 EdgeBoard中“活灵活现”的算子
EdgeBoard中“活灵活现”的算子
背景介绍
数据、算法和算力是人工智能技术的三大要素。其中,算力体现着人工智能(AI)技术具体实现的能力,实现载体主要有CPU、GPU、FPGA和ASIC四类器件。CPU基于冯诺依曼架构,虽然灵活,却延迟很大,在推理和训练过程中主要完成其擅长的控制和调度类任务。GPU以牺牲灵活性为代价来提高计算吞吐量,但其成本高、功耗大,尤其对于推理环节,并行度的优势并不能完全发挥。专用ASIC芯片开发周期长,资金投入大,由于其结构固化无法适应目前快速演进的AI算法。FPGA因其高性能、低功耗、低延迟、灵活可重配的特性,被广泛地用作AI加速,开发者无需更换芯片,即可实现优化最新的AI算法,为产品赢得宝贵的时间。
由此,百度基于FPGA打造了EdgeBoard嵌入式AI解决方案,能够提供强大的算力,支持定制化模型,适配各种不同的场景,并大幅提高设备端的AI推理能力,具有高性能、高通用、易集成等特点。本文将主要介绍EdgeBoard中神经网络算子在FPGA中的实现。
FPGA加速的关键因素
FPGA实现AI加速有两大关键因素,一是FPGA内部资源,二是内存访问带宽。FPGA内部资源主要包括LUT,FF,RAM以及DSP等,FPGA本质上是可编程逻辑电路,可用逻辑电路的多少取决于芯片内部资源,这也就决定了芯片的峰值算力和可容纳的算子种类数。
在深度学习中,90%以上的计算都集中在conv、dw-conv和pooling等少数的几个算子上。所以,并不是FPGA中添加的加速算子数量越多越好,而是要注重算子的加速质量:一是用更少的资源实现更多的功能;二是提高耗时占比大的算子性能。
在实践中,添加新算子前需要平衡该算子在网络中所耗时间的占比以及其在FPGA中所消耗的资源。当然可以通过选取更大规模的片子来突破这种限制,但是端上设备受限于成本、功耗等因素,只能平衡多种因素选择一个合适规模的芯片,然后通过多种设计方法和技巧来提高加速性能。本文接下来就将介绍在EdgeBoard中如何优化设计DSP资源提升算力,以及如何通过算子复用和融合技术实现对多算子的支持。
提升内存访问带宽是提高AI加速性能的另一关键因素,因为FPGA与内存的数据交互在整个计算过程中占比很高,有时甚至超过了计算本身所消耗的时间。直接提高内存访问带宽的方法包括提高DDR位宽、增加传输所用的高速接口资源、提高DMA传输的时钟频率等。另外也可以通过复用FPGA芯片上的内存资源(RAM)以及计算和传输交叠执行(overlap)等方法,减少与外部DDR存储的交互,降低数据传输的开销。这些设计方法较为常见,本文不做详细介绍。
两大关键技术实现四倍算力提升
FPGA中的计算主要依靠DSP实现,高效使用DSP是保证FPGA算力的关键。EdgeBoard FPGA中的DSP采用DSP48E2架构,如图1所示,包括一个27-bit的预加法器(pre-adder),一个27x18的乘法器(mult)和一个48-bit的ALU。
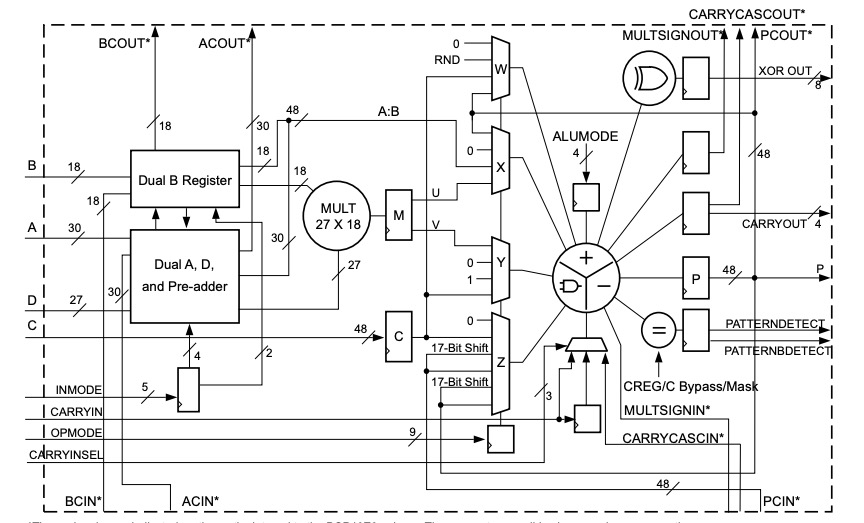
图1. DSP48E2结构图
在EdgeBoard的FPGA设计中,充分利用DSP48E2本身的特点,采用supertile和INT8移位计算技术,实现了四倍算力提升。
Supertile
一般来讲,Xilinx Ultrascale系列FPGA运行的最高频率在300MHz到400MHz之间,但DSP是FPGA中的硬核,可以运行在更高的频率上。如图2所示,SLB-M与DSP这样构成的基本单元,被称之为Supertile,FPGA内部Supertile的布局如图3所示。Supertile技术的核心在于使DSP运行于两倍逻辑频率上,使整个系统算力达到倍增的效果。这主要得益于芯片结构中SLICEM与DSP位置临近,使用专有的布线资源,延迟缩短,可以支撑SLICEM以双倍逻辑运行的频率向DSP提供数据。另外,神经网络中存在着数据复用,通过filter和image数据的复用和交织,一次取数多次使用,从而减少数据的搬运次数,提升计算效率。
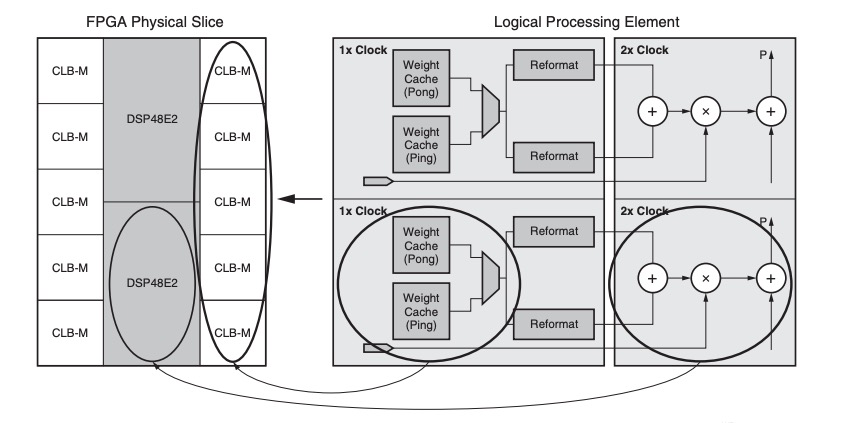
图2. Supertile结构
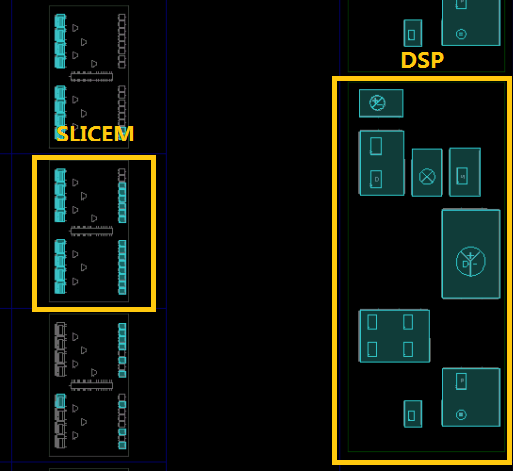
图3. DSP和SLICEM在FPGA中的位置
INT8移位计算技术
利用DSP48E2的结构特点,一个DSP完成两路INT8的乘加。在进行8bit数据计算时,将a左移18位,置于输入的高8位,低19位补0,从DSP的A端输入,b维持在低8位,从DSP的D端输入,如图4所示。a与b两者先进行累加,然后与c相乘后,结果将分别位于输出的高(a*c)、低(b*c)两部分,该计算过程如图5所示。
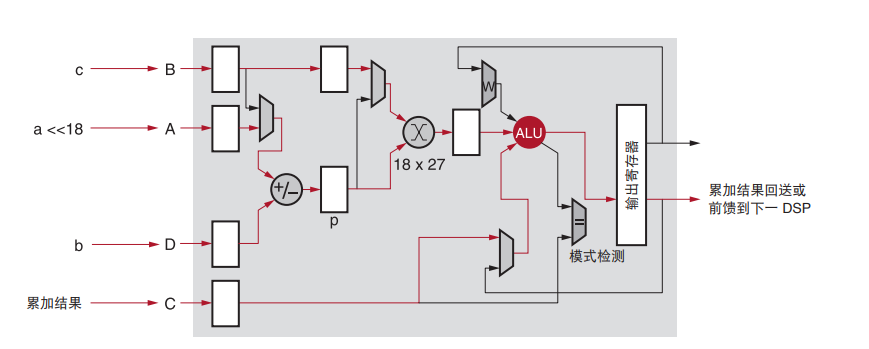
图4. DSP移位示意图
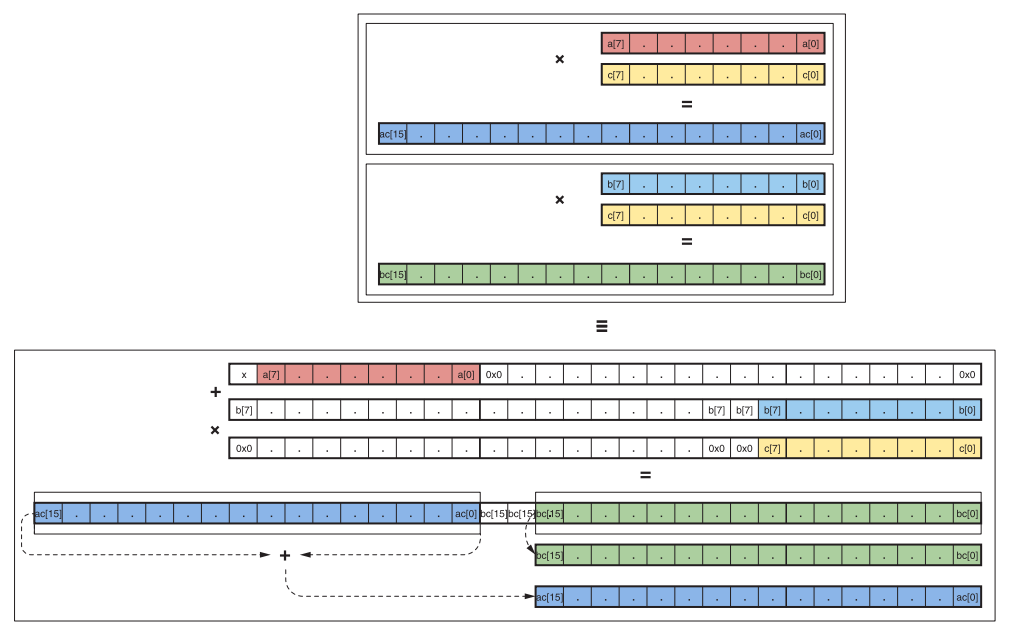
图5. 单DSP实现两路INT8相乘
在实践中,我们把a,b两路作为filter数据输入,c作为image数据输入。这样DSP在一个时钟周期内就同时完成了两路的计算,再次使算力翻倍。结合前面提到的supertile倍频设计,两种设计使得单个DSP的算力提升四倍。因为一次计算过程有乘、加两个操作(operations),所以单个DSP在一个时钟周期高效的完成了8个operations。
多算子复用
深度学习中主要有两类运算,一类是指数运算,另一类是乘加运算。前者主要位于激活函数层,后者是深度学习涉及最多也是最基础的运算。乘加运算根据kernel的维度不同,又可分为向量型和矩阵型,在EdgeBoard中划分为三个运算单元,分别为向量运算单元(VPU: vector processing unit)、矩阵运算单元(MPU: matrix processing unit)和指数激活运算单元(EXP-ACT: exponential activation unit)。
向量运算单元
向量运算单元VPU负责实现dw-conv(depth-wise convolution),完成3维输入图像(H x W x C)和3维卷积核(K1 x K2 x C)的乘加操作。其中一个卷积核负责输入图像的一个通道,卷积核的数量与上一层的通道数相同,该过程如图6所示。图7表示的是一个通道内以kernel 2x2和stride 2为例的计算过程。
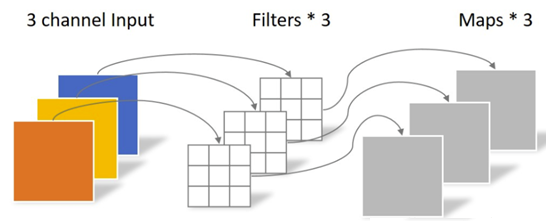
图6. dw-conv示意图
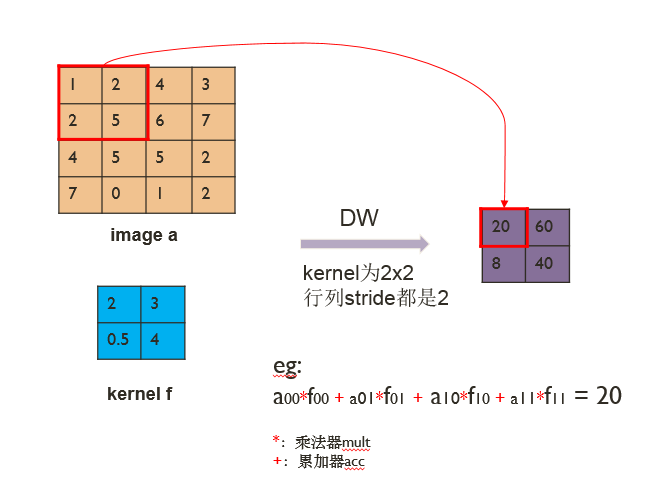
图7. dw-conv的计算
EdgeBoard通过复用VPU一套计算资源实现了average/max pooling,elementwise add/sub,scale,batch-normalize,elementwise-mul和dropout等多种算子。
Average pooling可以看作是卷积核参数固定的dw-conv,即将求和后取平均(除以卷积核面积)的操作转换成先乘以一个系数(1/卷积核面积)再求和。如图8所示,该例子中卷积核大小为2x2,卷积核参数即为1/4。卷积核固定的参数可以类似于dw-conv下发卷积核的方式由SDK封装后下发,也可以通过SDK配置一个参数完成,然后在FPGA中计算转换,这样节省卷积核参数传输的时间。另外,max-pooling算子与average pooling的计算过程类似,只需要将求均值操作换成求最大值的操作,其余挖窗、存取数等过程保持不变。
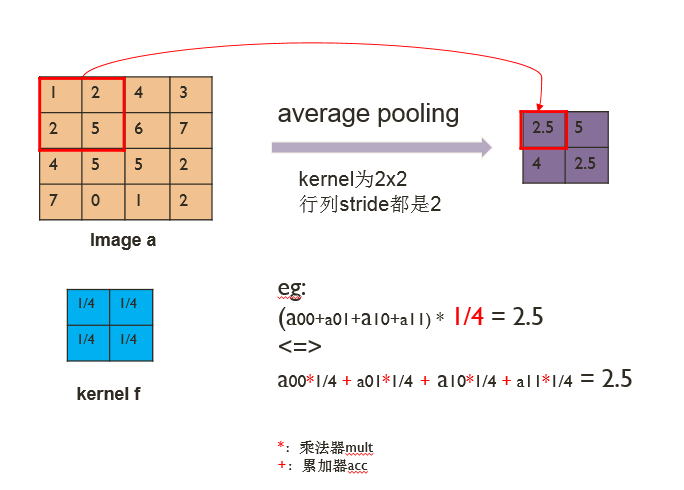
图8. Pooling复用dw-conv
Elementwise add/sub完成两幅图像对应元素的相加或相减,不同于dw-conv的是它有两幅输入图像。如果我们控制两幅图像的输入顺序,将两幅图像按行交错拼成一幅图像,然后取卷积核为2x1,行stride为1,列stride为2,pad均设置成0,则按照dw-conv的计算方式就完成了elementwise的计算。通过在FPGA中设置当前像素对应的kernel值为1或-1,就可以分别实现对应elementwise add和elementwise sub两个算子。该过程如图9所示。
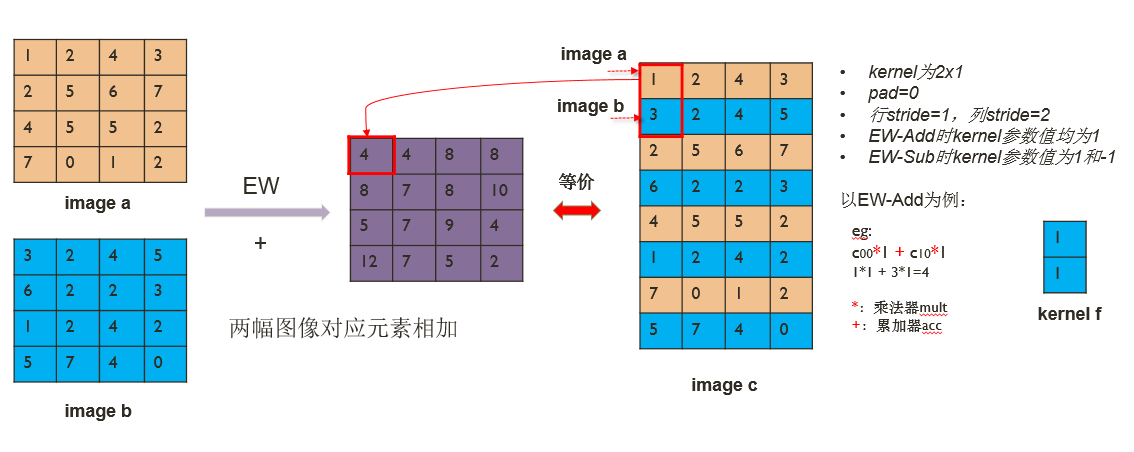
图9. ew-add/sub复用dw-conv
Scale算子主要在图像预处理时使用,将输入图像每一个通道的全部像素点乘以该通道对应的scale值,然后加上bias。如果我们将dw-conv的卷积核大小设成1x1,行列stride都设置成1,pad设置成0,卷积核参数值设成scale,就可以通过dw-conv完成scale算子的功能。通过分析发现,batch-normalize,elementwise-mul和dropout等算子都可以通过scale算子来实现。
二. 矩阵运算单元
矩阵运算单元MPU负责实现convolution,完成3维输入图像(H x W x C)和4维卷积核(N x K1 x K2 x C)的乘加操作,单个卷积核的通道数和输入图像的通道数相同,而卷积核的数量N决定了输出的通道数,如图10所示。full connection 算子实现的1维输入数组(长度C)和2维权重(N x C)的乘加操作。将 full connection输入数组扩展成 H x W x C, 输出扩展成 N x K1 x K2 x C, 其中H, W, K1和K2均设置成1,这样 full connection就可以调用convolution来实现。另外,在计算 deconv 时,通过SDK对卷积核进行分拆、重排,就可以通过调用conv来实现deconv,同样带来了极大的收益。
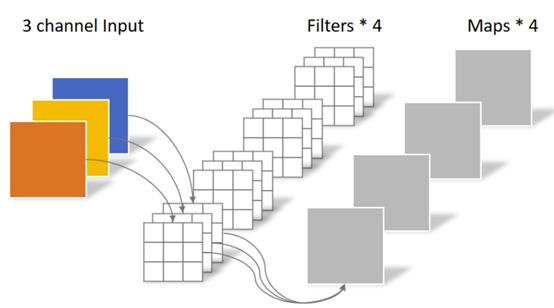
图10. Conv算子示意图
三.指数激活运算单元
指数激活运算单元EXP-ACT实现的基础是sigmoid,由于在FPGA中进行指数型运算比较耗资源,如何复用该计算单元就变得非常有意义。通过分析发现,可以把 tanh 和两通道softmax 转换成 sigmoid 的形式,这样一个指数运算单元就支持了3种算子,实现资源利用的最大化。
多算子融合
在推理时做BatchNorm运算非常耗时,通过SDK将BatchNorm+Scale的线性变换参数融合到卷积层,替换原来的weights和bias,这样4个算子可以融合成单个算子conv + batchnorm + scale + relu,对于dw-conv同样如此。相对于每计算完一个算子就将数据送回内存,这种算子融合大大减少了内存的读写操作,有效提高了处理帧率。
此外,我们将scale、bias和relu为代表的激活函数层放到各算子之后的链路上,然后统一送到DMA传输模块,如图11所示。这不仅使得各算子复用了这些逻辑,节省了大量片内资源,也使得各算子都可以具备这些功能,且都能以最大带宽进行DMA传输。在实践中,我们将这些功能做成可选项,由软件根据当前网络算子的需要进行选择,在节省资源的同时,既保证了通用性,又兼顾了灵活性。
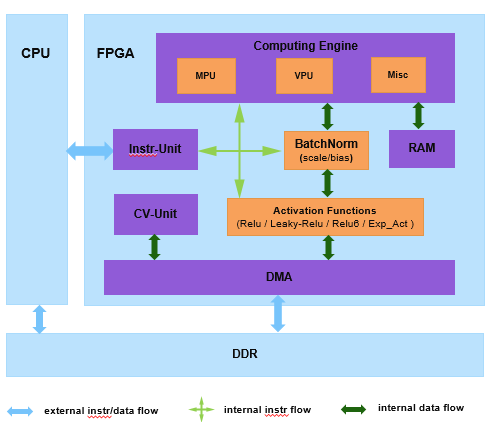
图11. EdgeBoard内部结构和链路图
福利
据可靠小道消息:EdgeBoard正在打折中,历史最低价,降价1000元,有兴趣可以看看:https://aim.baidu.com/product/5b8d8817-9141-4cfc-ae58-640e2815dfd4
-
LabVIEW
+关注
关注
1914文章
3615浏览量
316900
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论