从学习方式和功能角度等方面对算法的分类介绍
在本文中,我将提供两种分类机器学习算法的方法。一是根据学习方式分类,二是根据类似的形式或功能分类。这两种方法都很有用,不过,本文将侧重后者,也就是根据类似的形式或功能分类。在阅读完本文以后,你将会对监督学习中最受欢迎的机器学习算法,以及它们彼此之间的关系有一个比较深刻的了解。
事先说明一点,我没有涵盖机器学习特殊子领域的算法,比如计算智能(进化算法等)、计算机视觉(CV)、自然语言处理(NLP)、推荐系统、强化学习和图模型。
下面是一张算法思维导图。
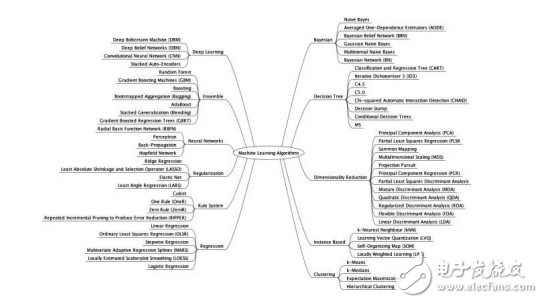
从学习方式分类
算法对一个问题建模的方式很多,可以基于经历、环境,或者任何我们称之为输入数据的东西。机器学习和人工智能的教科书通常会让你首先考虑算法能够采用什么方式学习。实际上,算法能够采取的学习方式或者说学习模型只有几种,下面我会一一说明。对机器学习算法进行分类是很有必要的事情,因为这迫使你思考输入数据的作用以及模型准备过程,从而选择一个最适用于你手头问题的算法。
监督学习
输入数据被称为训练数据,并且每一个都带有标签,比如“广告/非广告”,或者当时的股票价格。通过训练过程建模,模型需要做出预测,如果预测出错会被修正。直到模型输出准确的结果,训练过程会一直持续。常用于解决的问题有分类和回归。常用的算法包括逻辑回归和BP神经网络。
无监督学习
输入数据没有标签,输出没有标准答案,就是一系列的样本。无监督学习通过推断输入数据中的结构建模。这可能是提取一般规律,可以是通过数学处理系统地减少冗余,或者根据相似性组织数据。常用于解决的问题有聚类、降维和关联规则的学习。常用的算法包括 Apriori 算法和 K 均值算法。
半监督学习
半监督学习的输入数据包含带标签和不带标签的样本。半监督学习的情形是,有一个预期中的预测,但模型必须通过学习结构整理数据从而做出预测。常用于解决的问题是分类和回归。常用的算法是所有对无标签数据建模进行预测的算法(即无监督学习)的延伸。
从功能角度分类
研究人员常常通过功能相似对算法进行分类。例如,基于树的方法和基于神经网络的方法。这种方法也是我个人认为最有用的分类方法。不过,这种方法也并非完美,比如学习矢量量化(LVQ),就既可以被归为神经网络方法,也可以被归为基于实例的方法。此外,像回归和聚类,就既可以形容算法,也可以指代问题。
为了避免重复,本文将只在最适合的地方列举一次。下面的算法和分类都不齐备,但有助于你了解整个领域大概。(说明:用于分类和回归的算法带有很大的个人主观倾向;欢迎补充我遗漏的条目。)
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%