 如何利用Tensorflow编写一个基本的端到端自动语音识别
如何利用Tensorflow编写一个基本的端到端自动语音识别
本文阐述了如何利用Tensorflow编写一个基本的端到端自动语音识别(Automatic Speech Recognition,ASR)系统,详细介绍了最小神经网络的各个组成部分以及可将音频转为可读文本的前缀束搜索解码器。
虽然当下关于如何搭建基础机器学习系统的文献或资料有很多,但是大部分都是围绕计算机视觉和自然语言处理展开的,极少有文章就语音识别展开介绍。本文旨在填补这一空缺,帮助初学者降低入门难度,提高学习自信。
前提
初学者需要熟练掌握:
· 神经网络的组成
· 如何训练神经网络
· 如何利用语言模型求得词序的概率
概述
· 音频预处理:将原始音频转换为可用作神经网络输入的数据
· 神经网络:搭建一个简单的神经网络,用于将音频特征转换为文本中可能出现的字符的概率分布
· CTC损失:计算不使用相应字符标注音频时间步长的损失
· 解码:利用前缀束搜索和语言模型,根据各个时间步长的概率分布生成文本
本文重点讲解了神经网络、CTC损失和解码。
音频预处理
搭建语音识别系统,首先需要将音频转换为特征矩阵,并输入到神经网络中。完成这一步的简单方法就是创建频谱图。
def create_spectrogram(signals):
stfts = tf.signal.stft(signals, fft_length=256)
spectrograms = tf.math.pow(tf.abs(stfts), 0.5)
return spectrograms
这一方法会计算出音频信号的短时傅里叶变换(Short-time Fourier Transform)以及功率谱,其最终输出可直接用作神经网络输入的频谱图矩阵。其他方法包括滤波器组和MFCC(Mel频率倒谱系数)等。
了解更多音频预处理知识:https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
神经网络
下图展现了一个简单的神经网络结构。
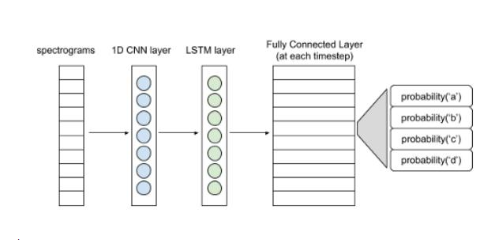
语音识别基本结构
频谱图输入可以看作是每个时间步长的向量。1D卷积层从各个向量中提取出特征,形成特征向量序列,并输入LSTM层进一步处理。LSTM层(或双LSTM层)的输入则传递至全连接层。利用softmax激活函数,可得出每个时间步长的字符概率分布。整个网络将会用CTC损失函数进行训练(CTC即Connectionist Temporal Classification,是一种时序分类算法)。熟悉整个建模流程后可尝试使用更复杂的模型。
class ASR(tf.keras.Model):
def __init__(self, filters, kernel_size, conv_stride, conv_border, n_lstm_units, n_dense_units):
super(ASR, self).__init__()
self.conv_layer = tf.keras.layers.Conv1D(filters,
kernel_size,
strides=conv_stride,
padding=conv_border,
activation=‘relu’)
self.lstm_layer = tf.keras.layers.LSTM(n_lstm_units,
return_sequences=True,
activation=‘tanh’)
self.lstm_layer_back = tf.keras.layers.LSTM(n_lstm_units,
return_sequences=True,
go_backwards=True,
activation=‘tanh’)
self.blstm_layer = tf.keras.layers.Bidirectional(self.lstm_layer, backward_layer=self.lstm_layer_back)
self.dense_layer = tf.keras.layers.Dense(n_dense_units)
def call(self, x):
x = self.conv_layer(x)
x = self.blstm_layer(x)
x = self.dense_layer(x)
return x
为什么使用CTC呢?搭建神经网络旨在预测每个时间步长的字符。然而现有的标签并不是各个时间步长的字符,仅仅是音频的转换文本。而文本的各个字符可能横跨多个步长。如果对音频的各个时间步长进行标记,C-A-T就会变成C-C-C-A-A-T-T。而每隔一段时间,如10毫秒,对音频数据集进行标注,并不是一个切实可行的方法。CTC则解决上了上述问题。CTC并不需要标记每个时间步长。它忽略了文本中每个字符的位置和实际相位差,把神经网络的整个概率矩阵输入和相应的文本作为输入。
CTC 损失计算
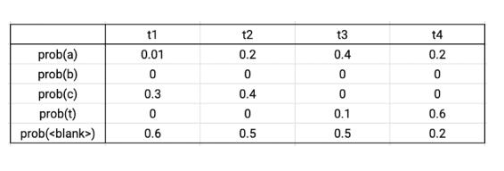
输出矩阵示例
假设真实的数据标签为CAT,在四个时间步长中,有序列C-C-A-T,C-A-A-T,C-A-T-T,_-C-A-T,C-A-T-_与真实数据相对应。将这些序列的概率相加,可得到真实数据的概率。根据输出的概率矩阵,将序列的各个字符的概率相乘,可得到单个序列的概率。则上述序列的总概率为0.0288+0.0144+0.0036+0.0576+0.0012=0.1056。CTC损失则为该概率的负对数。Tensorflow自带损失函数文件。
解码
由上文的神经网络,可输出一个CTC矩阵。这一矩阵给出了各个时间步长中每个字符在其字符集中的概率。利用前缀束搜索,可从CTC矩阵中得出所需的文本。
除了字母和空格符,CTC矩阵的字符集还包括两种特别的标记(token,也称为令牌)——空白标记和字符串结束标记。
空白标记的作用:CTC矩阵中的时间步长通常比较小,如10毫秒。因此,句子中的一个字符会横跨多个时间步长。如,C-A-T会变成C-C-C-A-A-T-T。所以,需要将CTC矩阵中出现该问题的字符串中的重复部分折叠,消除重复。那么像FUNNY这种本来就有两个重复字符(N)的词要怎么办呢?在这种情况下,就可以使用空白标记,将其插入两个N中间,就可以防止N被折叠。而这么做实际上并没有在文本中添加任何东西,也就不会影响其内容或形式。因此,F-F-U-N-[空白]-N-N-Y最终会变成FUNNY。
结束标记的作用:字符串的结束表示着一句话的结束。对字符串结束标记后的时间步长进行解码不会给候选字符串增加任何内容。
步骤
初始化
· 准备一个初始列表。列表包括多个候选字符串,一个空白字符串,以及各个字符串在不同时间步长以空白标记结束的概率,和以非空白标记结束的概率。在时刻0,空白字符串以空白标记结束的概率为1,以非空白标记结束的概率则为0。
迭代
· 选择一个候选字符串,将字符一个一个添加进去。计算拓展后的字符串在时刻1以空白标记和非空白标记结束的概率。将拓展字符串及其概率记录到列表中。将拓展字符串作为新的候选字符串,在下一时刻重复上述步骤。
· 情况A:如果添加的字符是空白标记,则保持候选字符串不变。
· 情况B:如果添加的字符是空格符,则根据语言模型将概率与和候选字符串的概率成比例的数字相乘。这一步可以防止错误拼写变成最佳候选字符串。如,避免COOL被拼成KUL输出。
· 情况C:如果添加的字符和候选字符串的最后一个字符相同,(以候选字符串FUN和字符N为例),则生成两个新的候选字符串,FUNN和FUN。生成FUN的概率取决于FUN以空白标记结束的概率。生成FUNN的概率则取决于FUN以非空白标记结束的概率。因此,如果FUN以非空白标记结束,则去除额外的字符N。
输出
经过所有时间步长迭代得出的最佳候选字符串就是输出。
为了加快这一过程,可作出如下两个修改。
1.在每一个时间步长,去除其他字符串,仅留下最佳的K个候选字符串。具体操作为:根据字符串以空白和非空白标记结束的概率之和,对候选字符串进行分类。
2.去除矩阵中概率之和低于某个阈值(如0.001)的字符。
具体操作细节可参考如下代码。
def prefix_beam_search(ctc,
alphabet,
blank_token,
end_token,
space_token,
lm,
k=25,
alpha=0.30,
beta=5,
prune=0.001):
‘’‘
function to perform prefix beam search on output ctc matrix and return the best string
:param ctc: output matrix
:param alphabet: list of strings in the order their probabilties are present in ctc output
:param blank_token: string representing blank token
:param end_token: string representing end token
:param space_token: string representing space token
:param lm: function to calculate language model probability of given string
:param k: threshold for selecting the k best prefixes at each timestep
:param alpha: language model weight (b/w 0 and 1)
:param beta: language model compensation (should be proportional to alpha)
:param prune: threshold on the output matrix probability of a character.
If the probability of a character is less than this threshold, we do not extend the prefix with it
:return: best string
’‘’
zero_pad = np.zeros((ctc.shape[0]+1,ctc.shape[1]))
zero_pad[1:,:] = ctc
ctc = zero_pad
total_timesteps = ctc.shape[0]
# #### Initialization ####
null_token = ‘’
Pb, Pnb = Cache(), Cache()
Pb.add(0,null_token,1)
Pnb.add(0,null_token,0)
prefix_list = [null_token]
# #### Iterations ####
for timestep in range(1, total_timesteps):
pruned_alphabet = [alphabet[i] for i in np.where(ctc[timestep] 》 prune)[0]]
for prefix in prefix_list:
if len(prefix) 》 0 and prefix[-1] == end_token:
Pb.add(timestep,prefix,Pb.get(timestep - 1,prefix))
Pnb.add(timestep,prefix,Pnb.get(timestep - 1,prefix))
continue
for character in pruned_alphabet:
character_index = alphabet.index(character)
# #### Iterations : Case A ####
if character == blank_token:
value = Pb.get(timestep,prefix) + ctc[timestep][character_index] * (Pb.get(timestep - 1,prefix) + Pnb.get(timestep - 1,prefix))
Pb.add(timestep,prefix,value)
else:
prefix_extended = prefix + character
# #### Iterations : Case C ####
if len(prefix) 》 0 and character == prefix[-1]:
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * Pb.get(timestep-1,prefix)
Pnb.add(timestep,prefix_extended,value)
value = Pnb.get(timestep,prefix) + ctc[timestep][character_index] * Pnb.get(timestep-1,prefix)
Pnb.add(timestep,prefix,value)
# #### Iterations : Case B ####
elif len(prefix.replace(space_token, ‘’)) 》 0 and character in (space_token, end_token):
lm_prob = lm(prefix_extended.strip(space_token + end_token)) ** alpha
value = Pnb.get(timestep,prefix_extended) + lm_prob * ctc[timestep][character_index] * (Pb.get(timestep-1,prefix) + Pnb.get(timestep-1,prefix))
Pnb.add(timestep,prefix_extended,value)
else:
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * (Pb.get(timestep-1,prefix) + Pnb.get(timestep-1,prefix))
Pnb.add(timestep,prefix_extended,value)
if prefix_extended not in prefix_list:
value = Pb.get(timestep,prefix_extended) + ctc[timestep][-1] * (Pb.get(timestep-1,prefix_extended) + Pnb.get(timestep-1,prefix_extended))
Pb.add(timestep,prefix_extended,value)
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * Pnb.get(timestep-1,prefix_extended)
Pnb.add(timestep,prefix_extended,value)
prefix_list = get_k_most_probable_prefixes(Pb,Pnb,timestep,k,beta)
# #### Output ####
return prefix_list[0].strip(end_token)
这样,一个基础的语音识别系统就完成了。对上述步骤进行复杂化,可以得到更优的结果,如,搭建更大的神经网络和利用音频预处理技巧。
完整代码:https://github.com/apoorvnandan/speech-recognition-primer
注意事项:
1. 文中代码使用的是TensorFlow2.0系统,举例使用的音频文件选自LibriSpeech数据库(http://www.openslr.org/12)。
2. 文中代码并不包括训练音频数据集的批量处理生成器。读者需要自己编写。
3. 读者亦需自己编写解码部分的语言模型函数。最简单的方法就是基于语料库生成一部二元语法字典并计算字符概率。
-
语音识别
+关注
关注
37文章
1635浏览量
111828 -
机器学习
+关注
关注
66文章
8112浏览量
130545 -
tensorflow
+关注
关注
13文章
313浏览量
60242
发布评论请先 登录
相关推荐
基于TensorFlow和Keras的图像识别

语音识别技术在教育领域的应用与挑战

iTOP-RK3588开发板使用 tensorflow框架
语音识别技术的进步与挑战
【KV260视觉入门套件试用体验】部署DPU镜像并开发一个图像识别程序







 工商网监
工商网监
评论