深度学习与自然语言处理的工作概述及未来发展
大小:0.4 MB 人气: 2017-10-13 需要积分:1
标签:深度学习(119547)
深度学习是机器学习的一个领域,研究复杂的人工神经网络的算法、理论、及应用。自从2006年被Hinton等提出以来[1],深度学习得到了巨大发展,已被成功地应用到图像处理、语音处理、自然语言处理等多个领域,取得了巨大成功,受到了广泛的关注,成为当今具有代表性的IT先进技术。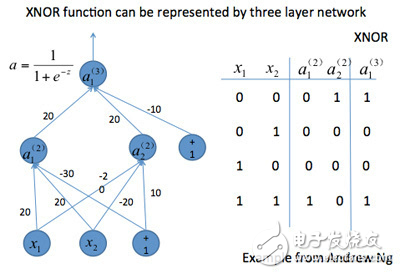
图1 从历史角度看深度学习与其他机器学习技术的关系
深度学习本质是复杂的非线性模型的学习,从机器学习的发展史来看,深度学习的兴起代表着机器学习技术的自然演进。1957年,Rosenblatt提出了感知机模型(Perceptron),是线性模型,可以看作是两层的神经网络;1986年,Rumelhart等开发了后向传播算法(Back Propagation),用于三层的神经网络,代表着简单的非线性模型;1995年,Vapnik等发明了支持向量机(Support Vector Machines),RBF核支持向量机等价于三层的神经网络,也是一种简单的非线性模型。2006年以后的深度学习实际使用多于三层的神经网络,又被称为深度神经网络,是复杂的非线性模型(见图1)。深度神经网络还有若干个变种,如卷积神经网络(Convolutional Neural Network)、循环神经网络(Recurrent Neural Network)。
本文首先回答关于深度学习的几个常见问题,介绍深度学习研究的最新进展,特别是一些代表性工作,同时概述我们的深度学习与自然语言处理的工作,最后总结深度学习的未来发展趋势。
关于深度学习的几个常见问题
这里尝试回答三个关于深度学习的常见问题。深度学习为什么很强大?深度学习是否是万能的?深度学习与人的大脑有什么关系?
深度学习为什么很强大?深度神经网络实际是复杂的非线性模型,拥有复杂的结构和大量的参数,有非常强的表示能力,特别适合于复杂的模式识别问题。
图2所示是一个简单的神经网络的例子,可以表示布尔函数XNOR,这个模型可以做简单的非线性分类。这是说明三层神经网络拥有非线性分类能力的著名例子。一般地,随着神经网络的层数增大,神经元数增大,其处理复杂的非线性问题的能力也随之增大。
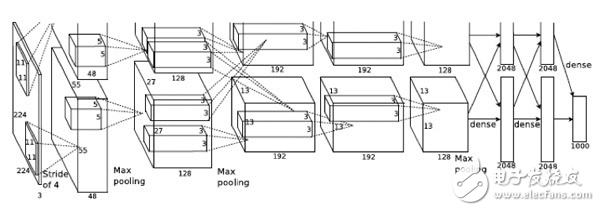
图2 XNOR神经网络
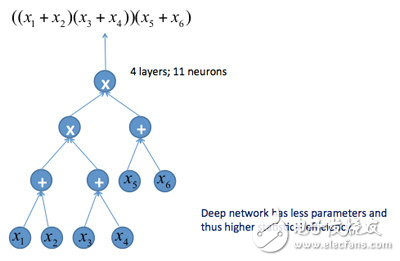
图3 被称为Alex Net的神经网络
图3所示的是被称为Alex Net的神经网络[2],是一个卷积神经网络,有11层,65万个神经元,6千万个参数。这个模型在2012年的ImageNet比赛中取得了第一名的好成绩,前五准确率是85%,远远高出第二名。这也是证明深度学习非常有效的著名实例。该任务是将120万张图片分到1千个类别中,对人也有一定的挑战,可以看出深度神经网络能实现很强的图片检测能力。
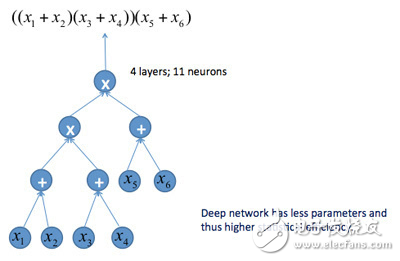
图4 和-积神经网络
深度学习的特点是深层的神经网络学习,网络层数多,有着本质重要的意义,体现在有更好的统计效率(statistical efficiency)上。
图4所示的是一个4层的和-积神经网络,神经元表示逻辑和、或者逻辑积,整个网络对应着一个逻辑表示式。可以把这个神经网络“压扁”,成为3层的神经网络,相当于把逻辑表达式展开。两个神经网络的表达能力是等价的,但浅层神经网络有更多的神经元,更多的参数。我们知道参数多的模型通常需要更多的数据训练。所以,深层神经网络只需要更少的数据就可以训练好,也就是说,有更好的统计效率。注意,当把深层神经网络压扁的时候,得到的浅层神经网络的参数个数是指数性增加的,虽然表示能力相同,但现实中是不可能学到的。这个结论对一般的神经网络也适用。
非常有趣的是,人的大脑也拥有多层的串联结构(cascaded structure),也就是深层神经网络结构。从Hubel和Wiesel的、以及之后的神经科学研究结果可以看出,人之所以能够做复杂的信息处理,与这种结构有很大关系。
深度学习是否是万能的?深度学习不是万能的。首先,深度学习不适合所有问题。如果问题简单,比如线性问题和简单的非线性问题,深度学习至多是与支持向量机等有同等的准确率。如果学习陷入局部最优,可能还不如其他方法。本质上这相当于杀鸡用牛刀。
另外,如果训练数据量不够大,深度神经网络不能得到充分学习,效果也不会很好。这时深度学习这匹“千里马”,也只能是“虽有千里之能,食不饱,力不足,才美不外见”。
再有,理论上深度学习也不是万能的。著名的“没有免费的午餐”定理说明了这一点。该定理指出,针对任意两个机器学习方法:方法一和方法二,如果存在一个问题,方法一比方法二学到的模型预测精度高,那么一定存在另一个问题,方法二比方法一学到的模型预测精度高。这个定理实际在说,没有任何一个方法可以包打天下。注意这里只保证后种情况是存在的,并没有涉及其可能性有更大。所以,在平均意义下学习方法的优劣还是有的,至少经验性上是这样。
这个定理的一个推论就是,深度学习不是万能的,至少理论上存在一些问题,其他方法比深度学习能做得更好,尽管有时可能碰到这种情况的概率不高。
深度学习与人的大脑有什么关系?历史上,人工神经网络的发明,在一定程度上受到了人脑信息处理机制的启发。但是,人工神经网络,包括深度神经网络,本质上还是机器学习模型。
首先,我们对人脑的了解还非常有限。撇开物质层面上的不同(人脑是生物系统,计算机是电子系统),把两者都当作信息处理系统(比如,诺依曼就把计算机和人脑都看作是不同的automata——自动机),我们仍能看到它们之间的许多相同点和不同点。
相同点如下。人工神经网络中的节点和链接,对应着人脑的神经元(neuron)和突触(synapse),有时我们直接把它们叫作神经元和突触。人工神经网络的架构,比如,卷积神经网络的架构借鉴了人脑的信息处理机制,包括串联结构(cascaded structure),局部感受野(local receptive field)。人工神经网络中,模拟信号和数字信号交互出现(如XNOR网络),这与人脑的神经网络有相似之处。
不同点也很明显。人工神经网络的学习算法通常是后向转播算法,是一个减少训练误差驱动的,需要多次迭代的,网络参数学习的优化算法,这与人脑的学习机制可能有本质的不同。深度神经网络本质是数学模型,比如,卷积神经网络采用卷积(convolution)与最大池化(max pooling)操作,以达到进行图像识别时不受图片的平移与旋转的影响的效果,这些操作本质是数学函数,与人脑的处理有什么关系并不清楚。最重要的是,深度学习的目的是在具体任务上提升预测准确率,不是模拟人脑的功能。
深度学习的最新进展
深度学习是2006年诞生的,但是其真正的兴起,或者说重大影响工作的出现,是在2012年之后,比如,Krizhevsky等用深度学习大幅度提高了图片分类的准确率,也就是Alex Net的工作[2];Dahl等大幅度提升了语音识别的准确率[3]。
以上的深度学习工作代表着强大的分类和回归模型的学习和使用,可以认为是传统的支持向量机的发展和提升。下面介绍四个深度学习的工作,从概念上有了重要的创新。
通常的深度学习方法都是监督学习,Le等提出了一个非监督的深度学习方法[4],可以从大量未标注图片数据中,学习到识别图片中概念的神经元,比如,能检测到猫的概念的神经元。整个神经网络有9层,重复三次同样的处理,每次处理包含过滤、池化、规一化操作,由3层神经网络实现。学习是通过自动编码与解码实现,通过这个过程,自动学习到数据中存在的模型(概念)。这个工作的另一个特点是大规模并行化。神经网络模型有100亿个参数,用1000万张图片在1000台机器上训练三天得到。监督学习需要使用标注数据,往往成本很高,有时很难得到大量训练数据;另一方面人的学习有很多是非监督的。所以,这个工作让人们看到了深度学习未来发展的一个新方向。
Mnih等将深度学习技术用到了强化学习[5]。强化学习适合于主体在与环境进行交互的过程中自动学习选择最佳策略、采取最佳行动的问题。Mnih等利用强化学习构建了一个系统,可以自动学习打电脑游戏,而强化学习的核心由深度学习实现。在Atari游戏机上,这个系统可以比人类的玩家学得更快,打得更好。具体地、强化学习是Q-learning,其中Q函数由一个卷积神经网络表示,状态表示电脑游戏的画面等环境,动作是游戏的操作,奖励是游戏的分数。这里的核心思想是用参数化的神经网络来表示Q函数,比起传统的用线性模型的方法,准确率由大幅度提高。这个工作将深度学习的应用扩展出一个新的领域。
另一个工作是Graves等提出的神经图灵机(Neural Turing Machine,NTM)[6],一种新的基于深度学习的计算机架构。深度学习通常用在预测、分析问题上,这里作者提出将它用到计算机的控制上。计算机的一个重要功能是在外部记忆(external memory)上进行读写操作,从而拥有极大的信息处理能力。NTM这种计算机,也使用外部记忆,其特点是假设外部记忆的控制器是基于多层神经网络的,这样在外部记忆上的读写,就不是确定性的,而是依赖输入输出,非确定性的。Graves等证明NTM可以从数据中学习到外部记忆控制,执行“复制”、“排序”等操作。将深度学习用于计算机的存储控制,确有让人耳目一新的感觉。
Weston等人提出了记忆网络(Memory Network,MemNN)模型,可以做简单的问答,如图5所示[7]。虽然在回答需要相对复杂推理的问题时MemNN的精度还不理想,但是这个工作让深度学习技术延伸到问答、推理等传统人工智能的问题上,受到广泛关注。MemNN模型的特点如下,有一个长期记忆(Long Term Memory),可以存储一系列中间语义表示,给定输入的一句话,系统将其转换为中间表示,更新长期记忆的状态(如加入新的中间表示),产生一个新的表示,最后产生输出的一个回答。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%