元。该芯片以1.3GHz的初始速度可提供368 TOPS(参见MPR 4/13/20,“Tenstorrent提升AI性能”)。12LP技术帮助Tenstorrent实现了每瓦4.9 TOPS的性能,这一效率在数据中心产品中遥遥领先,如图3所示。
在这个市场上占有最大份额的Nvidia最近发布了基于新型Ampere架构的A100加速器。Ampere引入了许多创新特性,峰值性能提高到624 TOPS,超过了除Groq之外的所有已发布芯片。然而,尽管采用7nm工艺,但A100仍需要400W TDP,比之前的12nm产品还高33%。为了适应功耗预算的增加,Nvidia不得不降低时钟速度(相对于12nm产品),并禁用芯片上15%的核心。这是一种不寻常的策略,可能意味着芯片功耗大大高于仿真功耗(参见MPR 6/8/20,“Nvidia A100称霸AI性能”)。因此,虽然A100的晶体管较小,但其每瓦性能严重落后于Groq和Tenstorrent芯片。
与格芯的12nm工艺相比,台积电7nm工艺的一个优点是晶体管密度增加一倍,使得Nvidia可将超过500亿个晶体管封装到A100中。为了帮助客户在这方面竞争,格芯支持各种小芯片方法。格芯在多芯片封装方面拥有丰富的经验,包括具有高带宽存储器(HBM)的2.5D硅中介层设计。针对3D芯片堆叠,格芯已开发出混合晶圆键合(HWB)技术,其使用间距为5.76微米的硅通孔(TSV),并有密度提升的路线图。对于低密度互连,客户可以在便宜的有机衬底上构建小芯片配置,类似于AMD的Rome处理器。这些小芯片方法中的任何一种都能在不迁移到7nm工艺的情况下实现很高的晶体管数量。
价格和供货情况
格芯的12LP+技术已可用于设计启动。我们预计量产将从2021年下半年开始。
优于7nm
台积电声称,相对于其10nm节点,其7nm技术可使时钟速度提高多达20%,功耗降低多达40%(参见MPR 5/20/19,“EUV工艺实现量产”)。但是,这些最佳情况下的数字都假定晶体管的负载很轻。复杂的处理器设计通常受限于金属电容而不是晶体管速度,因此只能获得上述好处的一半或更少。如前所述,Nvidia的7nm A100比其12nm的前代产品要慢,而高通公司首款7nm处理器Snapdragon 855的最大CPU速度仅比Snapdragon 845提高了2%。台积电预期5nm的收益将小于7nm,因为更多地使用EUV会增加每片晶圆和流片的成本。
格芯的12LP+提供了一条替代路径,与台积电的7nm相比,功耗大幅降低,成本则没有增加。功耗降低主要归功于新的双功函数晶体管,它支持0.55V电压选项。台积电的7nm技术提供超低VT (ULVT)晶体管,其工作电压最低为0.6V。台积电长期以来服务于智能手机客户,专注于低压操作,而格芯更侧重于PC,直到最近才发生改变,因此其在这方面的进步在很大程度上是弥补差距。
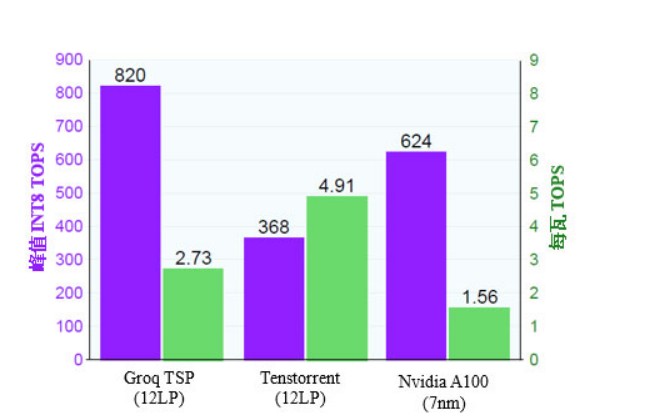
图3. 高端AI加速器比较。与Nvidia的新产品A100相比,Groq TSP的性能更强劲(以每秒万亿次运算或TOPS衡量),而功耗却更低。Tenstorrent的性能目标较低,但功效(每瓦TOPS)是A100的三倍。
12LP+的其余优势来自于该技术专为AI设计的SRAM和MAC单元。这种方法反映了晶圆厂的差异化:台积电必须服务于广泛的客户,而格芯可以专注于特定的新兴工作负载。AI市场尤其成果丰硕,因为有太多的公司(特别是初创公司)在开发CNN加速器。大型客户通常会自行设计缓存和MAC单元,但格芯的设计对于希望将开发成本降至最低而专注于独特架构的初创公司很有用。
更长期问题是,在没有7nm及更小线宽技术的路线图的情况下,格芯能否保持竞争力。台积电的5nm技术正在量产中,客户已经启动未来节点的设计。这些先进的工艺使设计师能够将更多存储器和MAC单元放入芯片中。市场份额最大的大型公司将继续沿这条路走下去。面向AI市场的小型公司则会发现12LP+更实惠,而且可以使用小芯片来经济高效地提高晶体管数量。Groq和Tenstorrent通过格芯的12LP技术实现了领先的AI性能,12LP+中的AI增强功能将使新技术更加卓越。
责任编辑:tzh
-
芯片
+关注
关注
446文章
47701浏览量
408841 -
晶体管
+关注
关注
76文章
9028浏览量
135060 -
AI
+关注
关注
87文章
26360浏览量
263947
发布评论请先 登录
相关推荐
NanoEdge AI的技术原理、应用场景及优势







 工商网监
工商网监
评论