 反爬虫:网络爬虫需要代理服务器的协助
反爬虫:网络爬虫需要代理服务器的协助
进入到大数据时代,我们很多时候都离不开数据使用,特别是对于网络而言,数据更是基础。
Python爬虫作为时下热门的信息采集工具,广受互联网工作者喜爱。由于其操作简单、语法简单、url请求和字符串处理都很方便快捷,计算机小白也可以通过简单的学习快速入门。现在很多与互联网有关的公司招聘信息上都有关于熟练使用python爬虫的相关要求,python成为互联网工作者必备的技能之一。
爬虫是现在最流行也是最好用的信息采集工具,一提到爬虫我们都绕不过代理IP这个话题。
因为网站会对爬虫有阻止,也就是反爬虫,要想爬虫不受到限制,那么爬虫过程中的ip切换是非常必要的,这里就需要代理服务器的协助了。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
IP
+关注
关注
5文章
1399浏览量
148262 -
网络爬虫
+关注
关注
1文章
50浏览量
8578 -
python
+关注
关注
51文章
4667浏览量
83443
发布评论请先 登录
相关推荐
Linux curl命令代理设置参数
代理服务器(Proxy Server)是工作在浏览器与http服务器之间的一个服务应用,所有经过代理服务器的http请求,都会被转发到对应的http
发表于 03-26 10:59
•97次阅读
服务器远程不上服务器怎么办?服务器无法远程的原因是什么?
运营商。
2.服务器网络问题
解决办法:通过路由图来确定是哪里的线路出现丢包,联系服务器商切换线路。
二、服务器问题
服务器带宽跑满、
发表于 02-27 16:21
全球新闻网封锁OpenAI和谷歌AI爬虫
分析结果显示,至2023年底,超半数(57%)的传统印刷媒体如《纽约时报》等已关闭OpenAI爬虫,反之电视广播以及数字原生媒体相应地分别为48%和31%。而对于谷歌人工智能爬虫,32%的印刷媒体采取相同措施,电视广播和数字原生媒体的比率分别为19%和17%。
linux服务器和windows服务器
,Linux服务器表现出更好的性能和稳定性,因此广泛应用于科学计算、大数据处理和网络服务器等领域。
另一方面,Windows服务器是由微软开发和维护的服务器操作系统,它提供了友好的用户
发表于 02-22 15:46
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
决Python爬虫中文乱码问题。 一、了解字符编码 在解决乱码问题之前,我们首先需要了解一些基本的字符编码知识。常见的字符编码有ASCII、UTF-8和GBK等。 1. ASCII:是一种用于表示英文字母、数字和常用符号的字符编码,它使用一个字节(8位)来表示一个字符。
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
数以万亿的网页通过链接构成了互联网,爬虫的工作就是从这数以万亿的网页中爬取需要的网页,从网页中采集内容并形成结构化的数据。
Python网络爬虫Selenium的简单使用
想要学习爬虫,如果比较详细的了解web开发的前端知识会更加容易上手,时间不够充裕,仅仅了解html的相关知识也是够用的。
如何看待Python爬虫的合法性?
Python爬虫是一种自动化程序,可以从互联网上获取信息并提取数据。通过模拟网页浏览器的行为,爬虫可以访问网页、抓取数据、解析内容,并将其保存到本地或用于进一步分析
物理机服务器需要多大的网络带宽?
物理机服务器需要多大的网络带宽?取决于多个因素,包括以下因素: 1、业务类型:不同类型的业务应用程序对网络带宽的需求各不相同。例如,网站托管、电子邮件
crawlerdetect:Python 三行代码检测爬虫
是否担心高频率爬虫导致网站瘫痪? 别担心,现在有一个Python写的神器——crawlerdetect,帮助你检测爬虫,保障网站的正常运转。 1.准备 开始之前,你要确保Python和pip已经成功
feapder:一款功能强大的爬虫框架
,基于 Redis,适用于海量数据,并且支持断点续爬、自动数据入库等功能 BatchSpider 分布式批次爬虫,主要用于需要周期性采集的爬虫 在实战之前,我们在虚
网络爬虫 Python和数据分析
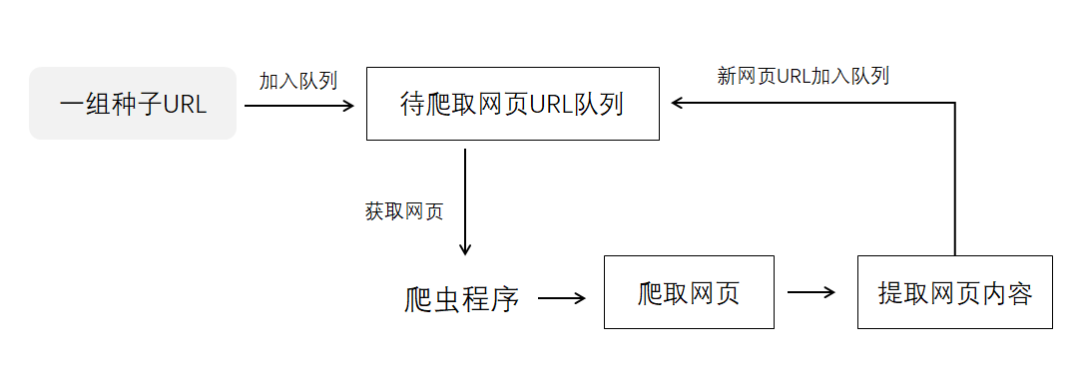
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的
发表于 09-25 08:25
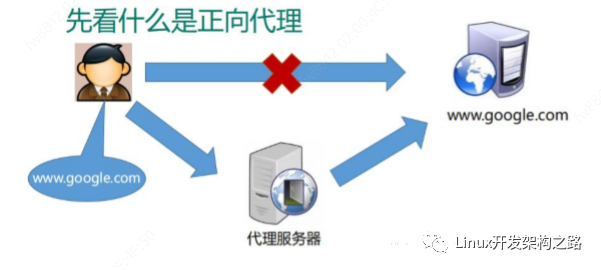
使用代理服务器的安全注意事项和风险
代理服务器充当用户和互联网之间的中介,转发请求并出于安全和隐私目的隐藏用户的IP地址。它接收用户请求,将其转发到Web服务器,并将响应发送回用户,同时保持匿名。 下面,小编给大家科普一下
用作代理的单元是否也可以是将信息中继到浏览器的网络服务器?
Raspberry pi 上),但是我可以将代理作为服务器访问,以将信息放在我的 android 手机的访问浏览器上。
换句话说,用作代理的单元是否也可以是将信息中继到浏览
发表于 06-05 07:42





 工商网监
工商网监
评论