数据仓储,数据仓储是什么意思
数据仓储,数据仓储是什么意思
各个组织每天都要捕获一些基本不可使用的数据,原因是无法很方便地访问、操作和呈现这些数据。在一个组织的各计算机系统上,有数十亿字节的数据基本上是“锁定”的。数据仓储技术定义了可以使该数据更容易访问的策略。
业内分析人士和系统供应商长久以来已经认识到有两种类型的信息系统:
作业系统 作业系统是指组织内将输入转换成输出而创造价值的系统。它接受输入,即:人、设备和材料,然后将其转换成能满足需要的商品或服务。这些系统用来处理日常的经营活动,如记帐、订单输入和库存管理等。这些系统维持企业运行。
信息系统 信息系统是以提供信息服务为主要目的的数据密集型、人机交互的计算机应用系统。人们使用这些系统来分析数据、作出企业管理决策和规划未来发展。这些系统通常是指“经理管理系统”。
这两个系统之间的重要差别在于,作业系统处理一组特定的数据(如库存),而信息系统则要涉及到从多种多样的相关信息源中提取有用的信息。信息系统从以下信息源访问和使用数据:
遗留数据系统 一个组织经过多年的收集而获得的数据的仓库。这些系统包括较早的大型机或小型计算机系统,这些系统运行的特定应用程序已经不容易从较先进的基于PC的应用程序中来访问了。
外部数据系统 这些系统位于组织外部,如Web服务器或订阅数据业务,它们提供了广泛的信息(如人口统计数据、经济趋势数据、产品数据等)。
作业数据系统 如前所述,作业数据是指由记帐和其他企业系统收集和生成的日常数据。
数据仓库可以视为一个三部分系统,其中,中间系统向终端用户安全地提供可用的数据。在中间系统的一侧是终端用户,一侧是后端数据存储区。数据仓库通常由以下几部分组成,如图D-12所示。
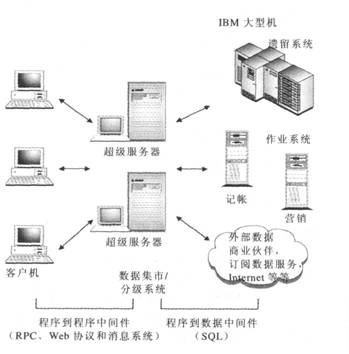 图D-12 数据仓库结构分级系统/数据集市 从后端系统中选择的数据即存储在此,以供客户机访问。通常要以多种方式对数据进行清理和处理才能对其进行访问,这在后面将进行探讨。数据仓库可以包含多个数据集市,每个数据集市对应于公司的一个部门。尽管数据集市可存储从数据仓库提取的信息,但数据仓库常常是分阶段建立的,首先建立部门数据集市,然后将各个数据集市合并起来。
图D-12 数据仓库结构分级系统/数据集市 从后端系统中选择的数据即存储在此,以供客户机访问。通常要以多种方式对数据进行清理和处理才能对其进行访问,这在后面将进行探讨。数据仓库可以包含多个数据集市,每个数据集市对应于公司的一个部门。尽管数据集市可存储从数据仓库提取的信息,但数据仓库常常是分阶段建立的,首先建立部门数据集市,然后将各个数据集市合并起来。
前端客户机 这些客户机是指使用基于PC的应用程序访问数据以供分析的终端用户。
中间件 中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。中间件位于客户机/ 服务器的操作系统之上,管理计算资源和网络通讯。是连接两个独立应用程序或独立系统的软件。中间件可隐藏不同数据管理系统之间的差别,并使客户机可以容易地访问这些系统。执行中间件的一个关键途径是信息传递。通过中间件,应用程序可以工作于多平台或OS环境。
消息系统 数据仓库通常包含多个后端系统和多个客户机。一个消息系统就是一个传递系统,用来在整个数据仓库中传输请求和响应消息系统使用基础网络协议和设备传递信息。
元数据 元数据是描述数据仓库内数据的结构和建立方法的数据,这一点与图书馆的目录卡片包含图书相关的信息很类似。可将其按用途的不同分为两类,技术元数据和商业元数据。
从图D-12中可以看出,客户机可以访问存储在数据集市中的数据,尽管也可以直接访问遗留系统、作业系统或外部系统。但这种分级的方法有许多优点,其中包括安全性以及客户机对数据分析人员或数据管理员严格控制的数据的访问权。
关于数据仓库中的信息
数据仓库可以视为一个系统,该系统保存有来自遗留、作业或外部数据源的汇总信息。分级系统只存储最新的信息,仅供只读使用。所有数据更新均在作业系统上进行,而不在分级系统上进行。根据Prism Solutions(现在称为Informix),在数据仓库中有不同级别的汇总和细节,如图D-13所示。下面进行解释:
图D-13 数据仓储中的数据结构(经Prism Solutions许可)
较早的细节数据是指历史数据或遗留数据。
当前细节数据(通常为作业数据)是指最新的数据,该数据容量非常大,因此需要进行广泛的汇总以使其易于访问。
轻度汇总的数据是指数据库分析人员或其他一些进程已经从当前细节数据中提取出来的数据。
高度汇总的数据是指压缩数据,特定部门的终端用户可以容易地对该数据进行访问。
可以想象,存储在遗留、作业或外部系统中的数据用多种不同的方式编码、构造和存储,并且数据库设计人员多年来使用他们自己的惯例来建立数据库结构。因此,信息在一个数据库中存储的方式与相关信息在其他数据库中存储的方式大相径庭。
将数据传输到分级系统后,它必须由数据库分析人员或专为该任务设计的应用程序进行“预处理”。处理过程包括提取、清理、合并、更改和操作数据,从而将数据转变为与终端用户关系更大的新的数据集。也可以包括广泛的完整性检查,以确保终端用户可以访问到准确而及时的数据。
这一过程的主要特征是使用通用的命名惯例和一致的属性、编码和结构来集成数据,例如,来自不同数据库的日期信息的格式可能多种多样(如Julian、yymmdd、mmddyy等),但可以在分级系统上仅以Julian格式重新设置格式和存储。
如前所述,公司每个部门可以拥有自己的分级系统用于轻度或高度汇总的数据。数据库分析人员通常负责从后端系统上对数据进行汇总和提取,并使其可由终端用户访问。D2K,Inc.将这些分析人员称为“农场主”,因为他们的工作就是提取存储在“服务器场”上的数据。数据农场主可以使用OLAP(联机分析处理)和“数据开采”工具,这些工具可以帮助他们将信息关联在一起,并在数据中发现有趣和有意义的关系。OLAP所提供的数据格式是多维“立方体”,而不是比较传统的表格形式。
支持数据仓储概念的新软件可用来替代EIS(执行信息系统)和DSS(决策支持系统)。数据仓库中发生的数据不断更新并不会使这些早期的系统受益,并且这些系统仅限于少数决策者使用。
IDWA(国际数据仓储协会)确定了一种数据仓库类型,并将其称为“作业数据仓库”。该仓库可提供在前端系统已经鉴别的后端数据进行动态访问。它用银行作为例子来说明这一点。该银行被要求来鉴定某家公司的所有资产,银行要从多个不同的系统上提取相关的数据,然后法院传令冻结所有帐号。如果所有这些帐号都存储在多个不同的遗留系统上,则会引发一个问题。银行雇员需要分别关闭每个帐号。如果使用作业数据仓库,则所有帐号可以使用同一种软件来关闭,该软件原本用于提取帐户信息。
构建数据仓库的目的
(1)市场的激烈竞争和管理过程的复杂性,决定了一个企业为了生存与发展,就需要对客户关系、市场营销、产品工程、投资分析等方面的历史数据进行提取与分析,从中找到对企业进一步发展有价值的潜在信息。
(2)数据仓库能够把企业的内部数据和外部数据进行有效的集成,为企业的各层决策提供数据依据。
(3)企业现有的系统不能提供更多的决策信息(尽管企业已经有了大量的数据积累)。
(4)通过构造一种体系化的数据存贮环境,将分析决策所需的大量数据从传统的操作环境中分离出来,使分散的、不一致的操作数据转换成集成的、统一的信息。
(5)可以为市场营销和客户分析提供基本的信息源和辅助工具。
(6)可以实现对产品、部门、机构的利润与成本分析。
(7)可以规范管理流程、优化业务处理、提高资本利用率。
规划和构建数据仓库
数据仓库的构架由三部分组成:数据源、数据源转换/装载形成新数据库、OLAP(联机分析处理 On-line Analytical Processing)。
决定构建数据仓库的组织面对着一个重要任务,就是如何生成用户可以使用的及时、准确和有用的信息。为构建数据仓库,曾经有许多被误导的尝试,最终所提供的信息都不准确或不完整。而且常常是除了构建数据仓库之外别无其他选择。另一种方法是将有价值的数据仍锁定在遗留系统中。
曾经有一个公司构建了七个数据仓库,前六次尝试均以失败告终,成为学习经验。
数据仓库的实施过程大体可分为三个阶段:数据仓库的项目规划、设计和实施、维护调整。
构建数据仓库一开始应仔细规划策略并建立原型。在购买昂贵的硬件之前,开发人员应与用户紧密合作,以便准确确定分级系统上需要什么信息以及将如何使用这些信息。完成这一任务的通常做法是构建一些小型系统,然后由这些小型系统扩展成为完整的生产系统。
供应商们已经开发出一些特殊的系统用于数据仓储。IBM拥有它自己的“信息仓库”系统。并行数据库系统正在出现,可以改善对数据库系统的访问。新的数据可视化工具已经开发出专门用于这一目的的并行处理系统。
Web接口可能是数据仓储中新的最重要的方面。许多供应商(包括D2K, Inc.)正在开发一些应用程序,用来将存储在仓库中的数据传输到Web浏览器上。“推送”技术用于自动为订阅的用户提供他们所感兴趣的最新数据视图。利用Web技术,只需设置数据格式以便在Web浏览器上显示即可。然后,任何系统上的用户就可以使用任何Web浏览器来显示该信息了。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
相关阅读:
- [电子说] IBM Security可落地经验助企业构筑现代化安全屏障 2023-10-24
- [电子说] DLT698转modbus协议网关把电能数据接到wincc的方法 2023-10-24
- [电子说] 自动化PLC控制柜如何进行监控管理?有什么应用场景 2023-10-24
- [电子说] 环旭电子推出Pisces企业级无线路由器助力企业应对高密度数据挑战 2023-10-24
- [电子说] 设备互联(IOT数据采集)平台有什么功能 2023-10-24
- [电子说] 物通博联工业采集网关实现水处理除臭设备运行状态监控 2023-10-24
- [电子说] Andes旗下高性能多核矢量处理器IP的AX45MPV正式上市 2023-10-24
- [电子说] 工业物联网解决方案:卷绕机数据采集管理系统 2023-10-24
( 发表人:admin )