TensorFlow数据读取机制分析
大小:0.9 MB 人气: 2017-09-28 需要积分:3
TensorFlow读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
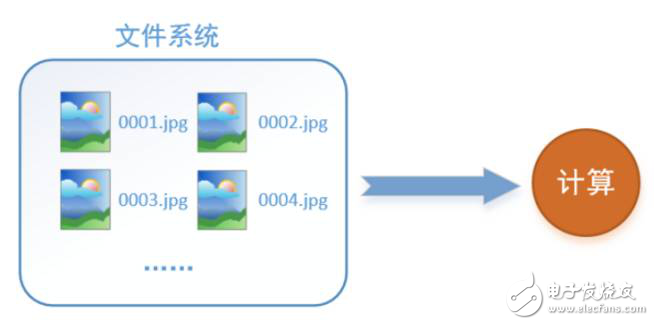
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
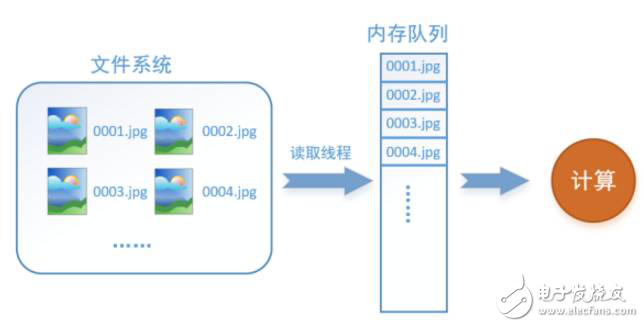
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在TensorFlow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
TensorFlow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
TensorFlow数据读取机制分析下载
相关电子资料下载
- 【风火轮YY3568开发板免费体验】第六章:在Solus上运行自定义模型并迁移到YY3 411
- 深度学习框架tensorflow介绍 480
- 深度学习框架pytorch介绍 454
- 【米尔MYC-JX8MPQ评测】+ 运行 TensorFlow Lite(CPU和NPU对比) 524
- 手把手带你玩转—i.MX8MP开发板移植官方NPU TensorFlow例程 444
- 在树莓派64位上安装TensorFlow 505
- TensorFlow Lite for MCUs - 网络边缘的人工智能 339
- 2023年使用树莓派和替代品进行深度学习 1506
- 用TensorFlow2.0框架实现BP网络 1849
- 那些年在pytorch上踩过的坑 571