打破深度学习偏见,这事跟数据量有啥关系?
大小:0.4 MB 人气: 2017-12-06 需要积分:1
近日,在深度学习领域出现了一场热烈的争论。这一切都要从 Jeff Leek 在 Simply Stats 上发表了一篇题为《数据量不够大,别玩深度学习》(Don’t use deep learning your data isn’t that big)的博文开始。作者 Jeff Leek 在这篇博文中指出,当样本数据集很小时(这种情况在生物信息领域很常见),即使有一些层和隐藏单元,具有较少参数的线性模型的表现是优于深度网络的。为了证明自己的论点,Leek 举了一个基于 MNIST 数据库进行图像识别的例子,分辨 0 或者 1。他还表示,当在一个使用仅仅 80 个样本的 MNIST 数据集中进行 0 和 1 的分类时,一个简单的线性预测器(逻辑回归)要比深度神经网络的预测准确度更高。
这篇博文的发表引起了领域内的争论,哈佛大学药学院的生物医药信息学专业博士后 Andrew Beam 写了篇文章来反驳:《就算数据不够大,也能玩深度学习》(You can probably use deep learning even if your data isn’t that big)。Andrew Beam 指出,即使数据集很小,一个适当训练的深度网络也能击败简单的线性模型。
如今,越来越多的生物信息学研究人员正在使用深度学习来解决各种各样的问题,这样的争论愈演愈烈。这种炒作是真的吗?还是说线性模型就足够满足我们的所有需求呢?结论一如既往——要视情况而定。在这篇文章中,作者探索了一些机器学习的使用实例,在这些实例中使用深度学习并不明智。并且解释了一些对深度学习的误解,作者认为正是这些错误的认识导致深度学习没有得到有效地使用,这种情况对于新手来说尤其容易出现。
打破深度学习偏见
首先,我们来看看许多外行者容易产生的偏见,其实是一些半真半假的片面认识。主要有两点,其中的一点更具技术性,我将详细解释。
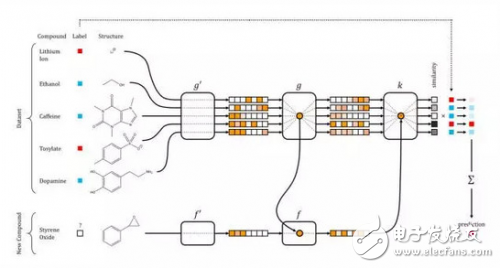
深度学习在小样本集上也可以取得很好的效果
深度学习是在大数据的背景下火起来的(第一个谷歌大脑项目向深度神经网络提供了大量的 Youtube 视频),自从那以后,绝大部分的深度学习内容都是基于大数据量中的复杂算法。
然而,这种大数据 + 深度学习的配对不知为何被人误解为:深度学习不能应用于小样本。如果只有几个样例,将其输入具有高参数样本比例的神经网络似乎一定会走上过拟合的道路。然而,仅仅考虑给定问题的样本容量和维度,无论有监督还是无监督,几乎都是在真空中对数据进行建模,没有任何的上下文。
可能的数据情况是:你拥有与问题相关的数据源,或者该领域的专家可以提供的强大的先验知识,或者数据可以以非常特殊的方式进行构建(例如,以图形或图像编码的形式)。所有的这些情况中,深度学习有机会成为一种可供选择的方法——例如,你可以编码较大的相关数据集的有效表示,并将该表示应用到你的问题中。
这种典型的示例常见于自然语言处理,你可以学习大型语料库中的词语嵌入,例如维基百科,然后将他们作为一个较小的、较窄的语料库嵌入到一个有监督任务中。极端情况下,你可以用一套神经网络进行联合学习特征表示,这是在小样本集中重用该表示的一种有效方式。这种方法被称作 “一次性学习”(one-shot learning) ,并且已经成功应用到包括计算机视觉和药物研发在内的具有高维数据的领域。
非常好我支持^.^
(1) 100%
不好我反对
(0) 0%