语音识别系统最新实践
语音作为最自然便捷的交流方式,一直是人机通信和交互最重要的研究领域之一。自动语音识别(Automatic Speech Recognition,ASR)是实现人机交互尤为关键的技术,其所要解决的问题是让计算机能够“听懂”人类的语音,将语音中传化为文本。自动语音识别技术经过几十年的发展已经取得了显著的成效。近年来,越来越多的语音识别智能软件和应用走人了大家的日常生活,苹果的Siri、微软的小娜、科大讯飞的语音输入法和灵犀等都是其中的典型代表。本文将以科大讯飞的视角介绍语音识别的发展历程和最新技术进展。
我们首先简要回顾语音识别的发展历史,然后介绍目前主流的基于深度神经网路的语音识别系统,最后重点介绍科大讯飞语音识别系统的最新进展。
1
语音识别关键突破回顾
语音识别的研究起源于上世纪50年代,当时的主要研究者是贝尔实验室。早期的语音识别系统是简单的孤立词识别系统,例如1952年贝尔实验室实现了十个英文数字识别系统。从上世纪60年代开始,CMU的Reddy开始进行连续语音识别的开创性工作。但是这期间语音识别的技术进展非常缓慢,以至于1969年贝尔实验室的约翰·皮尔斯(John Pierce)在一封公开信中将语音识别比作“将水转化为汽油、从海里提取金子、治疗癌症”等几乎不可能实现的事情。上世纪70年代,计算机性能的大幅度提升,以及模式识别基础研究的发展,例如码本生成算法(LBG)和线性预测编码(LPC)的出现,促进了语音识别的发展。这个时期美国国防部高级研究计划署(DARPA)介入语音领域,设立了语音理解研究计划,研究计划包括BBN、CMU、SRI、IBM等众多顶尖的研究机构。IBM、贝尔实验室相继推出了实时的PC端孤立词识别系统。上世纪80年代是语音识别快速发展的时期,其中两个关键技术是隐马尔科夫模型(HMM)的理论和应用趋于完善以及NGram语言模型的应用。此时语音识别开始从孤立词识别系统向大词汇量连续语音识别系统发展。例如,李开复研发的SPHINX系统,是基于统计学原理开发的第一个“非特定人连续语音识别系统”。其核心框架就是用隐马尔科模型对语音的时序进行建模,而用高斯混合模型(GMM)对语音的观察概率进行建模。基于GMM-HMM的语音识别框架在此后很长一段时间内一直是语音识别系统的主导框架。上世纪90年代是语音识别基本成熟的时期,主要进展是语音识别声学模型的区分性训练准则和模型自适应方法的提出。这个时期剑桥语音识别组推出的HTK工具包对于促进语音识别的发展起到了很大的推动作用。此后语音识别发展很缓慢,主流的框架GMM-HMM趋于稳定,但是识别效果离实用化还相差甚远,语音识别的研究陷入了瓶颈。
关键突破起始于2006年。这一年辛顿(Hinton)提出深度置信网络(DBN),促使了深度神经网络(Deep Neural Network,DNN)研究的复苏,掀起了深度学习的热潮。2009年,辛顿以及他的学生默罕默德(D. Mohamed)将深度神经网络应用于语音的声学建模,在小词汇量连续语音识别数据库TIMIT上获得成功。2011年,微软研究院俞栋、邓力等发表深度神经网络在语音识别上的应用文章,在大词汇量连续语音识别任务上获得突破。从此基于GMM-HMM的语音识别框架被打破,大量研究人员开始转向基于DNN-HMM的语音识别系统的研究。
2
基于深度神经网络的语音识别系统
基于深度神经网络的语音识别系统主要采用如图1所示的框架。相比传统的基于GMM-HMM的语音识别系统,其最大的改变是采用深度神经网络替换GMM模型对语音的观察概率进行建模。最初主流的深度神经网络是最简单的前馈型深度神经网络(Feedforward Deep Neural Network,FDNN)。DNN相比GMM的优势在于:1. 使用DNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;2. DNN的输入特征可以是多种特征的融合,包括离散或者连续的;3. DNN可以利用相邻的语音帧所包含的结构信息。
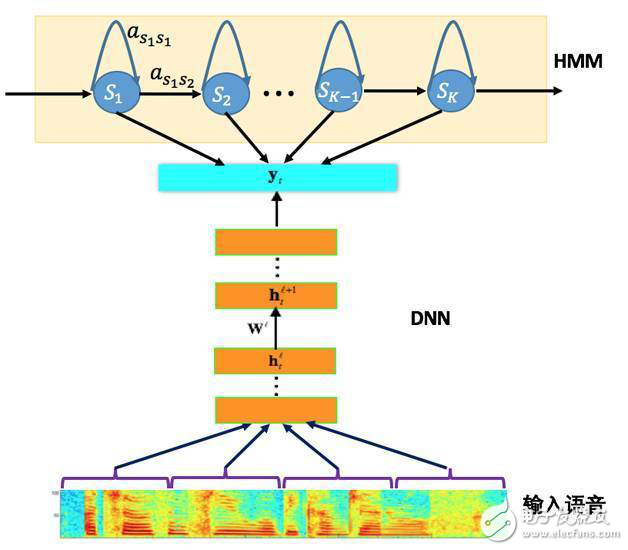
图1 基于深度神经网络的语音识别系统框架
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
语音识别系统最新实践下载
相关电子资料下载
- 讯飞星火大模型V3.0正式发布,全面对标ChatGPT 299
- 今日看点丨富士康被查 立讯精密、和硕有望迎转单; 科大讯飞:华为昇腾 910B 661
- 黄仁勋点名华为!科大讯飞:华为昇腾910B可对标英伟达A100 846
- 科大讯飞首次亮相迪拜GITEX Global 2023,探索科技创新未来! 259
- 华为全联接大会2023|科大讯飞与华为共启双子星计划,开创AI大模型高性能网络 548
- 语音识别系统的基本结构及分类介绍 99
- 科大讯飞获国际多通道语音分离与识别大赛CHiME-7冠军 805
- 今日看点丨传日本更可能实施对光刻/薄膜沉积设备的出口管制;科大讯飞刘庆 460
- 科大讯飞刘庆峰:任正非派三个联席主席来做专班工作,华为GPU已可对标A100 317
- 科大讯飞、华为强强联合:攻关算力卡脖子问题 1001