基于数据的自然语言对话技术大发展
大小:0.1 MB 人气: 2017-10-13 需要积分:1
我们在日常生活中经常使用自然语言对话系统,比如苹果Siri。现在的对话系统多数只能做单轮对话,可以帮助用户完成一些简单的任务,如问天气,查股票(如果做多轮对话,也是在单轮对话的基础上加一些简单处理)。实现这些自然语言对话系统的基本技术可以分为两大类,基于规则的和基于数据的。你也许想知道对话系统的基本原理是怎样的?特别是如何用数据驱动的方式构建一个对话系统?
最近基于数据的自然语言对话技术取得了突破性的进展。我们发现,利用深度学习和大数据,可以很容易地构建一个单轮对话系统,自动生成对话,并且取得惊人的好效果。比如,用5百万微博数据可以构建一个系统,用户给出一句话,这个系统可以自动生成一句回答。用户输入“我想买一部三星手机”,系统回答“还是支持一下国产的吧”,等等。你也许想知道这是如何实现的?能达到什么样的水平?
本文试图系统地回答以上问题。首先指出,自然语言对话将是人们信息访问的主要手段,信息检索领域的主要研究范式。之后,定义自然语言对话任务,对相关技术进行分类,列举主要技术挑战。接着,详细介绍如何构建基于数据的对话系统。最后,详细介绍最新的基于深度学习的对话技术。当中也介绍深度学习在自然语言表示学习中的最新成果。
信息检索领域的范式转移
“科学的发展依赖于间断性、革命性的变化”,这是科学哲学与科学史学家托马斯·库恩(Thomas Kuhn)的名言。库恩认为科学的每个领域都有不同的“范式” (paradigm),它们有着不同的研究对象、基本概念、解决问题的手段,甚至不同的研究者群体,比如,在物理学领域,量子力学与牛顿力学就属于不同的范式。科学的发展不是连续的,而是间断的,量子力学并不是在牛顿力学基础上发展起来的。当一个领域发生革命性的变化的时候,一定有新的范式产生,库恩称之为范式转移(paradigm shift)[1]。
信息检索是计算机科学的一个分支,研究和开发计算机帮助用户管理、访问、使用信息的技术。纵观信息检索几十年来的发展历程,可以看到它已经历了两个主要范式:图书馆搜索和互联网搜索。七十年代研究的重点是如何帮助用户在图书馆快速地查找文献资料,有不少该领域基本技术被开发出来,比如向量空间模型。九十年代研究的重点是如何帮助用户在互联网上迅速地访问想访问的网页,有许多创新,链接分析、排序学习、语义匹配、日志分析等技术被开发出来。
2011年苹果公司发布了语音助手系统Siri,标志着一个新的时代的开启。自然语言对话成了人们访问信息的一个新的手段。现在,移动设备成为个人计算的主流,越来越多的用户通过移动设备访问信息。在移动设备上,自然语言对话是人机交互最自然的,最有效的方式。另一方面,自然语言对话的技术,虽然达到了一定可用的水平,但还不成熟,不能很好理解用户的意图,不能充分满足用户的需求。这就意味着,围绕自然语言对话有很多待解决的具有挑战性的问题,它自然成为信息检索领域研究的一个新的重点,一个新的范式。
自然语言对话
自然语言对话可以形式化为以下问题。有一个计算机系统(对话系统),一个用户。用户通过自然语言,如中文、英文,与对话系统进行多轮交谈,系统帮助用户完成一个任务,特别是访问信息的任务。
自然语言对话,即计算机和人通过人类的语言进行交互,是实现人工智能的标志,其研究与开发有着很长的历史。迄今为止,有许多自然语言对话系统被开发出来,在受限的条件下,可以与用户进行一定的对话,帮助用户完成简单的任务。
现在的对话系统大多只做单轮对话,如果做多轮对话,也是在单轮对话的基础上做一些简单的处理。技术主要包括基于手写规则的,和基于数据驱动的。比如,六十年代就有著名的Eliza系统问世,基于手写规则,能与用户进行简单的对话,使许多用户感觉到好像是在跟真人进行交流。Siri之后,有许多对话产品出现,包括谷歌Now,微软Cortana。国内有许多聊天机器人发布,如微软Xiaobing,受到广泛瞩目。据我们所知,大部分的对话系统都是基于规则,或者基于数据的。
自然语言对话的研究与开发,虽然取得了一定的进展,但离实现人工智能的理想,甚至离实现在复杂场景下的实用化还有很大距离。自然语言对话有许多应用场景。比如,如果用户能够通过对话在智能手机上完成订酒店之类的复杂任务,那么手机就会真正成为用户的得力助手。这里的核心问题是如何“理解”用户的语言,帮助用户完成任务。现在的语音助手还不能做到这一点。再比如,许多公司有呼叫中心,在电话上回答用户提出的各种问题。如果能够实现自动呼叫中心,机器来回答用户的问题,就能大大提高服务的效率和质量。这里的核心问题也是自然语言对话。
必须指出,重要的是需要将自然语言对话作为科学问题研究,而不能停留在工程的技巧上。作为科学问题研究,应该有几个特点:首先是建立数学模型解决问题,其次是实验结果能够再现,还有复杂的问题被还原成简单的问题解决。
基于数据的对话系统
大数据时代为自然语言对话研究提供了一个新的机会,大量的对话数据可以从实际的场景获得。一个重要的研究问题是,我们是否可以利用大数据,构建一个数据驱动的自然语言对话系统。比如,记录呼叫中心话务员与客户的对话,用这些数据,是否可以构建一个自动的呼叫中心。
计算机理解人的语言还是非常困难的,即使是不可能的。一个克服这个挑战的方法就是用数据驱动的方式构建对话系统。搜索技术的成功给我们的一个启示,尽量避开自然语言理解,用数据驱动的方式解决问题,是人工智能技术实用化的一个有效途径。我们可以把对话系统的主要部分用数据驱动的方式构建,另一方面,只实现轻量级的知识使用、推理、对话管理。
我们可以把自然语言对话分成单轮对话和多轮对话进行研究。单轮对话是基础,也应该是研究的第一个重点。单轮对话可以是基于规则的,或基于数据的。基于数据的方法又可以分成基于检索的方式和基于生成的方式。下面作一简单介绍。
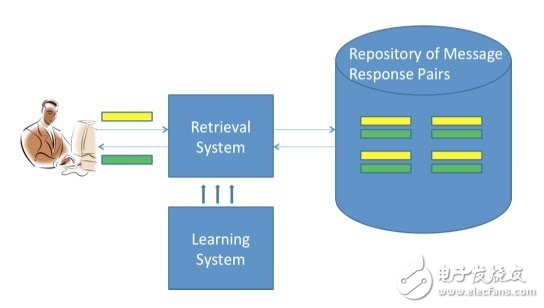
图1 基于检索的对话系统
图1是基于检索的单轮对话系统。大量的单轮对话数据存储在索引里,每一个实例包括一个信息和一个回复。用户输入一个信息,检索模块从索引中检索相对相关的信息和回复,并将最适合的回复返给用户,形成一轮对话。而检索系统本身是通过机器学习构建的。
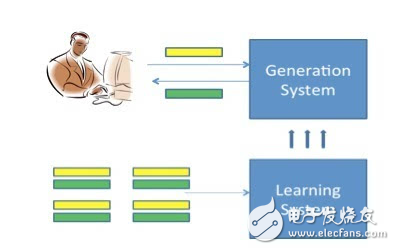
图2 基于生成的对话系统
图2是基于生成的单轮对话系统。学习模块利用大量对话数据构建生成模块。当用户给定一个信息时,生成模块针对该信息自动生成一个回复。
深度学习与语义表示学习
最近深度学习技术有了突飞猛进的发展,为语音识别、图像识别、自然语言处理(包括自然语言对话),提供了强大的工具,为这些领域今后的快速发展提供了新的契机。事实上,若干个基于深度学习的对话系统已被开发出来,受到了广泛瞩目。
深度学习为自然语言处理带来的本质突破是语句的语义表示学习,也是基于深度学习的对话技术的基础,这里做一简要介绍。
在自然语言处理领域,一个普遍使用的技术是用实数值向量来表示单词的语义,其基本假设是单词的语义可以由与其共现的其他单词来决定。比如,统计每一个单词与其它单词在一个数据集的共现频率,并将其表示为向量,这些向量能够很好地表示单词的语义相似性,两个单词向量的余弦相似度越大,两个单词的语义就越相近。
最近自然语言处理与深度学习的一个新发现是,我们可以通过深度学习用实数值向量来表示语句的语义。如图3所示,两句话“John loves Mary”和“Mary is loved by John”的语义向量就相近,而这两句话的语义向量就与“Mary loves John”的语义向量相远。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%