 情感语音合成技术难点突破与未来展望
情感语音合成技术难点突破与未来展望
语音技术的进步,让机器合成的声音不再顿挫、冰冷,在自然度和可懂度等方面取得了不错的成绩,但当前合成效果在合成音的表现力上,特别是语气和情感方面,还存在不足。声音如果缺少情感,何谈表现力 ,又如何能提高用户交互的意愿?本文由标贝科技联合创始人兼CTO李秀林LiveVideoStack线上分享内容整理而成。
大家好,我是标贝科技的李秀林,非常高兴能与大家分享情感语音合成的事情。
在语音交互中语音识别、语音合成、语音理解是必不可少的环节。语音识别,也就是识别用户说的话。识别完成后,系统需要理解用户语言背后的含义,我们称之为语义理解。理解到用户的诉求后,需要寻找答案并给出响应。通常情况下,我们会首先得到一份文本形式的答案,然后再将文本通过语音合成,模仿人说话的形式反馈给用户,这也就形成一轮完整的语音交互。
语音交互过程涉及语音合成,即把文字变成声音,声音是文字内容的一个信息载体。语音交互是日常生活中最常见、最被人熟悉并乐于接受的展现形式,例如:人与人说话、看电视、听收音机、与音响交互等等。体验效果的好坏,会对用户的感知造成很大影响。如果语音合成质量较好,说话效果更接近真人,且情感表达丰富,那么用户的交互意愿自然也会更强,用户会觉得这不是一个冷冰冰的机器,会有愿意与这类智能体进一步交互。 这段小视频是疫情初期我们的合作伙伴利用语音合成技术生成的。从视频中大家可以明显感受到:我们可以从声音当中获取充分的信息,也就是信息的传达作用是完全没有问题的。但也同样存在一个问题,即声音相对来说比较平淡,声音更多的是作为一个信息载体,而不是作为一个表达的载体。
接下来会和大家一同探讨语音合成和情感语音合成的技术难点与实现,以及将来语音合成的发展和应用场景。 01 语音合成的发展
语音合成的历史可以说是相当悠久。最初,实际上是通过类似于钢琴一样的设备来弹奏,能够发出几个声音,大家就已经觉得非常厉害。随着计算机技术的发展,从80年代到90年代再到现阶段,技术的迭代更新也越来越快。
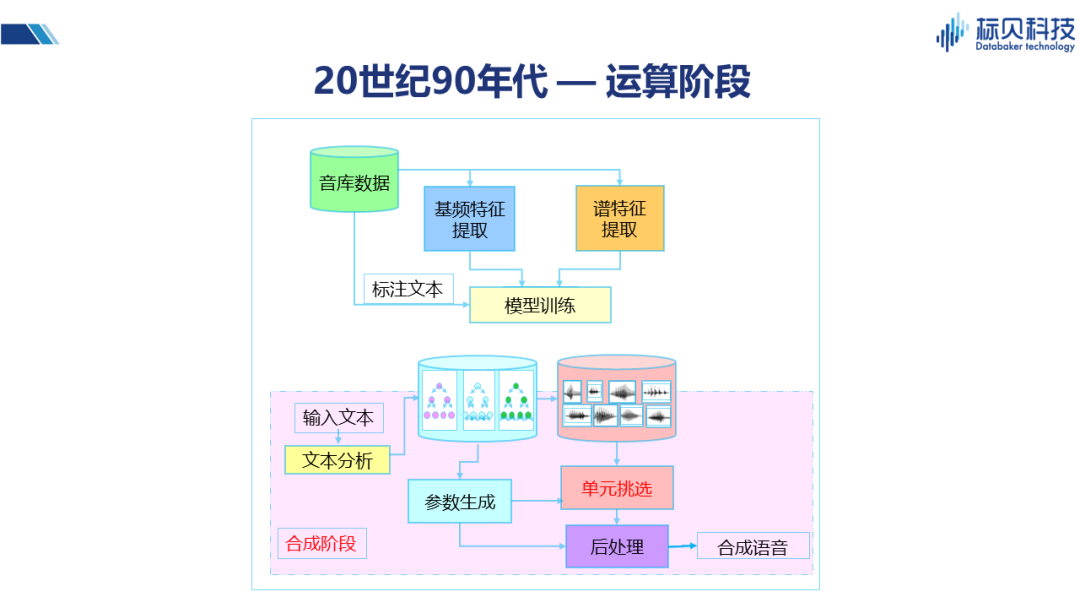
90年代,计算机已经可以支持几百兆甚至上G的内存,硬盘也足以支持几十G的内存,能够实现存储大量的数据并进行较为复杂的处理。上图展示的系统框架就是在这一阶段产生的,并且直到前几年还有很多商务系统仍旧使用这套框架。 在框架中,训练阶段我们会针对音库的数据以及对应的标注文本进行建模(包括基频的提取、谱特征提取,以及时长提取等),训练成时长模型、基频模型、谱模型等。合成阶段则存在拼接合成、参数合成两种主流的方案。 拼接合成:用户输入的文本将通过文本分析,并结合训练好的模型生成对应参数。该参数可以指导拼接系统进行单元挑选。所谓单元挑选,即从之前录制好的音库片段中挑选最合适的部分,将其拼接起来,使得整个声音更加流畅,接近于真人。单元挑选的优点是音质还原度非常好,而缺点是其音级单元之间有时会产生一些跳跃和不连贯,通常表现为在听感上会感觉有些地方不流畅、不舒服。 参数合成:即不使用原始的声音片段,通过声码器对声学参数进行转换,生成声音。这种方案由于其统计特性、以及声码器性能的影响,在音质方面会相对弱一些。
近些年,随着神经网络技术的发展,统计模型方面受到很大影响。之前许多基于高斯混合模型的统计,我们可以直接通过神经网络模型来实现。当前阶段我们将它命名为 — 自学习阶段。 神经网络具有很强的自我学习能力,有非常多的权重,可以通过数据,学习到许多连专家都难以总结出来的特点。因此,当前阶段大家会更多的选择使用神经网络。 2016年,WaveNet的出现彻底改变了声音生成的方式,它将逐帧生成,即以帧为单位的声音生成变成了逐点生成波形。所带来的好处是声音还原度变得非常高,在一定程度上可以说是接近于原始声音。尽管其仍存在计算量复杂的缺点,但此缺点在近两年也已通过一系列的改造,例如并行的WaveNet等等,逐渐变得可以接受,同时优势的体现也越来越充分。
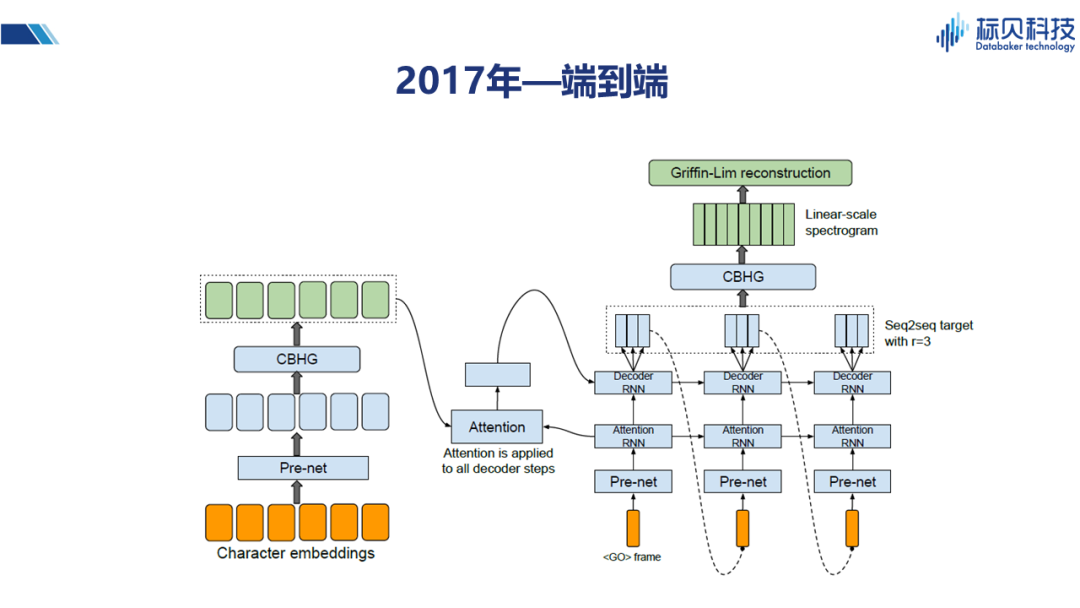
2017年,Tacotron以及后续Tacotron2等一系列的变体,为我们提供了一种端到端的语音合成方式。端到端虽然更多的是一个学术概念,但就整体系统来说是非常漂亮的。它利用核心的Attention机制,将输入和输出之间的关联度,通过模型很好的表述出来。在此之前我们通常是先做一个时长模型,然后再做其它谱模型、基频的模型,而通过端到端的模型,我们就可以跳过时长模型,直接针对整句话进行建模。Tacotron的出现,对于合成语音的韵律,节奏方面都有很大的提升(更接近真人)。
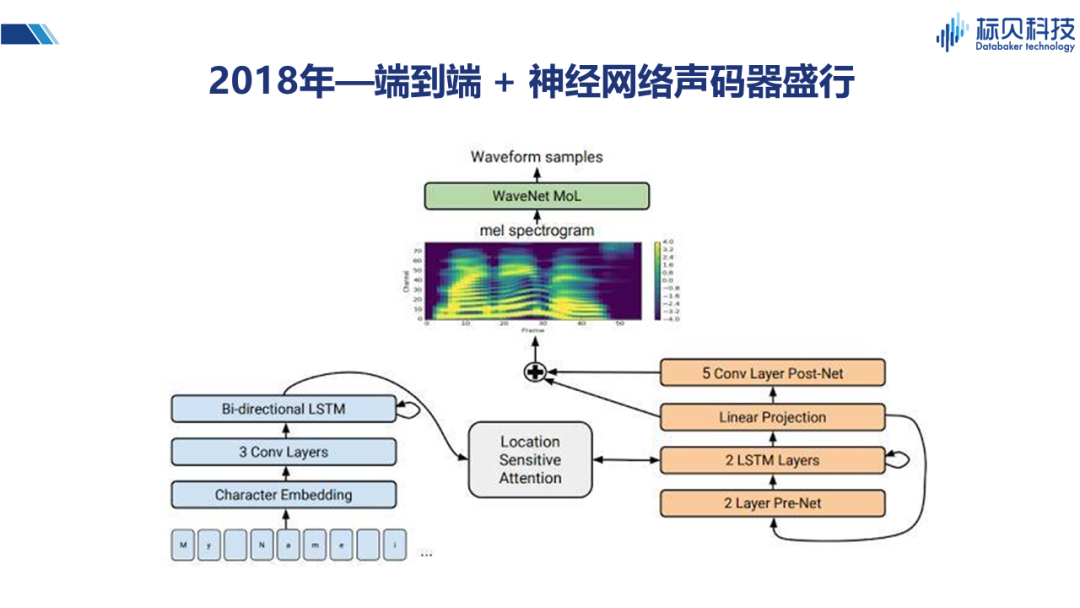
2018年,大家将两种网络结合在一起,即将端到端与神经网络的声码器结合形成一个更逼真的语音合成系统。并且对Attention的结构也进行了一些改造,使得系统整体性能更优。所以在2018年以后,我们所见到的语音合成系统大多是基于Tacotron或Tacotron2实现。 02 情感合成 2.1 情感合成是什么?
以上简单介绍了语音合成近些年的一些变化,那么为什么在经历了这一系列变化后,大家觉得还是不够?一般来说合成的数据我们都会考虑追求平稳,因此在情感和表达方面也就不会太丰富。但近些年大家对情感合成以及个性化合成的兴趣与需求越来越高。 关于情感合成,我们可以想象一下,假如我们在和机器交流时能够像和一个真正的人交谈一样,它可以用平淡的声音、高兴的声音、悲伤的声音,甚至不同的情感有不同的强度,比如说微微有点不高兴、非常不高兴、非常愤怒。那么可想而知这种场景会给我们的生活带来多大改变。
情感合成作为一项技术,当然也离不开神经网络的三要素:算法、算力和数据。而对于语音合成领域来说,算力实际上是不太重要的,我们可以通过一些GPU 的卡来解决算力的问题,因此需要我们重点关注的是算法和数据的问题。 情感合成的算法在最初使用HTS技术时,已经有很多学者进行过一些探索。但是由于模型的描述能力,以及模型本身自学习能力较弱,实用性会差一些。 2.2 情感标签的使用
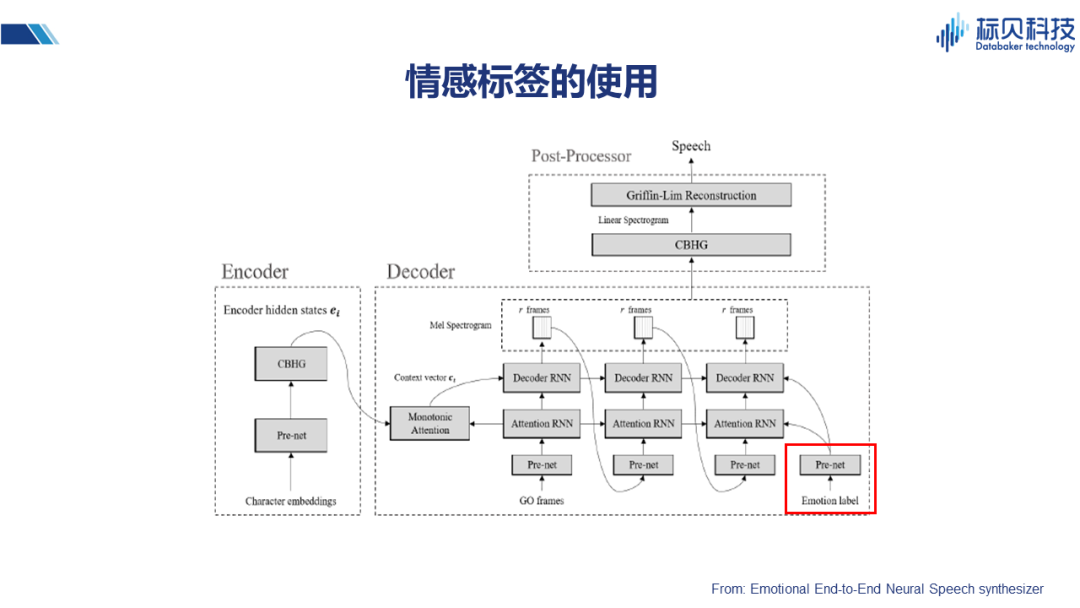
大家可以发现,在有了神经网络之后,目前情感合成的方案基本上都是在一个很好的框架之上来进行一些不同的改造,下面简单介绍几种不同的解决方案。 在这篇端到端的情感合成的文章里,提到用情感做标签(在原有网络基础上增加一个情感标签),通过一个prenet 把这些信息引入到Attention的decoder中。这样情感的信息自然会通过网络得到一定的学习,在合成的时候,如果能赋予合适的情感标签,也就能合成出有一定情感表达力的声音。 2.3情感合成的实现 2.3.1 说话人嵌入的使用
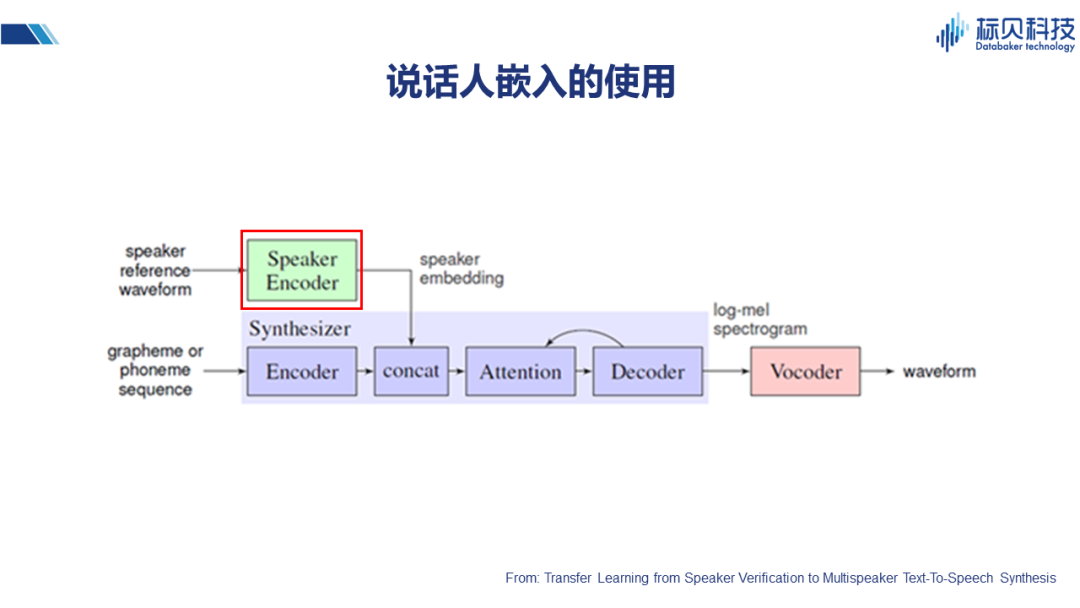
除情感标签之外,比如说这篇文章,提到用说话人入嵌Encoder 的方式。也就是将说话人的声音特征,通过编码器得到speaker embedding,并将其结合到Attention的网络中,实现不同说话人声音合成的效果。 我们其实可以从另外一个角度考虑,情感是什么?或者不同的变化是什么?它可以是情感本身、不同说话人、以及语言风格等等。所以上述说话人嵌入的方式,其实对整个情感合成也会有一定的借鉴作用。 2.3.2 风格嵌入的使用
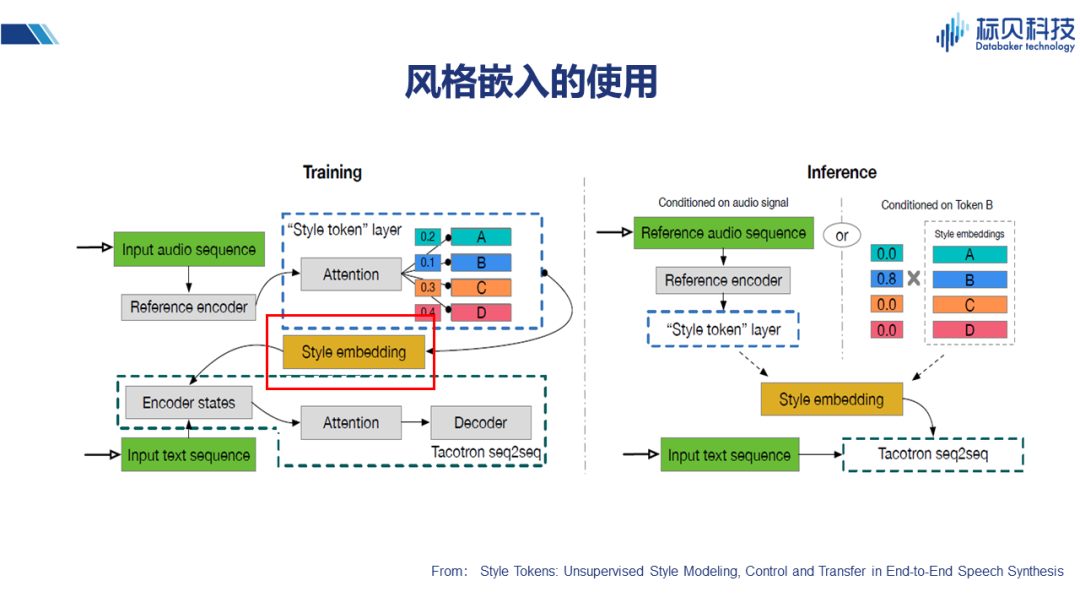
这篇文章介绍的是通过一个稍微复杂些的子网络实现风格的嵌入,其整体核心框架也同样是Tacotron系列。方法是在子网络中构建一个风格的分类,在进行风格分类embedding之后,与之前文本的encoder 结果一同加入到网络当中去。在推理的时候,通过风格的控制来改变整体合成的效果。 2.3.3 声学特征&说话人嵌入的使用
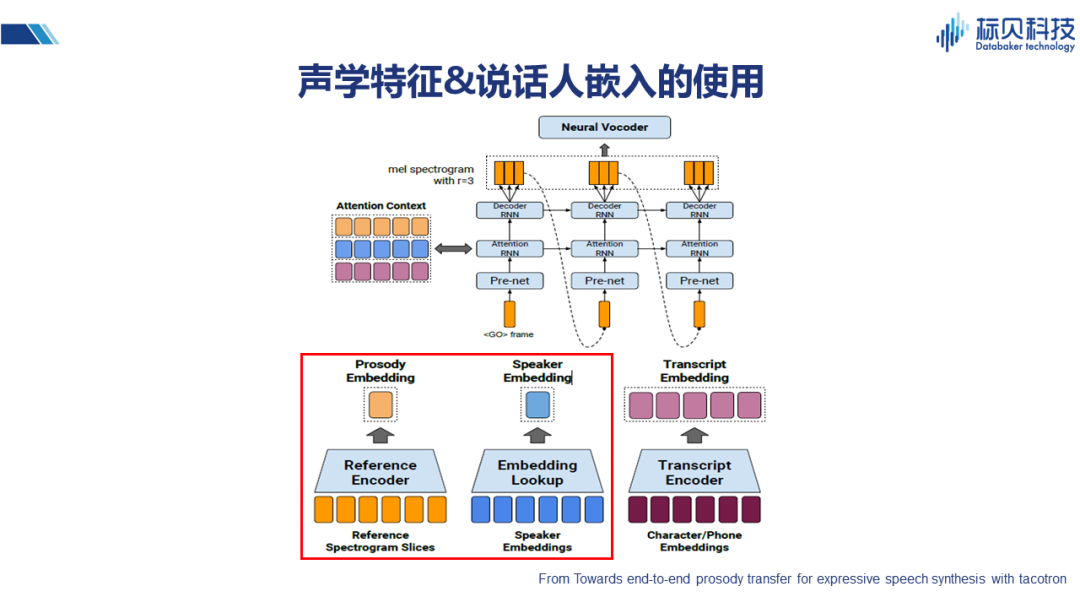
这篇文章也是类似的思路,除文本特征之外,再通过look up table 来做说话人的嵌入,通过谱的片段进行韵律的嵌入,最后将三种嵌入合成起来,作为影响整个系统的控制因素。 2.3.4 VAE的使用
除了上述提到的情感嵌入、说话人嵌入、风格嵌入之外,还有一种VAE的方法。它将谱的特征通过一个唯一的网络 — 子网,在学习到特征之后,与文本特征一同输入到Attention的网络(在这里选择的是Tacotron2的网络)。 综上可知我们的网络主体基本上是一个Attention 机制的网络(如Tacotron或Tacotron2),在这个主体之上,我们会加入一些特征,这个特征可以是各种各样的标签作为输入。也就相当于把风格、情感等变量单一或者组合使用,引入到整个系统当中。 以上就是当前可以看到的文献中出现的一些情感合成方案。 2.3.5 情感合成数据
数据是另外一个制约系统整体表现力的因素,在情感合成数据方面,我们面临着很多的问题。 比如我们需要数据有情感表现力,所谓情感表现力是指在听到一段声音后,能够明显感知到说话人是高兴的、生气的、还是忧伤的,这也是我们现阶段希望能够解决的一个问题。还有就是情感控制,说话人情感表现的程度,有的比较轻微,有的是比较强烈,我们做数据的时候,应该选择哪一种?前景网络如果情感过于强烈,并且波动范围很大的话,对于建模的要求就会非常高。那么我们就希望能够在数据层面,对情感的控制有一个度量。 第三点,也就是数据的规模,我们知道对于神经网络来说,数据规模越大,则整体效果越好,当然这是一个理想的情况。而现实是,我们在对情感表现力和情感控制方面要求比较严格时,往往只能采用同一个人的不同情感声音数据,那么数据规模本身就会受到一定限制,因此数据规模也是制约情感合成技术发展的一个关键点。
接下来介绍下我们所做的一些工作,标贝科技专注于提供人工智能数据的服务,同时也提供高音质,多场景,多类别语音合成的整体解决方案。我们希望在做高质量语音合成数据的同时,能够为中小型企业提供更多优质的解决方案,帮助解决他们的问题。 同样,我们也希望能够为整个语音行业提供一些基础的数据支持。比如2017年,我们就将一个10000句话规模的高质量语音合成库共享给了整个行业进行学术研究,希望能够跟大家一起将语音技术做的越来越好。
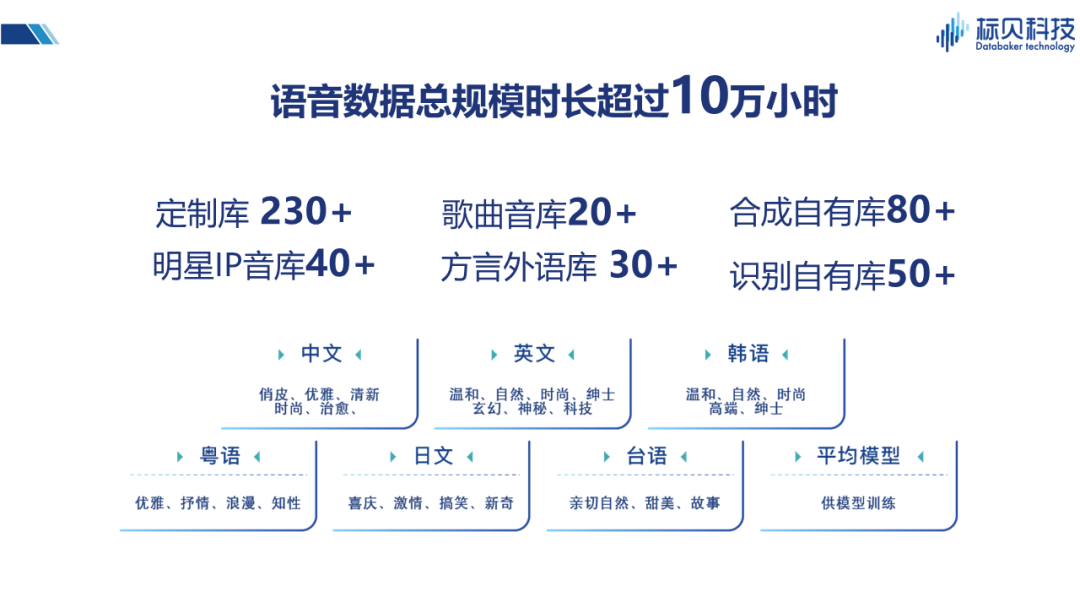
在数据方面,我们拥有包括识别自有库,合成自有库,歌曲音库、明星IP音库、以及方言音库等在内的多种不同类型的语音数据库,语音数据时长累计超过十万小时,这些数据有很多也应用到了我们的情感合成实践当中。 03 标贝科技情感合成实践

在情感合成实践当中,我们主要应用到了三类数据。 第一类是多人的数据库,规模并不是特别大,在使用时大概是100人左右的规模。这100人里,每个人会说500句话,其中300句话是相同的,200句话是不同的。在不同人之间,实际上也会有一些共性的东西,有一些不同的东西。在发言人方面,覆盖了从儿童、青年、老年等不同年龄段,这样做的好处是它可以让我们学习到不同年龄段人说话的特点。这些特点可能是受说话人自己的知识背景、生活环境影响,或者是生理因素(比如声带的发育阶段,声带的老化情况等)影响而形成。 第二类数据,用到了一些中大规模的合成数据库。这些数据库有的是男生的、有的是女生的,数据规模比多人数据库要大很多,基本上都是几千句的,几万句的规模。 第三类数据库是情感数据库。情感数据库中包含六种情感形式,悲伤、愤怒、惊讶、恐惧、喜悦和厌恶。除此之外,还包括同说话人的中性声音,即不带情感比较平稳的声音。所以实际上这个情感数据库,包括六种情感和一种中性的声音,七种声音都是同一个发音人。
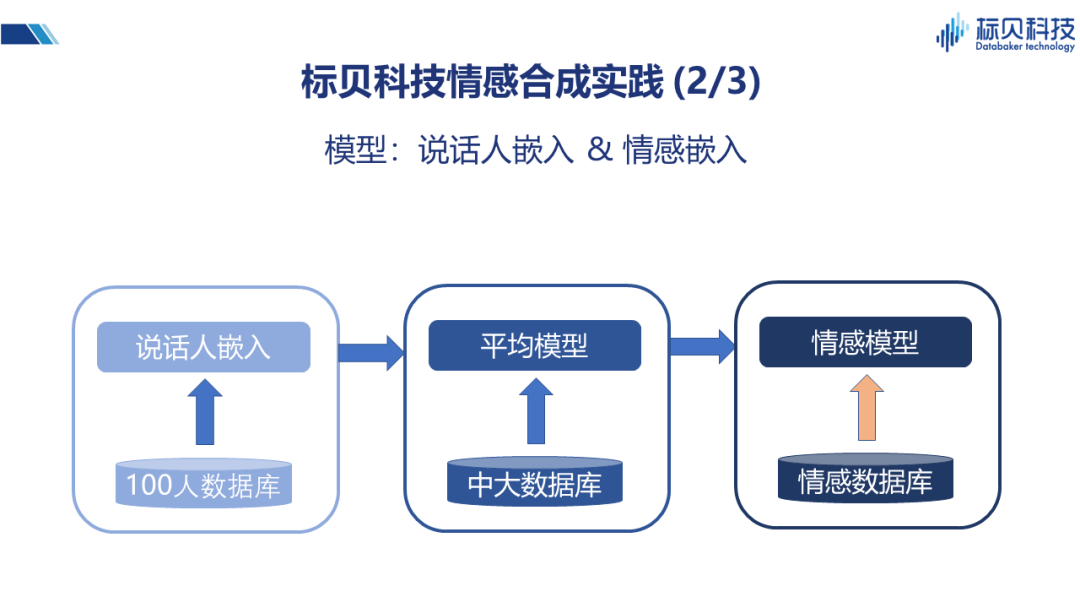
上述三类数据的用途各不相同:100人数据库,主要用来做说话人嵌入的网络。假如我们通过一个神经网络来刻画每个人,用向量表示的话应该是什么样?在这里我们用了一个神经网络来专门做说话人嵌入的向量训练。 第二个阶段,中大规模的数据库做平均模型。我们将说话人的嵌入与数据结合起来,做了一个平均模型。因为输入的文本和发音之间有一定的对应关系,所以平均模型相对来说比较稳定。 最后,我们就可以利用情感数据库结合平均模型,实现情感语音合成的模型。

这是一个情感合成的样音,不同的情感是存在明显差别的,我们能从声音里感受到情感的变化。这里我们并没有采用WaveNet或者复杂度比较高的声码器,因为我们想做的是一个能够在线上提供大规模并发服务的系统,所以选择的是LPC Net,在音质方面还不是最好的。
随着情感合成技术的发展,接下来还会有哪些应用场景?例如刚才听到的语音故事,我们就可以将它应用到有声读物上。还有就是语音助手,近年来随着NLP技术的发展,语音助手开始逐渐走进大家的生活中,帮助人们完成一些简单的工作。虚拟形象近年来发展的也比较好,例如虚拟主持人、虚拟歌手、虚拟的形象,能够具有一定的情感表现能力。 除此之外,抖音、快手等UGC创作平台,其中不乏有意思的故事、视频,但部分内容配音需要找一些专业的人员录制,很多内容创作者并没有这个条件。最近我们发现有许多创作者开始将语音合成(成本更低)结合到内容创作中,让内容变得更加生动、有趣。 那么更进一步,例如游戏和影视动画等领域,在具有一定情感表达能力后,对于一些非实时的产品,我们可以通过WaveNet的高质量生成器合成更高质量的语音内容,同样具有一定潜力。 04 情感合成技术展望
但在进行这些场景的广泛应用之前,我们还需要解决如下问题: 首先是NLP相关的问题,例如我们想要表达一个情感,需要知道这个情感是什么,不能用高兴的声音去说一件悲哀的事情,反之亦然。这就需要NLP有非常准确的情感分析与表达能力,不是60%、70%,我们希望至少是90%及以上,这样用户的接受度才会更好。 同样,刚刚提到的有声读物。例如一本小说,小说里的角色众多,如果每个人用不同的声音去表现,每个人又都有其自己的感情,那这本小说就可以通过听的方式表现的活灵活现,这也就要求NLP具有更高的角色分析能力。 还有涉及到语音合成的挑战:不同说话人之间的情感迁移,例如对于没有情感的声音,可不可以通过一些类比或者迁移技术,把别人的情感和非情感的差异,在一个没有情感数据的声音上进行呈现;小数据量的个性化情感合成,我们前段时间推出了标贝留声机的一个小数据的个性化合成,这里面并没有涉及到情感。如果我们还是在这个数据规模下,每种情感加上一句话,是不是可以实现? 涉及到交互,如果想让其更有深度,我们是不是能够感知到与机器进行交互的人的情感。比如现在的一些心灵电台等,有些人遇到挫折、困难的时候跟他聊聊天,讲个故事安慰一下,我觉得对社会来说是一件非常有意义的事情。 另外就是声音和形象的组合,例如我们现在看到的虚拟形象,在口型与声音对应一致性上,已经有明显的进步,甚至已经能够完成一些虚拟动作的实现。如果能够加上有情感的声音以及有表现力的表情,就可以应用到影视、动画等这些高难度的场景了。 所以,在情感合成方面,实际上我们只是进行了一些初步的探索,距离实现大范围的快速、广泛应用,仍需继续努力。
-
语音识别
+关注
关注
37文章
1635浏览量
111822 -
语音合成
+关注
关注
2文章
80浏览量
16017
原文标题:情感语音合成技术难点突破与未来展望
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论