 由浅入深的一步步迭代出无锁队列的实现原理
由浅入深的一步步迭代出无锁队列的实现原理
这篇长文除了由浅入深的一步步迭代出无锁队列的实现原理,也会借此说说如何在项目中注意避免写出有 BUG 的程序,与此同时也会简单聊聊如何测试一段代码,而这些能力应该是所有软件开发工作者都应该引起注意的。而在介绍的过程中也会让你明白理论和实际的差距到底在哪。
高级程序员和初级程序员之间,鱼鹰认为差距之一就在于写出来的代码 BUG 多还是少,当然解决 BUG 的能力也很重要。
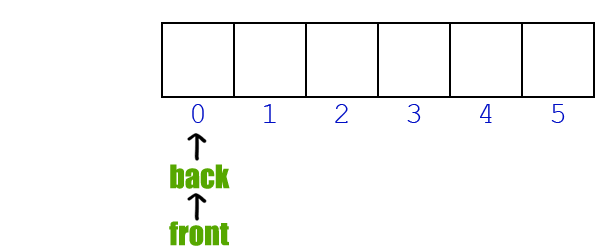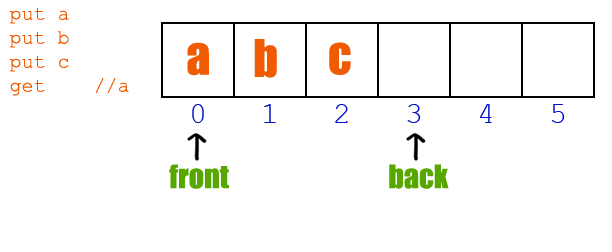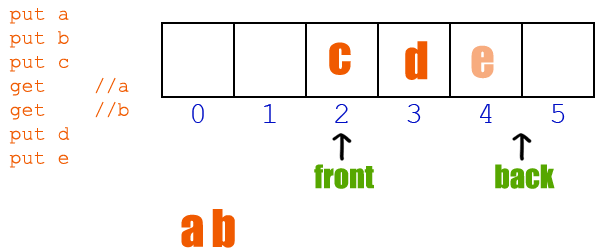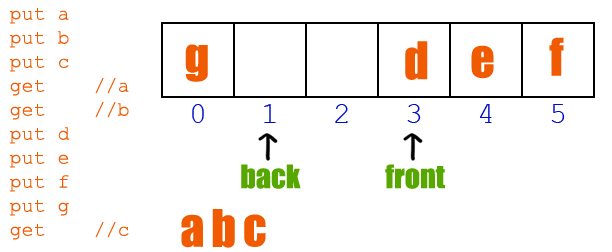
既要有挖坑的能力,也要有填坑的实力!
很早之前鱼鹰就听说过无锁队列,但由于以前的项目不是很复杂,很多时候都可以不需要无锁队列,所以就没有更深入的学习,直到这次串口通信想试试无锁队列的效果,才最终用上了这一神奇的代码。
网上有个词形容无锁队列鱼鹰觉得很贴切:巧夺天工!
现在就从队列开始说起吧。
什么是队列,顾名思义,就类似于超市面前排起的一个队伍,当最前面的顾客买完了东西,后面的顾客整体向前移动,而处于新队头的顾客继续消费。如果没有后来的顾客,那么最终这个队伍将消失。而如果有新的顾客到来,那么他将排在队伍最后等待购买。
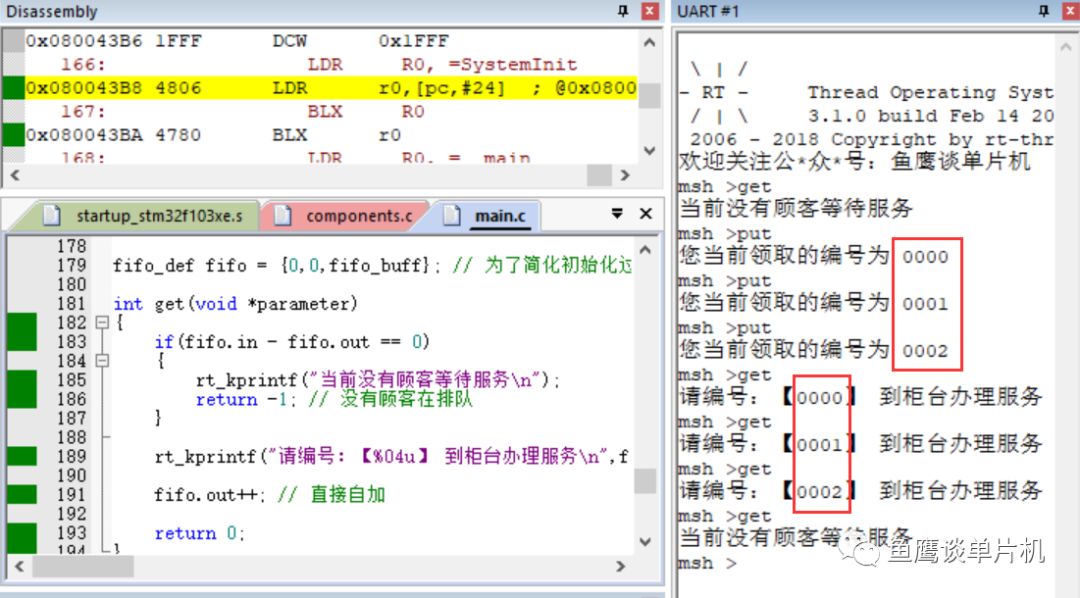
(忽略后面那个捣蛋的你) 对于顾客队伍来说,消费者,在这里其实是超市(不是顾客),因为它让这个队伍越来越短,直至消失;而生产者,在这个模型中无法看到,只能说是市场需求导致队伍越来越长。 如果对此较难理解的话,不如说说目前口罩购买情况。 如果市场上所有的口罩会自动排队的话,那么购买口罩的人就是口罩队伍的消费者,而生产口罩的厂家就是生产者。因为厂家生产的少,而购买者多,所以才会出现供不应求的情况,而一旦厂家产能上来了,供需就能平衡,而这种平衡不仅是市场需要的,也是软件所追求的目标。 说回超市模型,如果我们用软件模拟这种排队情况,应该怎么做呢? 声明一个足够大的数组,后面来的数据(顾客)总是放在最后面,一旦有程序取用了数据,那么整体向前移动,后面来的数据继续放在最后。(这里需要一个变量指示队伍的长度,毕竟不是真实的排队场景,无法直接从队伍本身看出哪里是队尾)。 这样确实很好的模拟了现实中的情况,但对于软件来说,效率太低! 对于顾客而言,所有的顾客每次前进一小步,感觉好像没什么,也很正常,毕竟最终等待的时间还是一样的,但是每隔一小段时间就要动一动,还是挺麻烦的事情。 而对于程序而言,不仅仅是移动数据需要耗费CPU,更重要的是在移动过程中,如何保证“消费者”能正确提取数据,“生产者”能正确插入数据。毕竟你在移动数据的过程中有可能消费者需要消费数据,而生产者需要生成数据,如何进行同步呢? 那么是否有更好的方式呢? 现实其实已经给了我们答案。 不知道你是否发现一个现象,银行里面一排排的椅子上坐满了人,但是银行窗口前却没有了长长的队伍?这是怎么回事?为什么那些人不再排队了,他们不怕有人插队吗? 当你亲自体验了之后就知道,没人会插你的队,为什么? 当你走进银行时,服务员会提醒你去一台机器前领取一个纸质号码,然后就请你在座位上等着。 等了一会,银行内广播开始播报“9527,请到2号柜台办理业务”,你一听,这不就是自己刚领的号嘛,所以你马上就到窗口前办理需要的业务了。 那么这是如何实现的?为什么你不再需要站着排队了,也不需要一点一点的向前挪动,而是一直坐着就把队给排了? 这个关键就在那台机器。 每来一个人领取号码,机器就把当前的计数值给顾客,然后增加当前的计数,作为下一位顾客使用的号码;而每当银行柜员服务完一位顾客,机器就会自动播报本次已服务对象号码的下一个号码前来办理业务,并自加另一个计数值,作为下一次办理业务的对象。而当两计数器值相等时,就代表该柜员完成了所有顾客的服务。 所以,不是没有排队,而是机器在帮你排队。 那么这种机制在程序中该如何实现呢? 在这里我们先假设只有一个柜台能办理业务(实际银行是有多个柜台,这里暂时不考虑那么复杂),一个机器为顾客发放编号。 首先需要两个变量充当机器的职能: in:初始化为 0,当来了顾客,将当前值发给客户,然后自动加 1 out:初始化为 0,当柜员需要请求下一位顾客前来服务时,服务顾客编号为当前值,然后自动加 1 因为纸条上可展示的位数是有限的,所以我们可以先假设为4位数,即两个变量值范围是0~9999(还好STM32F103 RAM内存足够)。 然后需要一个元素容量为10000大数组,存放目前排队顾客的编号,因为数组中存放的是0~9999的编号,所以数组的声明采用uint16_t 进行声明,这样才能把编号存放在数组单元中。 现在看代码(RT-Thread系统):
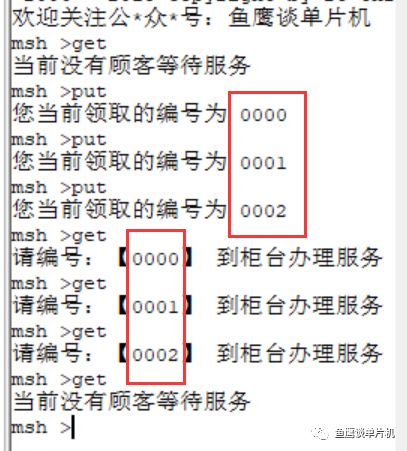
// 鱼鹰*公***众**号:鱼鹰谈单片机,uint16_t queue[10000]; // 队列,0~9999,共 10000 uint16_t in;uint16_t out; int get(void *parameter){ if(in == out) { rt_kprintf("当前没有顾客等待服务 "); return -1; // 没有顾客在排队 } rt_kprintf("请编号:【%04u】 到柜台办理服务 ",queue[out]); // 自加 1 ,但因为数组只有 10000 大小,所以需要让 out 在 0~9999 之间进行循环 out = (out + 1) % 10000; return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); int put(void){ if((in + 1) % 10000 == out) { // 因为 in 和 out 值相等时,可能为空和满的,无法判断哪种情况 // 所以为了避免这种情况,总是空一个位置,这样满的时候 in 和 out 的值就不一样 rt_kprintf("现在排队人数太多,请下次尝试 "); return -1; // 队列满 } // 把当前的编号存入数组中进行排队 rt_kprintf("您当前领取的编号为 %04u ",in); queue[in] = in; // 自加 1 ,但因为数组只有 10000 大小,所以需要让 in 在 0~9999 之间进行循环 in = (in + 1) % 10000; return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);(滑动查看全部) 现在假设柜员刚开始上班,他不清楚有没有顾客等待服务,所以他首先使用 get函数获取自己的服务顾客编号,但是因为柜员来的有点早,顾客还没来银行办理业务,所以第一次机器告诉柜员没有顾客等待服务。

后来陆续来了三位顾客,柜员再一次获取时,编号为 0 的顾客开始前来办理业务,柜员服务完之后,接着继续把剩下两位的业务都办理完成,第四次获取时,柜员发现没有顾客等待了,所以柜员可以休息一下(实际情况是,柜员前应该有显示当前排队人数,当排队人数为 0 时,就不会去使用 get 函数了)
V 1.0
虽然可显示的位数为四位数,有可能出现一天共有9999位顾客需要办理服务,但事实上同一时刻不可能有那么多人同时在银行排队办理业务,所以为了节约空间,有必要缩小数组空间。 假设一次排队最多同时有99位顾客需要业务,那么数组设置为 100(为什么多一个?)。 但是因为一天之中总共可能有超过 99 位顾客办理业务,那么直接使用in作为顾客编号肯定不合适,因为in的范围是0~99,那么必然需要另一个变量用于记录当天的总人数,这里假设为counter(当你修改代码时,你会发现把之前的 10000 设置为宏是明智的选择)。 这里除了修改数组大小和put函数外,其他都一样:
// 测试代码 V1.0// 鱼鹰*公***众**号:鱼鹰谈单片机,#define BUFF_SIZE 100uint16_t queue[BUFF_SIZE]; // 队列,0~99,共 100 uint16_t in;uint16_t out;uint16_t counter; // 记录 int get(void *parameter){ if(in == out) { rt_kprintf("当前没有顾客等待服务 "); return -1; // 没有顾客在排队 } rt_kprintf("请编号:【%04u】 到柜台办理服务 ",queue[out]); // 自加 1 ,但因为数组只有 100 大小,所以需要让 out 在 0~99 之间进行循环 out = (out + 1) % BUFF_SIZE; return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); int put(void){ if((in + 1) % BUFF_SIZE == out) { // 因为 in 和 out 值相等时,可能为空和满的,无法判断哪种情况 // 所以为了避免这种情况,总是空一个位置,这样满的时候 in 和 out 的值就不一样 rt_kprintf("现在排队人数太多,请下次尝试 "); return -1; // 队列满 } // 把当前的编号存入数组中进行排队 rt_kprintf("您当前领取的编号为 %04u ",counter); queue[in] = counter; counter = (counter + 1) % 10000; // 限制它的大小,不可超过四位数 // 自加 1 ,但因为数组只有 100 大小,所以需要让 in 在 0~99 之间进行循环 in = (in + 1) % BUFF_SIZE; return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);(滑动查看全部) 再次测试:
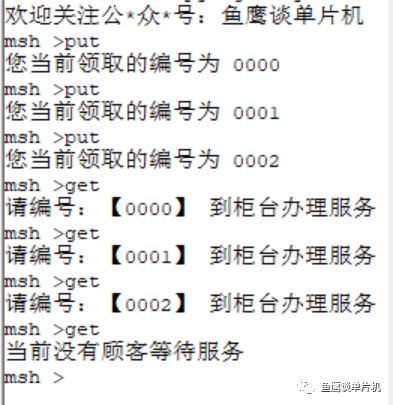
你会发现,虽然修改了数组大小,但是只要不会出现同时超过100人来银行排队,那么和之前的效果是一样的,这样一来,大大降低了内存空间使用。 这里展示的效果其实和《数据结构系列文章之队列 FIFO》写的类似了,这里鱼鹰定为V1.0吧(对,前面那个版本连V1.x都算不上,因为太耗空间了)。 那么鱼鹰继续写另一种处理方式,称之为V1.5吧。
V 1.5
虽然因为一个神奇的取余公式,可以让一个数始终在某一个范围内变化,但这也带来非常一个明显的问题,那就是始终不能把队列真正填满。
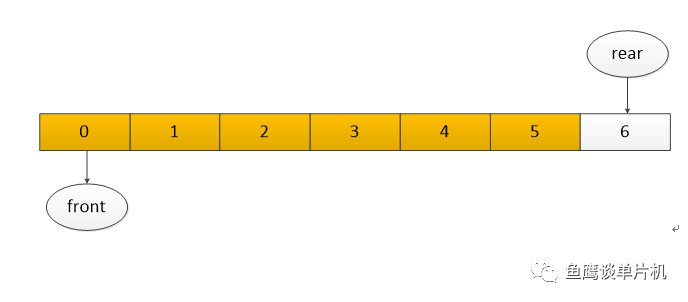
虽然只是空闲了一个元素,但是对于喜欢追求极致的人来说,这也是不可忍受的事情,所以是否有好的办法利用所有队列空间呢? 这里再加入一个变量,实时跟踪队列长度,代码如下:
// 测试代码 V1.5// 鱼鹰*公***众**号:鱼鹰谈单片机#define BUFF_SIZE 7 typedef struct { uint16_t queue[BUFF_SIZE]; // 队列,0~99,共 100 uint16_t in; uint16_t out; uint16_t used;}fifo_def; // 把队列相关的变量整合在一块,方便使用 uint16_t counter; // 记录 fifo_def fifo; int get(void *parameter){ if(fifo.used == 0) { rt_kprintf("当前没有顾客等待服务 "); return -1; // 没有顾客在排队 } rt_kprintf("请编号:【%04u】 到柜台办理服务 ",fifo.queue[fifo.out]); // 自加 1 ,但因为数组只有 100 大小,所以需要让 out 在 0~99 之间进行循环 fifo.out = (fifo.out + 1) % BUFF_SIZE; fifo.used--; return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); // 导出到命令行中使用 int put(void){ if(fifo.used >= BUFF_SIZE) { // 因为 in 和 out 值相等时,可能为空和满的,无法判断哪种情况 // 所以为了避免这种情况,总是空一个位置,这样满的时候 in 和 out 的值就不一样 rt_kprintf("现在排队人数太多,请下次尝试 "); return -1; // 队列满 } // 把当前的编号存入数组中进行排队 rt_kprintf("您当前领取的编号为 %04u ",counter); fifo.queue[fifo.in] = counter; counter = (counter + 1) % 10000; // 限制它的大小,不可超过四位数 // 自加 1 ,但因为数组只有 100 大小,所以需要让 in 在 0~99 之间进行循环 fifo.in = (fifo.in + 1) % BUFF_SIZE; fifo.used++; return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);在这个版本中,鱼鹰将队列所需的元素整合成一个结构体方便使用(当需要增加一个队列时,显得比较方便),并加入一个used变量,还缩小了队列大小,变成7,方便我们关注队列最本质的东西。 测试如下:
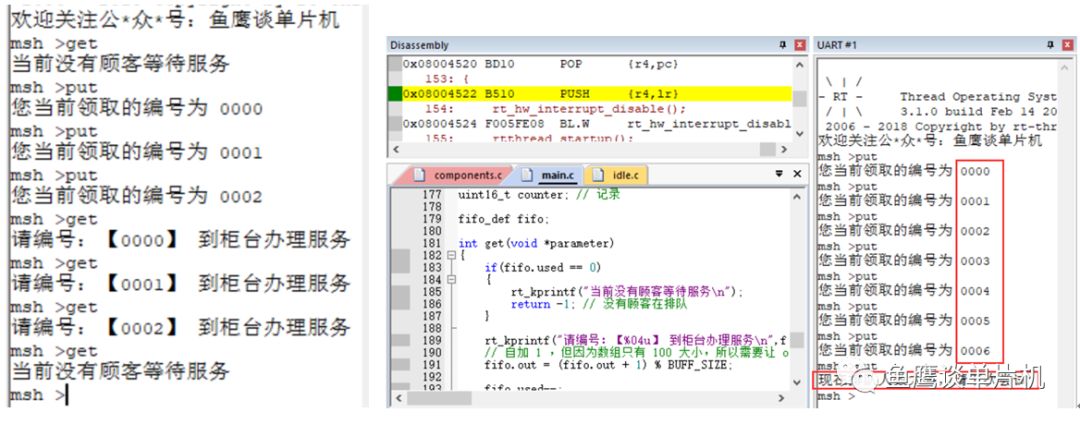
因为增加了一个变量,所以可以完整利用所有空间,但是是否有更好的方式呢? 有的,就是今天的主角,无锁队列。
V 2.0
这还不是无锁队列的最终形态,而是一个初版,但已经是无锁队列中最核心的内容了,也是实现无锁队列的关键,定为V2.0。 测试代码:
// 测试代码 V2.0// 鱼鹰*公***众**号:鱼鹰谈单片机#define BUFF_SIZE 8 // 文章说的是 7,但是这是不能用的,只能为 2 的幂次方 typedef struct { uint32_t in; // 注意,这里是 32 位 uint32_t out; // 注意,这里是 32 位 uint8_t *queue; // 这里不再指定大小,而是根据实际情况设置缓存大小}fifo_def; // 把队列相关的变量整合在一块,方便使用 uint8_t counter; // 记录人数,也是发放的编号,因为队列类型变了,所以这里也改成 uint8_tuint8_t fifo_buff[BUFF_SIZE]; fifo_def fifo = {0,0,fifo_buff}; // 为了简化初始化过程,直接定义时初始化 int get(void *parameter){ if(fifo.in - fifo.out == 0) { // 也可以写成 fifo.in == fifo.out,效率或许会高一些 rt_kprintf("当前没有顾客等待服务 "); return -1; // 没有顾客在排队 } rt_kprintf("请编号:【%04u】 到柜台办理服务 ",fifo.queue[fifo.out % BUFF_SIZE]); fifo.out++; // 直接自加 return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); // 导出到命令行中使用 int put(void){ if(BUFF_SIZE-fifo.in+fifo.out==0) { rt_kprintf("现在排队人数太多,请下次尝试 "); return -1; // 队列满 } // 把当前的编号存入数组中进行排队 rt_kprintf("您当前领取的编号为 %04u ",counter); fifo.queue[fifo.in % BUFF_SIZE] = counter; // 这里用 fifo.in % (BUFF_SIZE - 1) 效率会高一些 counter += 1; // 递增计数器 fifo.in++; // 直接自加 return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample);
这里最难理解的部分应该是两个判断:
if(BUFF_SIZE - (fifo.in - fifo.out) == 0) { rt_kprintf("现在排队人数太多,请下次尝试 "); return -1; // 队列满 } if(fifo.in - fifo.out == 0) { // 也可以写成 fifo.in == fifo.out,效率或许会高一些 rt_kprintf("当前没有顾客等待服务 "); return -1; // 没有顾客在排队 }还有两个不可以思议的自加操作:
fifo.in++; // 直接自加 fifo.out++; // 直接自加现在先说第一个简单的,为什么in和out相等了,就代表为空? 先看一个动图(公**众&&号可查看):
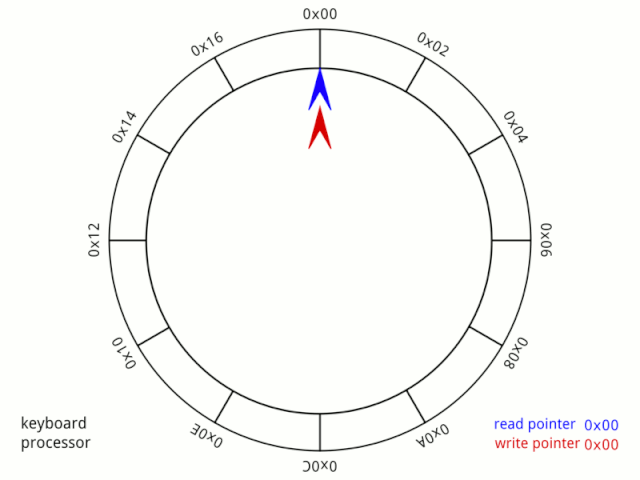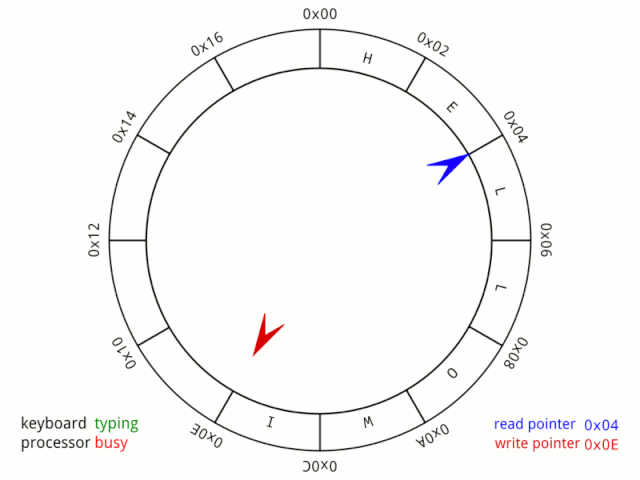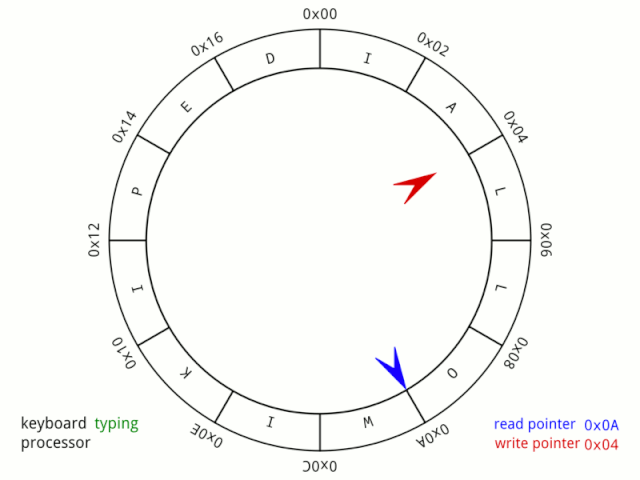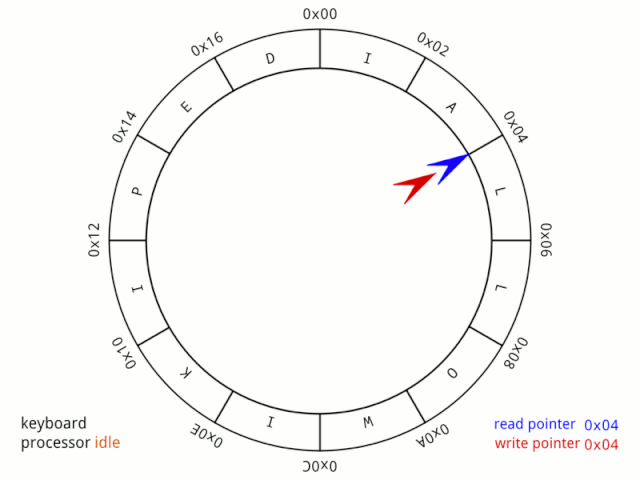
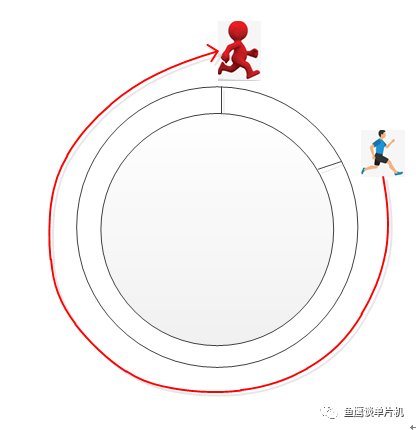
我们可以这样理解,小红、小蓝两个人在一个环形操场跑步,在起步时,两个人的位置一样,但跑了一段时间时,两人位置不同了,因为小红跑的快,所以总在小蓝前面,但他们是好朋友,所以小红总是在跑了一段时间后停下来等小蓝。 虽然小蓝跑的慢,但因为小红的等待,所以每次追上小红处于同一个位置时,都可以认他们又处于起步阶段,就好像他们从来没有动过。 也就是说in和out相等时,就可以认为队列为空。 那么第二个判断该怎么理解? 这个说实话,鱼鹰不知道该如何说明,只能强行解释一波了(说笑的,不过确实很难说清楚)。 首先这个公式需要简单变换一下:
BUFF_SIZE - (fifo.in - fifo.out)内括号里面的其实就是《延时功能进化论》中说的那个神奇的算式。 这个算式总是能准确in和out之间的差值(不管是in大于out还是小于),也就是队列中已使用了的空间大小,当然这是有条件的。 想象一下这样一个场景,小红不再等待小蓝,而是一口气跑下去,当小红再次接近小蓝时,你会发现小红看到的是小蓝的后背,也就是说,从表象来看,小蓝跑到小红的前面了。 但是群众的眼光是雪亮的,他们知道小红其实是跑在小蓝的前面的,所以按小红在小蓝前面这种情况用尺子量一下两者就能准确知道两者的距离。
我们现在继续分析,因为小红跑太快了,它超越了小蓝!
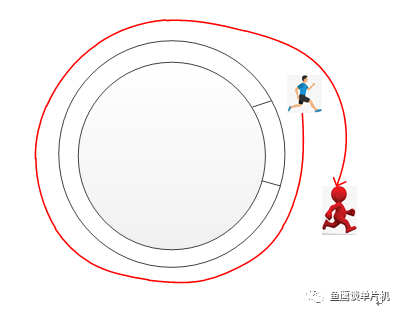
虽然观众还是可以通过尺子进行距离测量,但是如果单从操场绝对位置(假设操场上有距离刻度)的角度来看,已经无法准确计算他们的距离了(当然如果能记录小红超越小蓝的次数,那还是可以计算的,现在按下不表)。 所以如果把 in 当成小红操场所在的刻度信息,out当成小蓝的操场刻度信息,那么两者 in 减 out 就是他们的距离信息(当然了,这里利用了变量溢出的特性才能准确计算,关于这个可以看《运算符 % 的妙用》)。 上面动图的队列空间是0x18,即24,如果我们把这个队列空间增大,增大到四个字节大小4294967295 + 1怎么样? 然后给你一把长度为 7 的尺子,让你能准确测量小红和小蓝的距离,你会怎么做(想象一下这个场景)? 因为尺子能测量的距离太多,而小红跑的太快,所以你必须约束一下小红,让他在距离小蓝为7或者更短的距离时必须停下来等小蓝或者放慢速度! 就像两者被尺子绑住了一般,距离只能短,不能长。 由此我们就可以同时理解下面这个公式和in与out的自加了。
BUFF_SIZE - (fifo.in - fifo.out) fifo.in++; // 直接自加 fifo.out++;//直接自加 BUFF_SIZE 就是这把尺子,而 in 和 out 相减可以得到两者距离,尺子总长减去两者距离,就可得到尺子剩余可测量的距离,也是小红还可再跑的距离。 而一直自加其实就是利用变量自动溢出的特性,而即使溢出导致 out 大于 in 也不会影响计算结果。 看一个动图结合理解溢出(公**众&&号可查看):

那为什么这里使用32位无符号整型,可不可以用8位数? 不可以,起码在上面那个公式下是不可以的(可以稍作修改)。 这里其实涉及到计算机最为基础的知识(基础不牢,地动山摇,不过还好鱼鹰掌握一点汇编知识和许多调试技巧)。 现在鱼鹰把 in 和 out 修改为 8 位无符号数,然后测试当 in = 0 和 out = -7(因为是无符号,这里其实是249),开始测试这个公式:
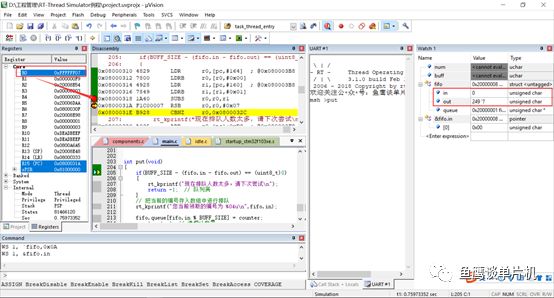
你会发现in - out = 0xFFFF FF07(这个结果会导致顺利执行put函数,而不是直接退出),而不是0x0000 0007,这是因为计算8位数时,采用的是32位整型计算,也就是运算等级提升了,就类似浮点型和整型一起混合计算,自动使用浮点计算! 但是当你使用32位数声明in和out,还是in = 0,out = -7(其实是4294967289),那么计算结果就完全不一样了(变成了0x0000 0007,put函数直接退出)。
这里讲的太细了,使道友少了很多独立思考,现在留个问题给各位,为什么选择 -7 ? 写完这部分,鱼鹰才发现 V2.0 版本是存在 BUG 的,原因就在于存储数据和读取数据那需要注意的代码,之前鱼鹰想当然的认为直接取余 % 即可正确读取和存储数据,实际上因为 7 这个数根本不能被 0xFFFF FFFF + 1 给整除,也就无法正确使用了,所以V2.0版本无法使用,但如果把 7 换成 8,就没有问题了,这里需要特别注意(还好提早发现了,不然就是误人子弟了)。 好了 ,终于把最难理解的部分勉强说完了! 但是目前这只是前菜,还有很多。 现在继续。 因为 in 和 out 一直自加,所以不像 V1.0 一样出现空和满时 in 和 out 都是相等,也就不需要留下一个空间了,完美的利用了所有可用的空间! 但是 in 和 out 总是自加,必然会出现 in 和 out 大于空间大小的情况,所以在取队列中的元素时必须使用 % 限制大小,才能准确获取队列中的数据(前提是队列大小为 2 的幂次方),而 get 和 put 开头的判断总能保证in大于或等于out(这个只是从结果来看是这样,但实际有可能 in 小于 out,但这个不影响最终结果),而in – out 小于或等于队列大小,防止了可能的数组越界情况。
V 2.5
现在开始介绍真正的无锁队列。 如果仅仅从无锁的角度来说,前面几个版本除了 V1.5 外其实都是无锁模式了(后面会说为什么 V1.5 不是无锁),那为什么还要升级?目的何在?。 不知道你是否还记得笔记开头鱼鹰曾说因为效率太低而未采用循环队列,为什么,因为按照目前的实现来说,每次 get 都只能获取一个队列元素,而每次 put 也只能写入一个元素,这对于大量队列元素的拷贝来说效率非常低下(比如从队列中拷贝大量串口数据)。 假如说你从队列中获取所有的数据,常规方式你只能使用 get 函数一个一个元素的取出,每次 get 除了函数体本身的运算外(判断是否为空、调整索引、取队列元素、自加 out),还有进入、退出函数的消耗,如果获取的数量少还好,一旦多了,这其中的消耗就不得不考虑了。 而put函数同理。 所以存在大量队列数据拷贝的情况下,以上各个版本都是不合适的,所以有必要进行优化升级! 既然上述版本不合适,我们就会思考,如果能仅从in和out的信息就能拷贝所有队列中的数据那该多好。 事实上,linux 中的无锁队列实现就是利用 in 和 ou t就解决了大量数据拷贝问题。 而这个拷贝思想如果能运用在块存储设备,那么将极大简化代码。 那么我们来看看无锁队列是如何实现的。 首先上代码(鱼鹰为了方便说明和测试,未提供完整函数,这个可后台领取):
// 测试代码 V2.5// 鱼鹰*公***众**号:鱼鹰谈单片机#define BUFF_SIZE 8 typedef struct { uint32_t in; // 注意,这里是 32 位 uint32_t out; // 注意,这里是 32 位 uint32_t size; // 设置缓存大小 uint8_t *buffer; // 这里不再指定大小,而是根据实际情况设置缓存大小}fifo_def; // 把队列相关的变量整合在一块,方便使用 uint8_t counter; // 记录人数,也是发放的编号,因为队列类型变了,所以这里也改成 uint8_tuint8_t fifo_buff[BUFF_SIZE]; fifo_def fifo = {0,0,BUFF_SIZE,fifo_buff}; // 为了简化初始化过程,直接定义时初始化 void init(fifo_def *pfifo,uint8_t *buff,uint32_t size){ if(size == 0 || (size & (size - 1))) // 2 的 幂次方 { retern; } pfifo->in = 0 pfifo->out = 0; pfifo->size = size; pfifo->buffer = buff; } int get(void *parameter){ fifo_def *pfifo = &fifo; // 这里直接使用全局变量,因为命令行不方便传参 uint32_t len = 2; // 这里假设一次获取 2 个字节数据 uint8_t buffer[2]; // 将队列中的数据提取到这个缓存中 uint32_t l; len = min(len, pfifo->in - pfifo->out); /* first get the data from fifo->out until the end of the buffer */ l = min(len, pfifo->size - (pfifo->out & (pfifo->size - 1))); memcpy(buffer, pfifo->buffer + (pfifo->out & (pfifo->size - 1)), l); /* then get the rest (if any) from the beginning of the buffer */ memcpy(buffer + l, pfifo->buffer, len - l); pfifo->out += len; if(len) // 为了判断是否写入数据,加入调试信息 { for(int i = 0; i < len; i++) { rt_kprintf("请编号:【%04u】 到柜台办理服务 ",buffer[i]); } } else { rt_kprintf("当前没有顾客等待服务 "); } return 0; }MSH_CMD_EXPORT(get, RT-Thread first led sample); // 导出到命令行中使用 int put(void){ fifo_def *pfifo = &fifo; // 这里直接使用全局变量,因为命令行不方便传参 uint32_t len = 1; // 这里假设一次写入 1 个字节数据 uint32_t l; uint8_t buffer[1] = {counter}; // 存入编号,即将写入到队列中 len = min(len, pfifo->size - pfifo->in + pfifo->out); /* first put the data starting from pfifo->in to buffer end */ l = min(len, pfifo->size - (pfifo->in & (pfifo->size - 1))); memcpy(pfifo->buffer + (pfifo->in & (pfifo->size - 1)), buffer, l); /* then put the rest (if any) at the beginning of the buffer */ memcpy(pfifo->buffer, buffer + l, len - l); pfifo->in += len; if(len) // 为了判断是否写入数据,加入调试信息 { rt_kprintf("您当前领取的编号为 %04u ",buffer[0]); } else { rt_kprintf("当前没有顾客等待服务 "); } counter++;// 写完自加,不属于无锁队列内容 return 0;}MSH_CMD_EXPORT(put, RT-Thread first led sample); 首先说说和 V2.0 的主要区别: 1、将队列大小改为 8,即符合2的幂次方(这是in和out无限自加所要求的,也是一种限制) 2、将缓存名更改为buffer,更容易理解(所以取名字也很重要) 3、增加了一个变量size,这是方便在多个fifo情况可以使用同一个函数体(函数复用),通常这个值只在初始化时赋值一次,之后不会修改。 然后最难理解的就是那两个拷贝函数了。 现在着重说明一种特殊拷贝情况,当能理解这种特殊情况,那么其他情况也就不难理解了。 首先看两个min,这是用来取两者之间最小的那一个。
len=min(len,pfifo->in-pfifo->out);/* first get the data from fifo->out until the end of the buffer */ l = min(len, pfifo->size - (pfifo->out & (pfifo->size - 1))); memcpy(buffer,pfifo->buffer+(pfifo->out&(pfifo->size-1)),l);/* then get the rest (if any) from the beginning of the buffer */ memcpy(buffer+l,pfifo->buffer,len-l);开始的len是用户要求拷贝的长度,但考虑到用户可能拷贝大于队列已有数据的长度,所以有必要对它进行重新设置,即最多只能拷贝目前队列中已有的大小。 第二个min其实用来获取队列out开始到数组结束的大小,难理解?看下图就很清楚了:

所以,它获取的就是out到数组结束的地方,即上图5~7的数据,那么为什么它能从out这个值得到数组内的索引,它不是一直在自加吗?它肯定会出现超过数组的情况啊? 是的,你猜的没错,如果数组大小小于四个字节所表示的大小的话,它肯定会超过数组的索引值的,但你不要忘了,数组的大小是2的幂次方,也就是说out % size的余数必然还在数组中,即out这个值其实已经蕴含了数组索引值的信息的。 难理解,继续看之前的动态(没办法,资源太少啦):
当你只盯着后三位bit 数据,而不管前面有多少 bit 时,你就能理解了。 虽然 out 如上所示一直在自加过程中,但后三位(十进制 0 ~ 7)是自成循环的,而这自成循环的值就是我们的数组索引 0~7 的值,所以为了效率,可使用 & 运算(效率一说后面再讲)。 我们再进一步思考,因为它利用了最后的循环数作为数组的索引,在 in、out、size 都是四个字节的情况下,队列最大的长度是多大? 4 GB?毕竟 in 能表示的范围也就这么大了。 错,应该是 0x8000 0000,2 GB。因为如果是4GB的话,size 的值为 0x1 0000 0000,超过四字节大小了,所以队列大小被除了被 in、out 所限制,还被size限制了。 size – out 不就是数组右边部分的数据大小了,拷它! 然后数组开头部分剩余数据大小,拷它! 这样一来,就很清楚了,当你明白了这些,你会发现这两个拷贝函数能适应队列存储的各种情况,巧夺天工! 无锁队列的原理看似结束了,关键代码也介绍清楚了,但其实一个关键点到现在还没有进行说明,那就是,怎么它就是无锁了,而V1.5又为什么不是无锁? 无锁,有个很重要的前提,就是一个生产者,一个消费者,如果没有这个前提,以上所有版本都不能称之为无锁! 那么首先讨论,软件中的生产者和消费者到底是什么? 如果一个资源(这里可以是各种变量、外设)只在一个任务中顺序使用,那么无锁、有锁都没有关系,但是在多个任务中就不一样了。 那么现在再来说说这里的任务代表着什么?任务是一个函数,一个功能?是,也不是。 裸机系统中,main 算一个函数,也是一个主功能函数,但它可以算任务吗?算!系统中有很多中断处理函数,他们算一个个的任务吗?算!除此之外还有任务吗?没了! 操作系统中(以RT-Thread为例),main 算一个任务吗?算!RT-thread 将它设置为一个线程,所以系统中的所有的线程都是一个个的任务;中断处理函数算一个个的任务吗?算!除此之外还有任务吗?没了! 那么这里所说的任务是靠什么划分的?你总不能拍脑袋就定下来了吧,总要有依据有标准吧! 靠什么?靠的是一个函数会不会被另一个函数打断执行! 何为打断?打断是指一个函数正在执行,然后中间因为某种原因,不得不先执行别的函数,此时需要把一些临界资源保存以供下次恢复使用? 何为临界资源?说白了,就是一个个 CPU 寄存器,当你进行任务切换时,为了保证下次能回到正确的位置正确的执行,就需要把寄存器保存起来。 线程能在这称之为任务,就是因为当它被打断执行时(可能执行其他任务,可能执行中断处理函数),需要保存临界资源;而中断处理函数也是如此,虽然它保存临界资源时不是由CPU执行的,但它也要由硬件自动完成(STM32是如此)。 所以,这里所说的任务和你想的任务稍有不同,但为了方便理解,继续使用“任务”一词。 好了,清楚了任务,下面就简单了。 当一个资源同时被两个以上任务(比如一个线程和一个中断函数)所使用时,为了防止一个任务正在使用过程中被其他任务所使用,可能采取如下措施: 1、关中断(简单、高效) 2、使用互斥锁(操作系统提供) 3、使用特殊互斥汇编指令(单片机提供) 4、使用单位信号量(操作系统提供) 5、使用位带(单片机提供,理解彻底后会发现和无锁队列类似,详情看鱼鹰信号量笔记) 6、无锁队列实现 现在就来看看无锁队列是如何实现无锁的? 以前面所讲的终极串口接收(详情请看《终极串口接收方式,极致效率》)为例进行说明。 如果你认真分析两个函数,你会发现不管是 get 函数还是 put 函数,其实都只修改了一个全局变量,另一个全局变量只作为读取操作。所以虽然 in 和out(size 一直都只是读取)同时在两个任务中使用,但并不需要加锁。 当然修改的位置也很重要,它们都是在数据存储或者提取之后才修改的全局变量,如果顺序反了呢?以前鱼鹰说顺序的时候,都说先把资源锁占领了再说,但这里却不同,而是先使用资源,最后才修改,为什么?请自行思考。 那么为什么 V1.5 需要加锁呢?还记得那个 used 全局变量吗? 当 used 全局变量在一个任务中自加,在另一个任务中自减,而没有任何保护措施,你认为会发生什么? 你要知道,自加、自减C语言代码只有一条,但汇编语句却有多条。 首先读取used的值,然后加1或减1。如果两者之间被打断了,就会出现问题。 比如used 开始等于 5,一个任务1读取后保存到寄存器R0中准备加1,然后被另一个任务2打断,它也读取了used,还是5,顺利减 1,变成4,回到任务1继续加 1,变成了 6。最终used变成了6,但实际上因为执行了任务2,它此时应该还是 5的。 这样一来,used 就不能准确反映队列中已使用的空间了,只能加锁保护。 但是无锁队列却不会出现这种情况,因为它只修改一个属于自己的那个变量,另一个变量只读取,不修改,这才是无锁实现的关键之处! 无锁、无锁,其实是有锁!这里的锁是in和out这两把锁,各司其职,实现了无锁的效果(没有用关中断之类的锁),使数组这个共享资源即使被两个任务同时使用也不会出现问题。但是三个以上任务使用还能这么处理吗? 当然不能,因为这必然涉及到一个in或者out同时被两个任务修改的情况,这样一来就会出现used的情况,而且你还不能单纯只锁定in或者out,而需要同时把整个函数锁定,否则就会出现问题。 好了,到此无锁所有关键细节问题都清清楚楚,明明白白了,但是对于一个项目来说,这就足够了? 如果你认为掌握了理论就没问题了,那你就太天真了!
效率讨论
先上点小菜,之前一直有说 % 和 & 两个运算符效率的问题,那么它们效率差别到底多大? 以前鱼鹰刚开始接触循环队列时,以鱼鹰当时的水平根本就没有考虑效率的问题,就只是感觉 % 好神奇啊,然后到处用;也不明白为啥uCOS 的内存管理不用 % ,毕竟它是那么的神奇,是吧!
后来无意中看到说 % 效率比 & 低,那么低多少?我们来测试一下 V1.0 和V2.0 的执行效率好了。因为 V2.0 对大小有限制,那么就设置为 8 好了。 测试代码如下:
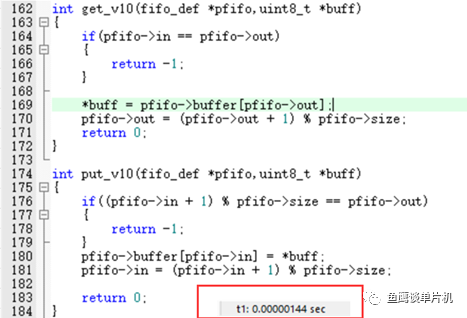
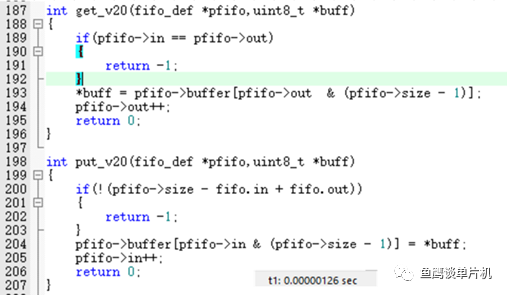
从测试结果来看1.44 us和1.26 us(72 M主频,如何测量的下篇笔记告诉你,记得关注哦)相差也不是很大,14%左右的差距,不过数据量大的情况下还是选择 & 吧,毕竟高效一些。 但是如果单纯从 & 和 % 运算角度来说,在STM32F103环境下能达到3倍的差距,这个自行测试就好了。 还有一个效率问题,那就是在单个队列元素插入与获取上。 因为V2.5是通用型的put、get函数,在单个元素的情况下效率必然不是很高,所以鱼鹰针对单个元素的插入与获取又封装了两个新函数,通过测试对比put函数,发现一个为1.60,一个0.67 us,差距还是挺大的(如果用在串口中断中,当然效率越高越好),所以需要根据场合使用合适的方式。
BUG 讨论
好了,现在来聊聊一个消费者一个生产者模式下可能产生的BUG以及该如何解决吧。 首先说说min。 如果min是一个函数,那么V2.5代码没有任何问题,但是如果它是一个宏呢?
#definemin(x,y)((x)< (y) ? (x) : (y))看着这个宏好像挺规范的,该有的括号都加上了,应该不会出现问题才是,真的如此吗? 鱼鹰在很多笔记中都曾说过,如果只是对一个共享资源进行读取操作的话是不会出现问题的,但这只是针对共享资源本身而言是如此,对于使用者来说,就不是这样了! 鱼鹰曾经在《入门 uCOS 操作系统的一点建议》中说过,当时的鱼鹰不明白一个判断语句为什么要在判断前关中断,虽然当时的理解是因为判断和修改应该顺序进行而不应该被打断,但是其实判断和再次读取在某种情况下也不可以被打断。 为什么会出现两次读取呢? 当你把 min 宏展开后,你就会发现 in 或者 out 被两次读取了。
len=len< in - out ? len : in - out假设get函数想读入3个字节数据,即len等于3,此时刚好队列中也有3个数据,即in – out 也等于3,3 < 3 ? 判断失败,跳转到最后那条语句执行,跳转时,另一个任务修改了in,增加了1,那么in – out 等于4,即最终 len 的值 为 4。 也就是说,本来你的程序应该只获取 3 个数据的,实际上却获取了4 个数据,如果说你的应用程序以最终的len值作为实际get的数据,那么无锁队列还是那个无锁队列,怕就怕你的应用程序会根据传入的len和返回len值做一些判断操作;还有一些可能就是应用程序就只获取3个数据,只能少,不能多,否则程序就会出现问题。 总之,因为两次读取中断导致无锁队列不再是你想的那个队列了。 那么该如果解决呢? 首先想到的就是把min这个宏改成函数,为了提高一点效率,也可以用inline进行声明。 另一种高效方法是,在进入get函数时,把in - out的结果保存在局部变量L中(这样可不必再申请一个变量,而且简化了两次读取与运算操作),用它再带入宏中使用,这样即使后面别的任务修改了in的值,也不会影响程序的运行,只不过没有非常及时提取最新数据而已。 从这里可以看出来,used变量因为副本(保存值到寄存器中)原因导致需要加互斥锁,而这里却不得不增加一个副本L来保证程序的正确运行,所以,副本的好与坏只能因情况而异,一定要谨慎分析。 现在再说说另一种可能的BUG。 对嵌入式了解比较多的道友应该清楚,多CPU和单CPU下可能出现代码乱序执行的情况,有可能是编译器修改了执行顺序,也有可能是硬件自动修改了执行顺序,那么上述的无锁队列就可能会出现问题(前面也说过顺序很重要)。 而真正的linux内核无锁队列实现其实是加入了内存屏障的(这个可以看参考代码),而因为STM32单片机比较简单,所以鱼鹰去掉了内存屏障代码。 但是还有一种情况,那就是数据缓存问题。我们知道,单片机(STM32存在指令与数据预取功能)为了运行效率,都采用流水线工作,而且为了提高效率,会预取多个数据或指令,如果说在切换任务时没有把整个流水线清除,那么也可能出现问题,不过这个问题暂时没有出现,以后再看吧。
测试
终于即将结束了,现在再简单唠嗑一下如何测试无锁队列或者链表问题。 我们知道队列出队入队都是有顺序的,如果我们在测试时,把有规律的数据放入队列中,那么获取数据时也根据这个规律来进行判断是否出现问题,那么就可以实现自动检测队列是否正常运行。 比如说,存入的数据一直自加,而接收时用一个变量记录上次接收的数据,然后和现在的数据进行比对是否相差1,那么就能简单判断无锁队列的功能。
而为了测试溢出之后in小于out的情况(in和out实在是太大了,要让他溢出太难等了),那么可以将in和out一开始设置为接近溢出值就行,比如 -7 等。 如果简单的两个线程间进行压力测试,那么你很难测出问题来,这是因为线程测试代码量太少,大部分时间CPU都是空闲状态,所以函数总是能顺序执行而不会被打断,如果想让代码可以被频繁打断以测试安全,那么将两个函数分别放到微秒级别的中断处理函数中或许能够测试出一些问题。 当然以上方法只是比较粗浅的测试,真正还是要在实际中进行长时间的稳定性测试才行,只有这样,你的程序才算是经受住了考验,否则纸上谈兵终觉浅啊!
-
代码
+关注
关注
30文章
4554浏览量
66717 -
BUG
+关注
关注
0文章
154浏览量
15579
原文标题:【深度长文】还是没忍住,聊聊神奇的无锁队列吧!
文章出处:【微信号:mcu168,微信公众号:硬件攻城狮】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

自举电路是怎样把电压一步步顶上去的?
OpenHarmony Meetup成都站招募令

请教大神,根据GIT上SDK配置指导,最后一步构建HELLO_WORD出现失败的原因
求助,索取有关在带有MPC5744P MCU的RD33771 EVB中启用锁步功能的文档
基于一步步蒸馏(Distilling step-by-step)机制
运行完MX_USB_HOST_Init后设备进入Infinite_Loop,请问怎么查原因?






 工商网监
工商网监
评论