一种在分布式环境下实现幂迭代聚类的方法
大小:0.69 MB 人气: 2017-12-11 需要积分:1
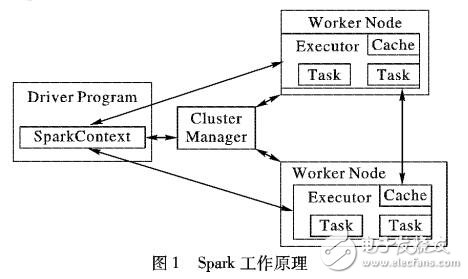
为解决幂迭代聚类算法并行实现中存在的编程繁琐、效率低下等问题,基于Spark大规模数据通用计算引擎及其GraphX组件,提出了一种在分布式环境下实现幂迭代聚类的方法。首先,利用某种相似性度量方法,将原始数据转换成一个可以视为图的亲和矩阵;然后,通过顶点切割,把行归一化后的亲和矩阵切分成若干个小图,分别存储在不同的机器上;最后,利用Spark基于内存计算的特点,对存储在集群中的图进行多次迭代计算,得到这个图的一个切割,图的每一个划分子图对应一个类簇。在不同规模的数据集和不同executor个数下进行的实验结果表明,基于GraphX的分布式幂迭代聚类算法具有良好的可扩展性,算法运行时间与executor个数呈负相关的线性关系,在6个executor下,与单个executor相比,算法的加速比达到了2.09到3.77。同时,通过与基于Hadoop的幂迭代聚类进行对比,在新闻数量为40000篇时,运行时间降低了6l%。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
一种在分布式环境下实现幂迭代聚类的方法下载
相关电子资料下载
- 技术迭代、商业落地加速,700亿医疗级可穿戴设备市场或将到来 16
- 亚马逊云科技生成式AI最新案例分析,助力企业业务创新迭代 57
- 思尔芯原型验证助力香山RISC-V处理器迭代加速 108
- 讯维分布式kvm坐席管理系统推动教育行业的创新与发展 188
- 什么是分布式锁 Redis的五种分布式锁方案 32
- 基于PyTorch的模型并行分布式训练Megatron解析 70
- 隆基与德国重要合作伙伴PVI签署1.5GW Hi-MO X6框架协议 208
- Tqdm:超方便的迭代进度条 55
- 曙光推出ParaStor分布式存储系统解决方案 312
- 智能手表“进化”:软硬件迭代加速,产品形态、交互方式升级 657